UD 6 - Apache Spark - Spark API¶
Ya hemos visto que uno de los mayores atractivos de Apache Spark para los desarrolladores ha sido sus APIs fáciles de usar para operar en grandes conjuntos de datos, en diferentes lenguajes de programación tales como: Scala, Java, Python y R.
En este módulo nos centraremos en aprender a "hablar" con Spark.
Preparación del Laboratorio (Docker)
Para probar estos ejemplos rápidamente sin desplegar todo el clúster, utilizaremos un contenedor efímero de la imagen oficial. Esto nos dará una consola de Python con Spark preconfigurado.
Abre tu terminal y ejecuta:
Verás el logo de Spark y un prompt >>>. Ahí podrás pegar los ejemplos de Python de esta unidad.
1. Spark APIs¶
Existen tres conjuntos de APIs disponibles en Apache Spark: RDDs, DataFrames y Datasets.
Desde Spark 2.0, DataFrames y Datasets están unificados. En Spark 4.0, esta unificación se mantiene, pero la arquitectura subyacente se ha modernizado para soportar Spark Connect, permitiendo que estas APIs se ejecuten desde clientes ligeros remotos.
1.1 RDD (Resilient Distributed Dataset)¶
RDD fue la principal API orientada al usuario en Spark desde su inicio. En el núcleo, un RDD es una colección distribuida inmutable de elementos de sus datos, particionados a través de nodos en su clúster que se pueden operar en paralelo con una API de bajo nivel que ofrece transformaciones y acciones.
¿Cuándo usar RDD?¶
- Necesitamos una transformación de bajo nivel y acciones y control en su conjunto de datos.
- Para datos no estructurados, como flujos de medios o flujos de texto.
- Prefieres programación funcional pura (lambda) sobre expresiones SQL.
- No necesitamos imponer un esquema, como formato de columna, mientras procesamos o accedemos a los atributos de los datos por nombre o columna.
- Podemos renunciar a algunos beneficios de optimización y rendimiento disponibles con DataFrames y Datasets para datos estructurados y semiestructurados.
- Desventaja: Pierdes las optimizaciones automáticas del motor Catalyst de Spark SQL
1.2 Dataset¶
Un Dataset es una colección distribuida de datos. Dataset es una nueva interfaz agregada en Spark 1.6 que proporciona los beneficios de los RDD (fuertemente tipado, capacidad de utilizar potentes funciones lambda) con los beneficios del motor de ejecución optimizado de Spark SQL. Se puede construir un Dataset a partir de objetos JVM y luego manipularlo mediante transformaciones funcionales (map, flatMap, filter, etc.).
La API del Dataset está disponible en Scala y Java. Python no es compatible con la API del Dataset. Pero debido a la naturaleza dinámica de Python, muchos de los beneficios de la API del Dataset ya están disponibles (es decir, puede acceder al campo de una fila por su nombre row.columnName). El caso de R es similar.
1.3 Dataframe¶
Un DataFrame es un Dataset organizado en columnas con nombre. Es conceptualmente equivalente a una tabla en una base de datos relacional o un marco de datos en R/Python, pero con optimizaciones más ricas bajo el capó. Los DataFrames se pueden construir a partir de una amplia gama de fuentes, como: archivos de datos estructurados, tablas en Hive, bases de datos externas o RDDs existentes.
La API DataFrame está disponible en Scala, Java, Python y R. En Scala y Java, un DataFrame está representado por un Dataset de filas. En la API de Scala, DataFrame es simplemente un alias de tipo de Dataset[Row]. Mientras que, en la API de Java, los usuarios deben usar Dataset
1.4 Spark SQL¶
Spark SQL es un módulo Spark para el procesamiento de datos estructurados. A diferencia de la API básica de Spark RDD, las interfaces proporcionadas por Spark SQL brindan a Spark más información sobre la estructura de los datos y el cálculo que se realiza.
Permite mezclar consultas SQL puras con código programático. Utiliza el optimizador Catalyst para reescribir tus consultas y hacerlas más eficientes, independientemente de si usas Python o Scala.
