UD 4 - Apache Hadoop - Cluster¶
En este recurso vamos a explicar como se instala y configura un cluster con Apache Hadoop
1. Pre-requisitos¶
Debemos tener instalado VirtualBox.
1.1 Configurar Red NAT¶
Para crear nuestro cluster, vamos a configurar un red NAT para que los nodos tenga conexión entre ellos y salida a Internet a través del Host
Success
Hemos elegido esta configuración de red por varios motivos.
-
Puedas usar tu cluster en tu portátil independientemente de la red o lugar en la que estés conectado
-
Sería más sencillo hacerla en modo bridge, pero no tenemos IPs suficientes debido al alto número de alumnado, y habría que configurar las IPs cada vez que te conectes a una red distinta a la de clase.
-
En todo caso, si decides optar por esta opción, sólo tienes que adaptar los pasos a tu configuración de red. Sería algo más sencilla.
Para ello, explicamos con una imagen como funciona VirtualBox en este tipo de configuración de red
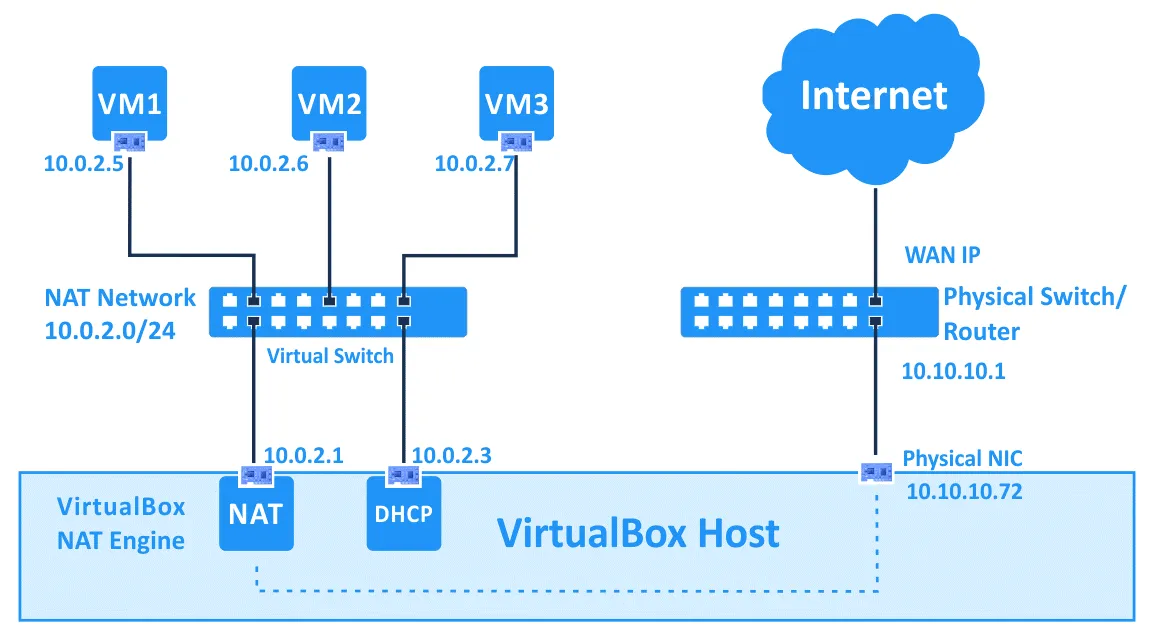
Puedes observar que podemos configurar nuestra propia subred, dentro de las cuales, hay 2 ips que VirtualBox asigna estáticas dentro de la red: la puerta de enlace (primera de la red) y el DHCP (tercera de la red). Para más información, consulta la documentación oficial de VirtualBox
Teniendo en cuenta esto, vamos a configurar nuestra propia subred, que será la 192.168.11.0/24
-
Abrimos la configuración de VirtualBox para crear una nueva red NAT en
Archivo -> Herramientas -> Redes -> Redes NAT -> Red -> Crear Red -
Creamos una nueva Red NAT llamada
BDA. Usaremos la red192.168.11.0/24con DHCP Deshabilitado. Puedes elegir cualquier otra si quieres.