1.5 Beneficios Dataframe/Dataset APIs¶
- Tipado estático y tipado seguro en tiempo de ejecución: Dadas las diferencias de tipado entre las 3 APIs de Spark nos encontramos con las siguientes diferencias
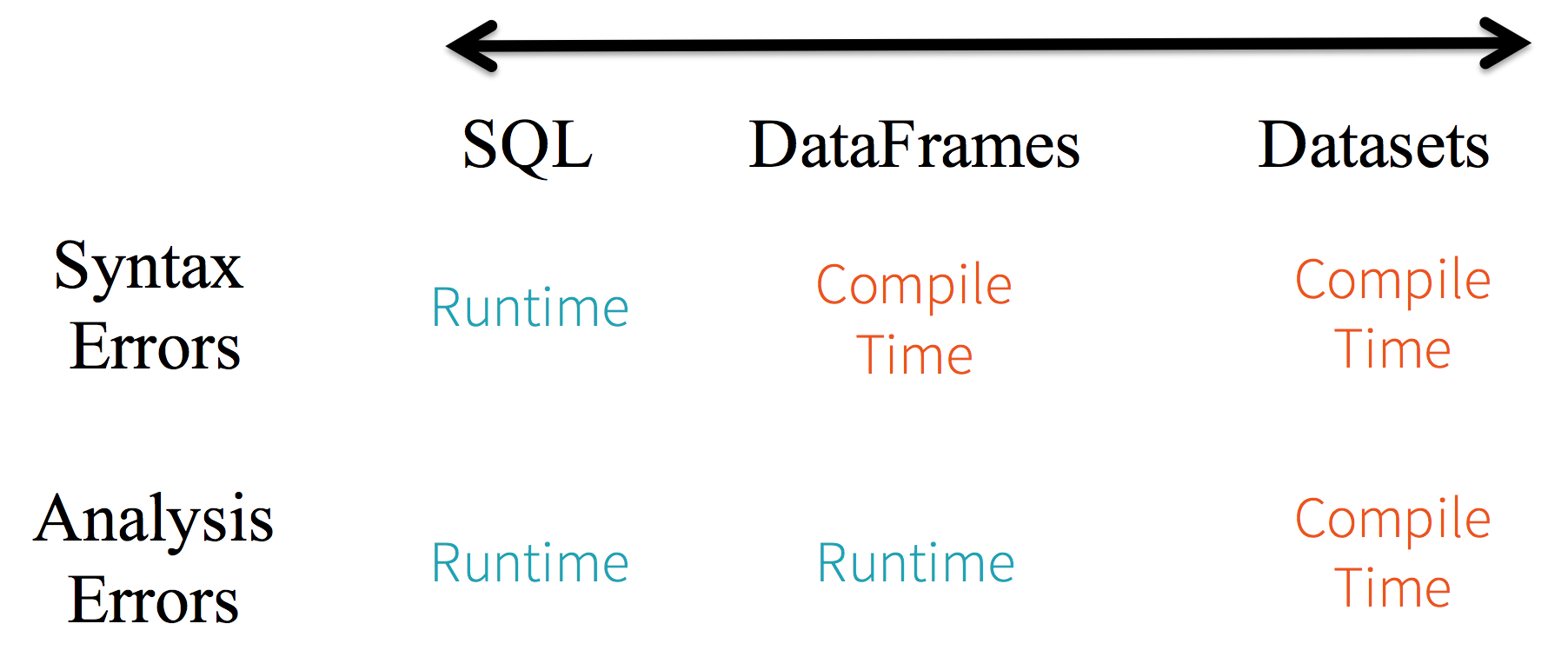
-
Alto nivel de Abstracción y vista personalizada de datos estructurados y semiestructurados.
-
Facilidad de uso de API con estructura: Introduce una semántica rica y un conjunto sencillo de operaciones específicas de dominio que pueden expresarse como construcciones de alto nivel. Es mucho más sencillo realizar operaciones
agg,select,sum,avg,map,filter,groupBy,filter,map -
Rendimiento y optimización: Mejoras de eficiencia en el uso de almacenamiento y ganancias de rendimiento.

2. RDDs. Getting Started¶
Aunque usaremos DataFrames la mayor parte del tiempo, entender los RDDs es vital para comprender la base.
Hay dos formas de crear RDD: paralelizar una colección existente en su driver program o hacer referencia a un conjunto de datos en un sistema de almacenamiento externo, como un sistema de archivos compartido, HDFS, HBase o cualquier fuente de datos que ofrezca un formato de entrada Hadoop.
2.1. Parallelized Collections¶
Parallelized Collections se crean llamando al método de parallelize de SparkContext. Los elementos de la colección se copian para formar un conjunto de datos distribuido que se puede operar en paralelo en nuestro cluster. Por ejemplo, Creamos una colección paralela que contenga los números del 1 al 8:
Una vez creado, el conjunto de datos distribuido (distData) se puede operar en paralelo. Por ejemplo, podemos llamar a distData.reduce(lambda a, b: a + b) para sumar los elementos de la lista.
2.2 Conjunto de datos externo¶
Spark puede crear conjuntos de datos distribuidos desde cualquier fuente de almacenamiento compatible con Hadoop, incluido su sistema de archivos local, HDFS, Cassandra, HBase, Amazon S3, etc. Spark admite archivos de texto, SequenceFiles y cualquier otro formato de entrada de Hadoop.
Los RDD de archivos de texto se pueden crear utilizando el método textFile de SparkContext. Este método toma un URI para el archivo (ya sea una ruta local en la máquina o un URI hdfs://, s3a://, etc.) y lo lee como una colección de líneas. Aquí hay un ejemplo de invocación:
3. Spark SQL, DataFrames and Datasets. Getting started¶
Puedes consultar toda la información detallada en la documentación oficial
3.1 Starting Point: SparkSession¶
El punto de entrada a todas las funciones de Spark es la clase SparkSession. Para crear una SparkSession básica, simplemente use SparkSession.builder:
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
examples/src/main/python/sql/basic.py del repositorio Spark. Estos también se encuentran en el directorio $SPARK_HOME tanto de la imagen virtual como la del contenedor Docker
El punto de entrada a todas las funciones de Spark es la clase SparkSession. Para crear una SparkSession básica, simplemente use SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala del repositorio Spark
El punto de entrada a todas las funciones de Spark es la clase SparkSession. Para crear una SparkSession básica, simplemente use SparkSession.builder:
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java del repositorio Spark
El punto de entrada a todas las funciones de Spark es la clase SparkSession. Para crear unaSparkSessionbásica, simplemente usesparkR.session():
sparkR.session(appName = "R Spark SQL basic example", sparkConfig = list(spark.some.config.option = "some-value"))
examples/src/main/r/RSparkSQLExample.R del repositorio Spark
3.2 Creando Dataframes¶
Con SparkSession, las aplicaciones pueden crear DataFrames a partir de un RDD existente, de una tabla de Hive o de fuentes de datos de Spark.
Como ejemplo, lo siguiente crea un DataFrame basado en el contenido de un archivo JSON
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
Dataset<Row> df = spark.read().json("file:///opt/spark/examples/src/main/resources/people.json");
// Displays the content of the DataFrame to stdout
df.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
df <- read.json("file:///opt/spark/examples/src/main/resources/people.json")
# Displays the content of the DataFrame
head(df)
## age name
## 1 NA Michael
## 2 30 Andy
## 3 19 Justin
# Another method to print the first few rows and optionally truncate the printing of long values
showDF(df)
## +----+-------+
## | age| name|
## +----+-------+
## |null|Michael|
## | 30| Andy|
## | 19| Justin|
## +----+-------+
3.3 DataFrame Operations¶
Los DataFrames proporcionan un lenguaje específico de dominio para la manipulación de datos estructurados en Scala, Java, Python y R.
Estas operaciones también se denominan "transformaciones no tipadas" en contraste con las "transformaciones fuertemente tipadas" que vienen con conjuntos de datos Scala/Java.
Aquí incluimos algunos ejemplos básicos de procesamiento de datos estructurados utilizando Datasets:
# spark, df are from the previous example
# Print the schema in a tree format
df.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true)
# Select only the "name" column
df.select("name").show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
# Select everybody, but increment the age by 1
df.select(df['name'], df['age'] + 1).show()
# +-------+---------+
# | name|(age + 1)|
# +-------+---------+
# |Michael| null|
# | Andy| 31|
# | Justin| 20|
# +-------+---------+
# Select people older than 21
df.filter(df['age'] > 21).show()
# +---+----+
# |age|name|
# +---+----+
# | 30|Andy|
# +---+----+
# Count people by age
df.groupBy("age").count().show()
# +----+-----+
# | age|count|
# +----+-----+
# | 19| 1|
# |null| 1|
# | 30| 1|
# +----+-----+
// This import is needed to use the $-notation
import spark.implicits._
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
// col("...") is preferable to df.col("...")
import static org.apache.spark.sql.functions.col;
// Print the schema in a tree format
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show();
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select(col("name"), col("age").plus(1)).show();
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter(col("age").gt(21)).show();
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show();
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
# Create the DataFrame
df <- read.json("examples/src/main/resources/people.json")
# Show the content of the DataFrame
head(df)
## age name
## 1 NA Michael
## 2 30 Andy
## 3 19 Justin
# Print the schema in a tree format
printSchema(df)
## root
## |-- age: long (nullable = true)
## |-- name: string (nullable = true)
# Select only the "name" column
head(select(df, "name"))
## name
## 1 Michael
## 2 Andy
## 3 Justin
# Select everybody, but increment the age by 1
head(select(df, df$name, df$age + 1))
## name (age + 1.0)
## 1 Michael NA
## 2 Andy 31
## 3 Justin 20
# Select people older than 21
head(where(df, df$age > 21))
## age name
## 1 30 Andy
# Count people by age
head(count(groupBy(df, "age")))
## age count
## 1 19 1
## 2 NA 1
## 3 30 1
3.4 Ejecutando sentencias SQL¶
La función SQL en SparkSession permite que las aplicaciones ejecuten consultas SQL mediante programación y devuelve el resultado como un DataFrame.
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people");
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.5 Vista temporal global¶
Las vistas temporales en Spark SQL tienen un ámbito de sesión y desaparecerán si finaliza la sesión que las crea. Si deseamos tener una vista temporal que se comparta entre todas las sesiones y mantenerla activa hasta que finalice la aplicación Spark, podemos crear una vista temporal global. La vista temporal global está vinculada a una base de datos global_temp preservada por el sistema, y debemos usar el nombre calificado para referirla, por ejemplo: SELECT * FROM global_temp.view1.