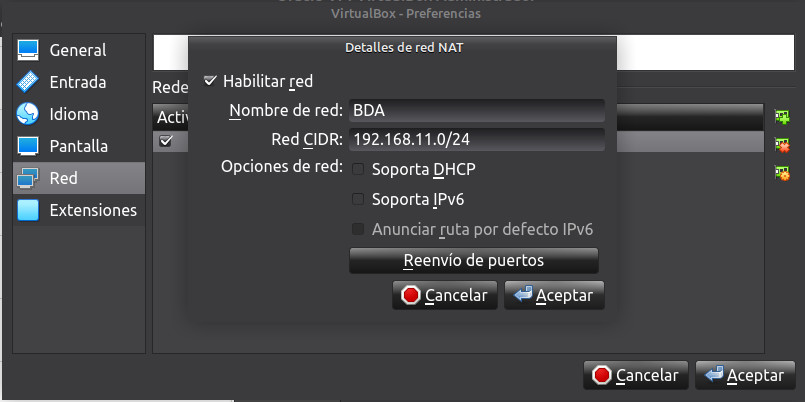
- Una vez configurada la Red NAT, podemos empezar a instalar y configurar el cluster.
1.2 Configuración de las máquinas¶
Vamos a crear una primera máquina que después clonaremos y cambiaremos las configuraciones necesarias. Las máquinas tendrán la siguiente configuración (siempre que sea posible):
- Nombre: master (las otras 3 máquinas se llamarán nodo1, nodo2 y nodo3)
- RAM: 4GB (yo por ejemplo, no puedo darle más de 3GB)
- Núcleos: 2
- Disco duro: 50GB
- Interfaz de red: Red NAT ("BDA"): 192.168.11.10 (las s de las otras 3 máquinas serán 192.168.11.11, 192.168.11.12 y 192.168.11.13)
- Sistema operativo: Ubuntu server 24.04
- Usuario: hadoop
1.3 Configuración de red¶
Habiendo entendido correctamente lo explicado en los puntos anteriores,podemos configurar la interfaz de red de forma manual, con la siguiente configuración:
- Subred:
192.168.11.0/24 - Direción Ip:
192.168.11.10 - Puerta de enlace:
192.168.11.1 - DNS:
8.8.8.8,1.1.1.1
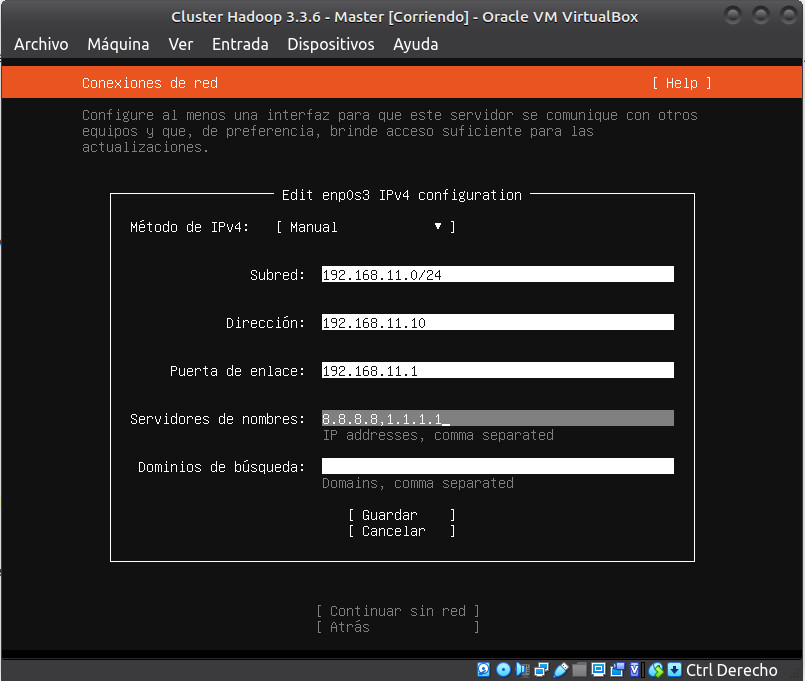
1.4 Acceso a las máquinas. Configurar Adaptador sólo Anfitrión¶
Para un manejo más cómodo e intuitivo de las máquinas, podemos preparar cada nodo para que sea accesible desde nuestro anfitrión y conectarnos mediante ssh a cada una de las máquinas.
Para ello debemos añadir otro interfaz de red en modo "Adaptador sólo anfitrión"
Hacemos lo mismo que en el punto anterior para la red NAT, pero esta vez elegimos "Adaptador sólo anfitrión" y elegimos la red que VirtualBox crea por defecto llamada vboxnet0. En mi caso usaré la configuración de red por defecto que VirtualBox crea para este adaptador, que es 192.168.56.0/24, dandole a mi anfitrión la ip 192.168.56.1.

Warning
Si tienes como anfitrión un equipo linux y NO PUEDES configurar un "adaptador sólo anfitrión" debes crearlo y levantarlo manualmente
Se creara una interfaz de red 192.168.56.0/24. Puedes cambiarla y configurarla también manualmente
Puedes crear todas las que quieras por este proceso. Si se actualiza el kernel de Linux o la versión de Virtualbox se debe repetir este proceso. Para mas información accede a la documentación oficial de VirtualBox
Ahora, una vez dentro de la máquina virtual, no olvides configurar la ip de esta subred.
- Abrimos el archivo
/etc/netplan/00-installer-config.yamlo/etc/netplan/50-cloud-init.yamly añadir la configuración. Por ejemplo, terminado en la misma ip que la Red NAT - Esta sería la configuración completa
network:
version: 2
ethernets:
enp0s3:
addresses:
- "192.168.11.10/24"
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
search: []
routes:
- to: "default"
via: "192.168.11.1"
enp0s8:
addresses:
- "192.168.56.10/24"
2. Nodo Master¶
Creamos en VirtualBox el nodo master configurando el Interfaz de red como Red NAT (opcionalmente otra interfaz red sólo anfitrión) y elegimos la que acabamos de crear BDA
2.1 Instalación¶
- Java™ debe ser instalado. Las versiones de Java recomendadas se encuentran descritas en HadoopJavaVersions.
- ssh debe estar instalado y sshd debe estar ejecutándose para usar las secuencias de comandos de Hadoop que administran los demonios ssh remotos de Hadoop, ya que vamos a usar las secuencias de comandos de inicio y detección opcionales. Si no lo has hecho durante la instalación, hazlo ahora.
- Para obtener la distribución de Apache Hadoop, descarga la versión estable más reciente desde Apache Download Mirrors
- Una vez descargado, desempaquetamos el archivo descargado con el comando tar y entra dentro de la carpeta:
- Edita el siguiente archivo
etc/hadoop/hadoop-env.shpara definir la variable de entorno de Java y añádela.
- Para poder usar los comandos de HDFS en cualquier lugar del sistema, sin tener que hacerlo desde el directorio de Hadoop (por ejemplo
/opt/hadoop-3.4.2/bin), creamos las variables de entorno y añadimos al PATH. Para ello abrimos el archivo~/.bashrcy añadimos al final el siguiente código y ejecuta el comandosource ~/.bashrc
export HADOOP_HOME=/opt/hadoop-3.4.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
- Ejecuta el siguiente comando. Si no da error, podemos continuar
Nos debe salir la versión de hadoop
Hadoop 3.4.2
Source code repository https://github.com/apache/hadoop.git -r 84e8b89ee2ebe6923691205b9e171badde7a495c
Compiled by ahmarsu on 2025-08-20T10:30Z
Compiled on platform linux-x86_64
Compiled with protoc 3.23.4
From source with checksum fa94c67d4b4be021b9e9515c9b0f7b6
This command was run using /opt/hadoop-3.4.2/share/hadoop/common/hadoop-common-3.4.2.jar
2.2 Configuración¶
Los archivos que vamos a revisar a continuación se encuentran dentro de la carpeta $HADOOP_HOME/etc/hadoop.
- El archivo que contiene la configuración general del clúster es el archivo
core-site.xml. En él se configura cual será el sistema de ficheros, que normalmente será hdfs, indicando el dominio del nodo que será el maestro de datos (namenode) de la arquitectura. Podéis sustituir el nombre del dominiobda-iesgrancapitanpor el que queráis. En mi caso seracluster-bda
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster-bda:9000</value>
</property>
</configuration>
- El siguiente paso es configurar el archivo
hdfs-site.xmldonde se indica tanto el factor de replica como la ruta donde se almacenan tanto los metadatos (namenode) como los datos en sí (datanode). Aquí puedes consultar todos los parámetros por defecto susceptibles de cambio se encuentran en este recurso
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/opt/hadoop/hadoop_data/hdfs/secondary_namenode</value>
</property>
</configuration>
- Crea los directorios de
hadoop-dataconfigurados anteriormente enhdfs-site.xmlpara cuando ejecutemos hadoop y configura los permisos oportunos.