# Register the DataFrame as a global temporary view
df.createGlobalTempView("people")
# Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
# Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
# +----+-------+
# | age| name|
# +----+-------+
# |null|Michael|
# | 30| Andy|
# | 19| Justin|
# +----+-------+
// Register the DataFrame as a global temporary view
df.createGlobalTempView("people")
// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Register the DataFrame as a global temporary view
df.createGlobalTempView("people");
// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.6 Creando Dataset¶
Los Dataset son similares a los RDD, sin embargo, en lugar de utilizar la serialización Java o Kryo, utilizan un codificador Encoder para serializar los objetos para procesarlos o transmitirlos a través de la red. Si bien tanto los codificadores como la serialización estándar son responsables de convertir un objeto en bytes, los codificadores son código generado dinámicamente y utilizan un formato que permite a Spark realizar muchas operaciones como filtrado, clasificación y hash sin deserializar los bytes nuevamente en un objeto.
case class Person(name: String, age: Long)
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "examples/src/main/resources/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
import java.util.Arrays;
import java.util.Collections;
import java.io.Serializable;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.Encoder;
import org.apache.spark.sql.Encoders;
public static class Person implements Serializable {
private String name;
private long age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getAge() {
return age;
}
public void setAge(long age) {
this.age = age;
}
}
// Create an instance of a Bean class
Person person = new Person();
person.setName("Andy");
person.setAge(32);
// Encoders are created for Java beans
Encoder<Person> personEncoder = Encoders.bean(Person.class);
Dataset<Person> javaBeanDS = spark.createDataset(
Collections.singletonList(person),
personEncoder
);
javaBeanDS.show();
// +---+----+
// |age|name|
// +---+----+
// | 32|Andy|
// +---+----+
// Encoders for most common types are provided in class Encoders
Encoder<Long> longEncoder = Encoders.LONG();
Dataset<Long> primitiveDS = spark.createDataset(Arrays.asList(1L, 2L, 3L), longEncoder);
Dataset<Long> transformedDS = primitiveDS.map(
(MapFunction<Long, Long>) value -> value + 1L,
longEncoder);
transformedDS.collect(); // Returns [2, 3, 4]
// DataFrames can be converted to a Dataset by providing a class. Mapping based on name
String path = "examples/src/main/resources/people.json";
Dataset<Person> peopleDS = spark.read().json(path).as(personEncoder);
peopleDS.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.7 Interoperar con RDD¶
Spark SQL admite dos métodos diferentes para convertir RDD existentes en Dataset. El primer método utiliza la reflexión para inferir el esquema de un RDD que contiene tipos específicos de objetos. Este enfoque basado en la reflexión genera un código más conciso y funciona bien cuando ya conoce el esquema mientras escribe su aplicación Spark.
El segundo método para crear Dataset es a través de una interfaz programática que le permite construir un esquema y luego aplicarlo a un RDD existente. Si bien este método es más detallado, le permite construir Dataset cuando las columnas y sus tipos no se conocen hasta el tiempo de ejecución.
1. Usando Reflexión
from pyspark.sql import Row
sc = spark.sparkContext
# Load a text file and convert each line to a Row.
lines = sc.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
# Infer the schema, and register the DataFrame as a table.
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
// For implicit conversions from RDDs to DataFrames
import spark.implicits._
// Create an RDD of Person objects from a text file, convert it to a Dataframe
val peopleDF = spark.sparkContext
.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by Spark
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// The columns of a row in the result can be accessed by field index
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// or by field name
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// No pre-defined encoders for Dataset[Map[K,V]], define explicitly
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
// Primitive types and case classes can be also defined as
// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect()
// Array(Map("name" -> "Justin", "age" -> 19))
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.Encoder;
import org.apache.spark.sql.Encoders;
// Create an RDD of Person objects from a text file
JavaRDD<Person> peopleRDD = spark.read()
.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
.javaRDD()
.map(line -> {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
});
// Apply a schema to an RDD of JavaBeans to get a DataFrame
Dataset<Row> peopleDF = spark.createDataFrame(peopleRDD, Person.class);
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people");
// SQL statements can be run by using the sql methods provided by spark
Dataset<Row> teenagersDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19");
// The columns of a row in the result can be accessed by field index
Encoder<String> stringEncoder = Encoders.STRING();
Dataset<String> teenagerNamesByIndexDF = teenagersDF.map(
(MapFunction<Row, String>) row -> "Name: " + row.getString(0),
stringEncoder);
teenagerNamesByIndexDF.show();
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// or by field name
Dataset<String> teenagerNamesByFieldDF = teenagersDF.map(
(MapFunction<Row, String>) row -> "Name: " + row.<String>getAs("name"),
stringEncoder);
teenagerNamesByFieldDF.show();
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
2. Interfaz Programática
Se puede crear un DataFrame mediante programación con tres pasos:
- Creamos un RDD de tuplas/filas o listas a partir del RDD original;
- Creamos el esquema representado por un
StructTypeque coincida con la estructura de tuplas/filas o listas en el RDD creado en el paso 1. - Aplicamos el esquema al RDD mediante el método
createDataFrameproporcionado porSparkSession
# Import data types
from pyspark.sql.types import StringType, StructType, StructField
sc = spark.sparkContext
# Load a text file and convert each line to a Row.
lines = sc.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
# Each line is converted to a tuple.
people = parts.map(lambda p: (p[0], p[1].strip()))
# The schema is encoded in a string.
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
# Apply the schema to the RDD.
schemaPeople = spark.createDataFrame(people, schema)
# Creates a temporary view using the DataFrame
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
results = spark.sql("SELECT name FROM people")
results.show()
# +-------+
# | name|
# +-------+
# |Michael|
# | Andy|
# | Justin|
# +-------+
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
// Create an RDD
val peopleRDD = spark.sparkContext.textFile("file:///opt/spark/examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL can be run over a temporary view created using DataFrames
val results = spark.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
results.map(attributes => "Name: " + attributes(0)).show()
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
// Create an RDD
JavaRDD<String> peopleRDD = spark.sparkContext()
.textFile("file:///opt/spark/examples/src/main/resources/people.txt", 1)
.toJavaRDD();
// The schema is encoded in a string
String schemaString = "name age";
// Generate the schema based on the string of schema
List<StructField> fields = new ArrayList<>();
for (String fieldName : schemaString.split(" ")) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
StructType schema = DataTypes.createStructType(fields);
// Convert records of the RDD (people) to Rows
JavaRDD<Row> rowRDD = peopleRDD.map((Function<String, Row>) record -> {
String[] attributes = record.split(",");
return RowFactory.create(attributes[0], attributes[1].trim());
});
// Apply the schema to the RDD
Dataset<Row> peopleDataFrame = spark.createDataFrame(rowRDD, schema);
// Creates a temporary view using the DataFrame
peopleDataFrame.createOrReplaceTempView("people");
// SQL can be run over a temporary view created using DataFrames
Dataset<Row> results = spark.sql("SELECT name FROM people");
// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
Dataset<String> namesDS = results.map(
(MapFunction<Row, String>) row -> "Name: " + row.getString(0),
Encoders.STRING());
namesDS.show();
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
Esta es sólo una pequeña muestra de la Spark API. Puedes consultar la documentación completa en la página oficial
Ejemplo¶
import sys
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.options(header='True', inferSchema='True').csv( sys.argv[1] )
def myFunc(s):
if s["brand"]=="riche" and s["event_type"]=="cart":
return [ ( s["product_id"], 1) ]
return []
lines=df.rdd.flatMap(myFunc).reduceByKey(lambda a, b: a + b)
lines.saveAsTextFile( sys.argv[2] )
4. Pandas on PySpark¶
4.1 ¿Qué es Pandas?¶
Pandas es una biblioteca de software de código abierto diseñada específicamente para la manipulación y el análisis de datos en el lenguaje Python. Es potente, flexible y fácil de usar.
Gracias a Pandas, podemos utilizar el lenguaje Python para cargar, alinear, manipular o incluso fusionar datos. Tiene un alto rendimiento.
El nombre "Pandas" es en realidad una contracción del término «Panel Data» para series de datos que incluyen observaciones a lo largo de varios periodos de tiempo. La biblioteca se creó como herramienta de alto nivel para el análisis en Python. Los creadores de Pandas pretenden que esta biblioteca evolucione hasta convertirse en la herramienta de análisis y manipulación de datos de código abierto más potente y flexible en cualquier lenguaje de programación.
Además del análisis de datos, Pandas se utiliza mucho para la «Data Wrangling«. Este término engloba los métodos de transformación de datos no estructurados para hacerlos procesables.
Puedes consultar toda la documentación en la página oficial de Pandas
4.2 Funcionamiento¶

Pandas esta construida con el paquete Numpy que es una librería de python para la manipulación de matrices y vectores n-dimensional. Entonces un Dataframe en pandas es la estructura de datos clave que va a permitir la manipulación de datos tabulados en filas y columnas.

Admite la integración con muchos formatos de archivos o fuentes de datos listas para usar (csv, excel, sql, json, parquet,…). La importación de datos de cada una de estas fuentes de datos se realiza mediante una función con el prefijo read_*. De manera similar, los métodos to_* se utilizan para almacenar datos.
Además, te permite realizar numerosas operaciones sobre los DataFrame muy eficientemente, tales como:
- Selección de un subconjunto
Permite seleccionar y filtrar datos según cualquier condición y extraer los datos que queramos.

- Crear tramas (plot)
Pandas permite "dibujar" sus datos de forma inmediata gracias a Matplotlib. Podemos elegir el tipo de gráfico (dispersión, barras, diagrama de caja,…) correspondiente a los datos.

- Crear nuevas columnas derivadas de columnas existentes
No es necesario recorrer todas las filas de su tabla de datos para realizar cálculos. Las manipulaciones de datos en una columna funcionan por elementos. Así que podemos agregar una columna a un DataFrame en función de los datos existentes de forma sencilla y eficiente.

- Calcular estadísticas
Podemos realizar estadísticas básicas de forma sencilla (media, mediana, mínimo, máximo, recuentos...). Estas agregaciones personalizadas pueden aplicarse a todo el conjunto de datos, a un subconjunto de datos o agruparse por categorías. Este último también se conoce como enfoque de división, aplicación y combinación.