sudo mkdir -p /opt/hadoop
sudo chown -R hadoop:hadoop /opt/hadoop
sudo chown -R hadoop:hadoop $HADOOP_HOME
- Configuramos MapReduce
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- Configuramos Yarn
Primero obtenemos la ruta correcta del classpath de Hadoop ejecutamos la siguiente instrucción
Y es esta salida la que tenemos que poner como valor de la propiedad. En mi caso:
/opt/hadoop-3.4.2/etc/hadoop:/opt/hadoop-3.4.2/share/hadoop/common/lib/*:/opt/hadoop-3.4.2/share/hadoop/common/*:/opt/hadoop-3.4.2/share/hadoop/hdfs:/opt/hadoop-3.4.2/share/hadoop/hdfs/lib/*:/opt/hadoop-3.4.2/share/hadoop/hdfs/*:/opt/hadoop-3.4.2/share/hadoop/mapreduce/*:/opt/hadoop-3.4.2/share/hadoop/yarn:/opt/hadoop-3.4.2/share/hadoop/yarn/lib/*:/opt/hadoop-3.4.2/share/hadoop/yarn/*
Por tanto la configuración final será
<configuration>
<property>
<name>yarn.webapp.ui2.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cluster-bda</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.4.2/etc/hadoop:/opt/hadoop-3.4.2/share/hadoop/common/lib/*:/opt/hadoop-3.4.2/share/hadoop/common/*:/opt/hadoop-3.4.2/share/hadoop/hdfs:/opt/hadoop-3.4.2/share/hadoop/hdfs/lib/*:/opt/hadoop-3.4.2/share/hadoop/hdfs/*:/opt/hadoop-3.4.2/share/hadoop/mapreduce/*:/opt/hadoop-3.4.2/share/hadoop/yarn:/opt/hadoop-3.4.2/share/hadoop/yarn/lib/*:/opt/hadoop-3.4.2/share/hadoop/yarn/*</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
</configuration>
- Añade a
/etc/hostsel nombre de tu dominio indicado encore-site.xmlpara que no te de error de resolución de nombres. Añade también las ips de los nodos (Recuerda comentar la 127.0.1.1 para evitar posibles loopback en las conexiones entre nodos). En mi caso quedaría:
127.0.0.1 localhost
#127.0.1.1 master
192.168.11.10 cluster-bda
192.168.11.10 master
192.168.11.11 nodo1
192.168.11.12 nodo2
192.168.11.13 nodo3
- Reiniciamos el servicio
- Generamos las claves ssh:
- Comprobamos que podemos acceder por ssh
- Configura el archivo
$HADOOP_HOME/etc/hadoop/workersque le indica a hadoop los nodos que van a actuar como workers.
2.3 Ejecución¶
- Ejecuta el siguiente comando
-
Comprobamos la correcta configuración
-
Iniciando el demonio Namenode y Datanode
- Iniciando Yarn
- Nos debe levantar el servicio correctamente, indicando que no puede conectarse a los nodos 1, 2 y 3, ya que todavía no los hemos creado.
nodo3: ssh: Could not resolve hostname nodo3: Temporary failure in name resolution
nodo2: ssh: Could not resolve hostname nodo2: Temporary failure in name resolution
nodo1: ssh: Could not resolve hostname nodo1: Temporary failure in name resolution
-
Accede desde el navegador del anfitrión con la ip configurada en la Interfaz de red solo anfitrión. En mi caso a
http://192.168.56.10:9870/para acceder al interfaz web de HDFS -
Accede también a la WebUI de Yarn
http://192.168.56.10:8088/ui2 -
Paramos hadoop
3. Nodos¶
3.1 Clonación de la máquina master¶
- Apagamos la máquina
master - Clonamos la máquina 3 veces para crear los 3 nodos del cluster. Recuerda cambiarle el nombre a cada uno de ellos (
nodo1,nodo2,nodo3) - A la hora de clonar, genera nuevas direcciones MAC para los interfaces de red
- Clonación completa
3.2 Configuración nodos¶
Tenemos que cambiar algunas configuraciones en nuestros nodos:
- El nombre del hostname
- Configuración de red
- Cambiamos el nombre del host:
- Reinicia tu shell actual, cargando el nuevo nombre de host en el prompt sin necesidad de abrir una nueva terminal y así comprobar que el cambio se realizó correctamente
-
Accedemos a la configuración de red a través de netplan en el fichero
/etc/netplan/50-cloud-init.yamly cambiamos la configuración de las 2 interfaces de red con las ips correspondientes -
Esta sería la configuración completa
network:
ethernets:
enp3s0:
addresses:
- 192.168.11.11/24
nameservers:
addresses: [8.8.8.8, 1.1.1.1]
routes:
- to: default
via: 192.168.11.1
enp8s0:
addresses:
- 192.168.56.11/24
version: 2
- Aplicamos la nueva configuración
ovsdb-server.service
Si al aplicar la nueva configuración de red te devuelve el siguiente error: "cannot call open vswitch: ovsdb-service.service is not running", realiza lo si siguiente:
- Instala el servicio:
- Inicia el servicio:
- Habilita el servicio:
- Elimina "cloud-init":
Ahora si podrás cambiar las IPs estáticas sin problemas.