- Remodelar la estructura de los datos
Podemos cambiar la estructura de la tabla de datos de varias maneras. Podemos fundir (melt()) o pivotar (pivot()) el formato de la tabla de datos. Con agregaciones integradas, podemos crear una tabla dinámica con un solo comando.

- Combinar datos de varias tablas
Podemos concatenar varias tablas tanto por columnas como por filas, ya que pandas proporciona operaciones de unión/fusión similares a las de una base de datos para combinar varias tablas.

- Manejar datos de series de tiempo
Pandas tiene un gran soporte para series temporales y un amplio conjunto de herramientas para trabajar con fechas, horas y datos indexados en el tiempo.
- Manipular datos de texto
Pandas también proporciona una amplia gama de funciones para limpiar datos textuales y extraer información útil de ellos.
Success
En temas de rendimiento la máxima cantidad de registros que soporta pandas es de alrededor de 2 millones. Si tienes un archivo con numero de registros mayor a esta cantidad una buena opción seria trabajarlo con Spark.
4.3 Quick Started Pandas on Pyspark¶
Vamos a ver una introducción a la API de pandas en Spark, dirigida principalmente a nuevos usuarios. Mostraremos algunas diferencias clave entre pandas y la API de pandas en Spark.
Requisito Lab Mode
Para este Laboratorio Ágil, queremos flexibilidad, no rigidez. Debemos arrancar Spark con el modo ANSI desactivado (como en versiones anteriores) y configurar la variable de entorno de PyArrow. Además, las imágenes oficiales de Spark son ligeras y seguras (se ejecutan con usuarios restringidos), por lo que no incluyen librerías de terceros como pandas ni permisos para instalarlas.
Por tanto, debemos:
- Arrancaremos el contenedor como root (
-u 0o-u root) para poder instalar las dependencias al vuelo - Añadimos -e PYARROW_IGNORE_TIMEZONE=1 y el flag --conf spark.sql.ansi.enabled=false al arrancar PySpark.
- Importamos la API de pandas en Spark de la siguiente manera:
import pandas as pd
import numpy as np
import pyspark.pandas as ps
from pyspark.sql import SparkSession
# Configuración opcional para mejorar rendimiento con Arrow
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
Creación de objetos¶
- Creamos una serie de pandas-on-Spark pasando una lista de valores, permitiendo que la API de pandas en Spark cree un índice entero predeterminado:
psdf = ps.DataFrame(
{'a': [1, 2, 3, 4, 5, 6],
'b': [100, 200, 300, 400, 500, 600],
'c': ["one", "two", "three", "four", "five", "six"]},
index=[10, 20, 30, 40, 50, 60])
psdf
......
a b c
10 1 100 one
20 2 200 two
30 3 300 three
40 4 400 four
50 5 500 five
60 6 600 six
- Creamos un DataFrame de pandas pasando una matriz numpy, con un índice de fecha y hora y columnas etiquetadas:
dates = pd.date_range('20130101', periods=6)
dates
......
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
pdf = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
pdf
A B C D
2013-01-01 -0.226476 1.520000 1.663753 -1.267302
2013-01-02 1.196732 0.095140 -0.523730 0.082918
2013-01-03 -0.927348 -0.628459 -0.515106 -1.392611
2013-01-04 1.312875 0.622895 0.736196 0.130573
2013-01-05 0.190151 -0.743863 -1.893324 -0.193831
2013-01-06 -1.250740 -1.183809 -0.585104 1.273198
- Ahora, este DataFrame de pandas puede convertirse en un DataFrame de pandas on Spark
- Se ve y se comporta igual que un DataFrame de pandas.
psdf
A B C D
2013-01-01 1.662075 -0.217748 -0.355189 0.370806
2013-01-02 -0.149359 0.794238 0.395572 -0.960923
2013-01-03 0.525266 0.194693 -1.106916 0.007914
2013-01-04 -0.889802 1.265897 0.786845 -0.044647
2013-01-05 -0.330468 1.892863 0.527275 0.577991
2013-01-06 -0.331758 -1.484555 -0.070703 2.085198
-
Además, es posible crear fácilmente un DataFrame de pandas en Spark desde Spark DataFrame.
-
Creando un Spark DataFrame a partir de pandas DataFrame
spark = SparkSession.builder.getOrCreate()
sdf = spark.createDataFrame(pdf)
sdf.show()
........
+--------------------+--------------------+--------------------+--------------------+
| A| B| C| D|
+--------------------+--------------------+--------------------+--------------------+
| 1.6620753155346328|-0.21774761534574633|-0.35518909051233893| 0.3708055976772801|
|-0.14935937325876253| 0.7942380736543752| 0.39557223951979703| -0.9609225938877662|
| 0.5252657037772347| 0.19469309562268242| -1.10691559221667|0.007914306640221703|
| -0.8898016374976273| 1.265897385701341| 0.7868454159229309|-0.04464660559581...|
|-0.33046824706157335| 1.8928634625070386| 0.5272750185971309| 0.5779909628737645|
| -0.3317576493473523| -1.4845554531433143|-0.07070259353437969| 2.085198032978165|
+--------------------+--------------------+--------------------+--------------------+
- Creando pandas-on-Spark DataFrame desde Spark DataFrame.
psdf = sdf.pandas_api()
psdf
.........