- Reiniciamos
- Realizamos las mismas operaciones en el
nodo2ynodo3con sus correspondientes IPs
4. Cluster¶
4.1 Configuración ssh¶
Por último, nos queda crear las correspondientes claves ssh de los nodos para que exista una correcta comunicación entre todos los nodos del cluster.
-
Todos los nodos del cluster deben tener todas las claves públicas del resto de nodos, para su correcto funcionamiento. Por tanto, vamos a ir generando una por una en cada nodo del cluster y las vamos añadiendo a medida que recorremos el cluster. Finalmente, el fichero resultante en el último nodo del cluster contendrá todas las claves. Este deberá ser copiado en todos los nodos los cluster. Vamos a ver el paso a paso para entenderlo mejor.
-
Entramos en el
mastery generamos las claves ssh:
- La copiamos en el siguiente nodo. En nuestro caso
nodo1
- Accedemos al nodo
nodo1por ssh. Comonodo1ya conoce la clave de master, no nos pide contraseña. Así también vamos comprobando que la configuración es correcta en cada nodo.
- Generamos las claves ssh del
nodo1:
- Comprobamos que tenemos todas las claves generadas hasta ahora
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQC9sex3NSwFrtJoFDeNybRDATMvvb5CSyaAgXoNMFzHGmqh0vorJA5me/Pv4j/FxkO8YUm20T8hBEwOJXFFNeAXIqgktuaoaLLfq5bR+8ohKTptc0+aMh+AYrcJYLlVyiwkFFbqbm66nIrD+YQ8OgVYa4Si53pxQXGTFvZrrrVzfknU6IIyus37wCKIO8RJ8Xbr5Zw+gLGftD4TC5dPOaa80XgM1oyfUHEMEqPxjh4g0dntJKvyxp5nCgWgRSAJkMityq6VfMPLw+ghKitmnxa8b9rkaT8pI2vnyER9yDS6Cn/j0lsyx+jLxpyZAO1wWZgsK6pQ79KLWxpzPzqalTBgyK9ysg+3YHW8FNcCtDtdwh/+tcBsAfMrqYYvmPXX2zQIOc/2gC/Eu/bmnMrHAY97HuzRnTSB2No3roUt8wwMd7anwdOLxEp4+aDnt5pxpRwfYFdLlsqKO1uIkAYHZ/sXCD12x0S0nSjPNl4ijGKsBb50RKIKJLf4joekBMcP/gc= hadoop@master
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDG7HZJjSsWHk7DIR052kMlw65uCfK3CKHaLyeqElE6vsxtttbF/GpqIL0b/AlcqxGKHswJ01ZJDcW98nus5anj7wGe3rgrC2EkRaZ+Lf/DKmV1IOpSqY4bs3suh2YbObYQsihRWPI9n5zZ+MIARHbLTr/EIH26WRfqRvMMYYEJmgnXPSdh47iurDVit8wKjBaIuZOUI0hxk1ZOYLC2Fv2G+IQ/Ntp8v2MrrFI1zgVAj9+0YOid4yAKc6lJk6nffgVJMhN9aeSpagdG2HicjstOPuOw+NrrcJ1f6SRcF3mqxEZbgmMfdWupuHLhULj3nebkhGpeAxksyiythH7M3RzPYKm7M9ea2SIM1RQ3DZMQeH40qX1Zl7+yjdnhVMurtD3m4ujwssDw+y05/pt216J/MNhzdxZiPkvq2u+lvVrFTi1iaAu3XKzHGOuCndsK4tVFEZuc7RdAhj38Ph7G7V41wC2aNJ8Fprx0acjaUHk4DlXAH/MjJUvQ7pD7zdivk8c= hadoop@nodo1
- La copiamos en el siguiente nodo. En nuestro caso
nodo2
- Accedemos al nodo
node2por ssh.