A B C D
0 1.662075 -0.217748 -0.355189 0.370806
1 -0.149359 0.794238 0.395572 -0.960923
2 0.525266 0.194693 -1.106916 0.007914
3 -0.889802 1.265897 0.786845 -0.044647
4 -0.330468 1.892863 0.527275 0.577991
5 -0.331758 -1.484555 -0.070703 2.085198
- Tipos específicos dtypes. Actualmente se admiten tipos que son comunes tanto para Spark como para pandas.
- A continuación explicamos cómo mostrar las filas superiores del cuadro siguiente. Hay que tener en cuenta que los DataFrame de Spark no conservan el orden natural de forma predeterminada. El orden natural se puede preservar configurando la opción
compute.ordered_head, pero provoca una sobrecarga de rendimiento con la clasificación interna.
psdf.head()
A B C D
0 1.662075 -0.217748 -0.355189 0.370806
1 -0.149359 0.794238 0.395572 -0.960923
2 0.525266 0.194693 -1.106916 0.007914
3 -0.889802 1.265897 0.786845 -0.044647
4 -0.330468 1.892863 0.527275 0.577991
- Mostrando el índice, las columnas y los numerosos datos subyacentes.
psdf.to_numpy()
.............
array([[ 1.66207532, -0.21774762, -0.35518909, 0.3708056 ],
[-0.14935937, 0.79423807, 0.39557224, -0.96092259],
[ 0.5252657 , 0.1946931 , -1.10691559, 0.00791431],
[-0.88980164, 1.26589739, 0.78684542, -0.04464661],
[-0.33046825, 1.89286346, 0.52727502, 0.57799096],
[-0.33175765, -1.48455545, -0.07070259, 2.08519803]])
- Mostrando un resumen estadístico rápido de sus datos
psdf.describe()
...................
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.080992 0.407565 0.029481 0.339390
std 0.898039 1.192377 0.693517 1.005379
min -0.889802 -1.484555 -1.106916 -0.960923
25% -0.331758 -0.217748 -0.355189 -0.044647
50% -0.330468 0.194693 -0.070703 0.007914
75% 0.525266 1.265897 0.527275 0.577991
max 1.662075 1.892863 0.786845 2.085198
- Transponiendo los datos
psdf.T
..............
0 1 2 3 4 5
A 1.662075 -0.149359 0.525266 -0.889802 -0.330468 -0.331758
B -0.217748 0.794238 0.194693 1.265897 1.892863 -1.484555
C -0.355189 0.395572 -1.106916 0.786845 0.527275 -0.070703
D 0.370806 -0.960923 0.007914 -0.044647 0.577991 2.085198
- Ordenando por índice
psdf.sort_index(ascending=False)
..............
A B C D
5 -0.331758 -1.484555 -0.070703 2.085198
4 -0.330468 1.892863 0.527275 0.577991
3 -0.889802 1.265897 0.786845 -0.044647
2 0.525266 0.194693 -1.106916 0.007914
1 -0.149359 0.794238 0.395572 -0.960923
0 1.662075 -0.217748 -0.355189 0.370806
- Ordenando por valor
psdf.sort_values(by='B')
.................
A B C D
5 -0.331758 -1.484555 -0.070703 2.085198
0 1.662075 -0.217748 -0.355189 0.370806
2 0.525266 0.194693 -1.106916 0.007914
1 -0.149359 0.794238 0.395572 -0.960923
3 -0.889802 1.265897 0.786845 -0.044647
4 -0.330468 1.892863 0.527275 0.577991
Datos perdidos (Missing Data)¶
- La API de Pandas en Spark utiliza principalmente el valor
np.nanpara representar los datos perdidos. Por defecto no se incluye en los cálculos.
pdf1 = pdf.reindex(index=dates[0:4], columns=list(pdf.columns) + ['E'])
pdf1.loc[dates[0]:dates[1], 'E'] = 1
psdf1 = ps.from_pandas(pdf1)
psdf1
.................
A B C D E
2013-01-01 1.662075 -0.217748 -0.355189 0.370806 1.0
2013-01-02 -0.149359 0.794238 0.395572 -0.960923 1.0
2013-01-03 0.525266 0.194693 -1.106916 0.007914 NaN
2013-01-04 -0.889802 1.265897 0.786845 -0.044647 NaN
- Eliminar cualquier fila a la que le falten datos.
psdf1.dropna(how='any')
..............
A B C D E
2013-01-01 1.662075 -0.217748 -0.355189 0.370806 1.0
2013-01-02 -0.149359 0.794238 0.395572 -0.960923 1.0
- Llenando datos perdidos.
psdf1.fillna(value=5)
.....................