- Generamos las claves ssh del
nodo2:
- Comprobamos que tenemos todas las claves generadas hasta ahora
- La copiamos en el siguiente nodo. En nuestro caso
nodo3
- Accedemos al nodo
nodo3por ssh.
- Generamos las claves ssh del
nodo3:
- Comprobamos que tenemos todas las claves generadas hasta ahora
- Una vez terminado todo nuestro cluster, la copiamos en todos los nodos.
scp ~/.ssh/authorized_keys hadoop@nodo2:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@nodo1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@master:~/.ssh/authorized_keys
- Por último, entramos a cada uno de los nodos y cambiamos los permisos de
~/.ssh/authorized_keys. Podemos ir cerrando las conexiones ssh y mientras volvemos a master, vamos pasando por cada nodo y cambiando los permisos de cada máquina
- Cerramos todas las conexiones ssh
4.2 Preparando los nodos del cluster¶
-
Ahora nos queda hacer una correcta gestión de las carpetas de namenode y datanode. Recuerda que los archivos de datanode deben estar en los workers
-
Por tanto, en cada uno de los nodos workers(
nodo1,nodo2,nodo3), borramos la carpetanamenodeysecondary_namenode, además del interior de la carpetadatanode, donde tenemos el directoriocurrent
sudo rm -rf /opt/hadoop/hadoop_data/hdfs/namenode
sudo rm -rf /opt/hadoop/hadoop_data/hdfs/secondary_namenode
sudo rm -rf /opt/hadoop/hadoop_data/hdfs/datanode/current
- Siguiendo la lógica, en el nodo
mastereliminamos el directoriodatanode
- Desde el nodo
master, damos de nuevo formato a HDFS
4.3 Levantamos el cluster¶
- Iniciando el demonio Namenode y Datanode
- Vemos como arranca
namenodeysecondarynamenodeen el nodo master y el datanode
- Iniciamos Yarn
- Se inician el
resourcemanagery elnodemanagers
- Arrancamos también el servidor de historial de trabajos (JobHistory Server) en un clúster de Hadoop
- Comprobamos con
jps. Vemos que se ejecutan los servicios que se tienen que ejecutar en el nodomaster
- Comprobamos con
jpsen cualquier nodo worker(nodo1,nodo2,nodo3). También vemos que se ejecutan los servicios que se tienen que ejecutar en los nodos worker.
- Comprobamos con nuestra interfaz web de HDFS
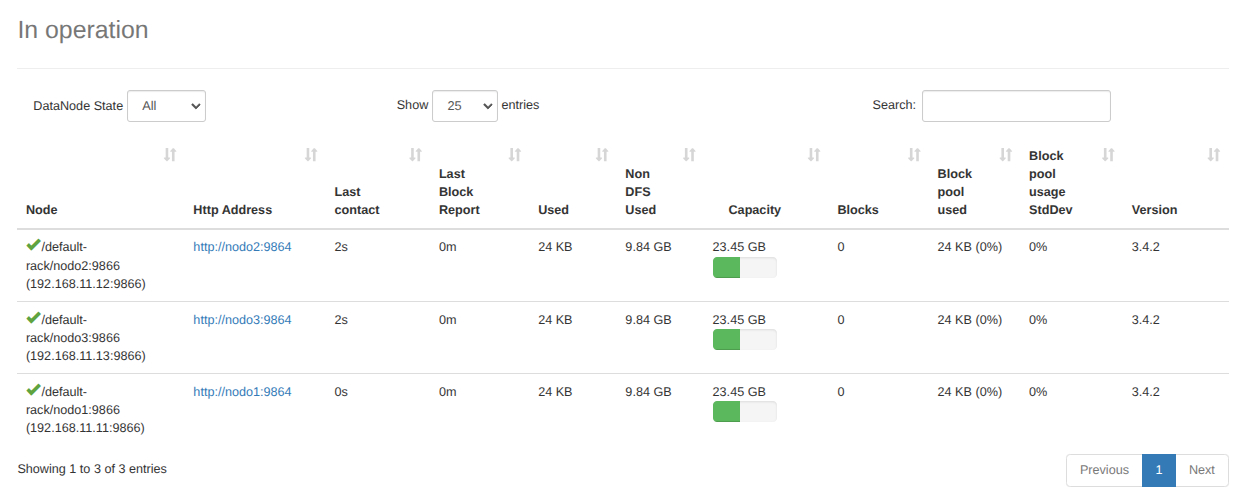
- Ya podemos utilizar el cluster. Compruébalo realizando alguno de los ejemplos desarrollados en los puntos anteriores