A B C D E
2013-01-01 1.662075 -0.217748 -0.355189 0.370806 1.0
2013-01-02 -0.149359 0.794238 0.395572 -0.960923 1.0
2013-01-03 0.525266 0.194693 -1.106916 0.007914 5.0
2013-01-04 -0.889802 1.265897 0.786845 -0.044647 5.0
Operaciones¶
- Estadísticas. Realizando una estadística descriptiva:
- Configuraciones Spark. Se podrían aplicar varias configuraciones en PySpark internamente en la API de pandas en Spark. Por ejemplo, podemos habilitar la optimización de Arrow para acelerar enormemente la conversión interna de pandas. Consulte también la Guía de uso de PySpark para Pandas con Apache Arrow en la documentación de PySpark.
rev = spark.conf.get("spark.sql.execution.arrow.pyspark.enabled") # Keep its default value.
ps.set_option("compute.default_index_type", "distributed") # Use default index prevent overhead.
import warnings
warnings.filterwarnings("ignore") # Ignore warnings coming from Arrow optimizations.
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)
%timeit ps.range(300000).to_pandas()
..........
900 ms ± 186 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", False)
%timeit ps.range(300000).to_pandas()
...............
3.08 s ± 227 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
ps.reset_option("compute.default_index_type")
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", prev) # Set its default value back.
Agrupamiento (Grouping)¶
- Por “agrupar por” nos referimos a un proceso que involucra uno o más de los siguientes pasos:
- Dividir los datos en grupos según algunos criterios.
- Aplicar una función a cada grupo de forma independiente
- Combinar los resultados en una estructura de datos.
psdf = ps.DataFrame({'A': ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
psdf
....................
A B C D
0 foo one -0.065723 -1.171527
1 bar one -1.097599 -0.412641
2 foo two 0.385108 0.332648
3 bar three 0.064532 1.432139
4 foo two 0.313329 -0.327933
5 bar two -1.320756 -0.013414
6 foo one 0.213044 -1.157642
7 foo three -0.247784 -0.604997
- Agrupar y luego aplicar la función sum() a los grupos resultantes.
psdf.groupby('A').sum()
...............
B C D
A
foo onetwotwoonethree 0.597974 -2.929451
bar onethreetwo -2.353823 1.006083
- La agrupación por varias columnas forma un índice jerárquico y nuevamente podemos aplicar la función de suma.
psdf.groupby(['A', 'B']).sum()
C D
A B
foo one 0.147321 -2.329169
bar one -1.097599 -0.412641
foo two 0.698437 0.004715
bar three 0.064532 1.432139
two -1.320756 -0.013414
foo three -0.247784 -0.604997
Plotting¶
Warning
Estos métodos deben ejecutarse en un notebook tipo Jupyter, por ejemplo: databricks o jupyter en pyspark(lo vemos en el siguiente punto). También en google colab, entre otros.
pser = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))
psser = ps.Series(pser)
psser = psser.cummax()
psser.plot()

- En un DataFrame, es conveniente usar el método
plot()para trazar todas las columnas con etiquetas:
pdf = pd.DataFrame(np.random.randn(1000, 4), index=pser.index,
columns=['A', 'B', 'C', 'D'])
psdf = ps.from_pandas(pdf)
psdf = psdf.cummax()
psdf.plot()
# En nuestro contenedor docker, evidentemente no se ve la gráfica, pero en un Jupyter Notebook si.
Entrada/Salida de datos¶
- CSV
psdf.to_csv('foo.csv')
ps.read_csv('foo.csv').head(10)
.....................
A B C D
0 foo three -0.247784 -0.604997
1 bar two -1.320756 -0.013414
2 foo one -0.065723 -1.171527
3 foo two 0.313329 -0.327933
4 bar one -1.097599 -0.412641
5 bar three 0.064532 1.432139
6 foo one 0.213044 -1.157642
7 foo two 0.385108 0.332648
psdf.to_parquet('bar.parquet')
ps.read_parquet('bar.parquet').head(10)
...............
A B C D
0 foo three -0.247784 -0.604997
1 bar three 0.064532 1.432139
2 foo two 0.385108 0.332648
3 bar one -1.097599 -0.412641
4 foo one -0.065723 -1.171527
5 bar two -1.320756 -0.013414
6 foo one 0.213044 -1.157642
7 foo two 0.313329 -0.327933
- Spark IO. Además, la API de pandas en Spark es totalmente compatible con las diversas fuentes de datos de Spark, como ORC y una fuente de datos externa.
psdf.spark.to_spark_io('zoo.orc', format="orc")
ps.read_spark_io('zoo.orc', format="orc").head(10)
..................
A B C D
0 bar three 0.064532 1.432139
1 foo three -0.247784 -0.604997
2 foo one 0.213044 -1.157642
3 bar two -1.320756 -0.013414
4 foo one -0.065723 -1.171527
5 foo two 0.385108 0.332648
6 bar one -1.097599 -0.412641
7 foo two 0.313329 -0.327933