UD 7 - Apache Kafka Stream¶
1. Introducción¶
Kafka Streams es una biblioteca cliente para construir aplicaciones y microservicios, donde los datos de entrada y salida se almacenan en clústers de Kafka. Combina la simplicidad de escribir y desplegar aplicaciones Java y Scala estándar en el lado del cliente con los beneficios de la tecnología de clústeres del lado del servidor de Kafka.
Las aplicaciones desarrolladas con Kafka Streams podrán realizar procesamiento en streaming. De esta forma, se procesa de manera secuencial sobre flujos de datos sin límites temporales. Se basa en la mensajería de Kafka para permitir procesar datos en tiempo real. Pero mientras un productor Kafka sólo publica datos en un topic, y un consumidor únicamente consume datos de topics, las aplicaciones Kafka Streams pueden utilizar uno o varios topics como entrada, realizar algún tipo de transformación o procesado de esos datos y dejar el resultado como salida en otro u otros topics.
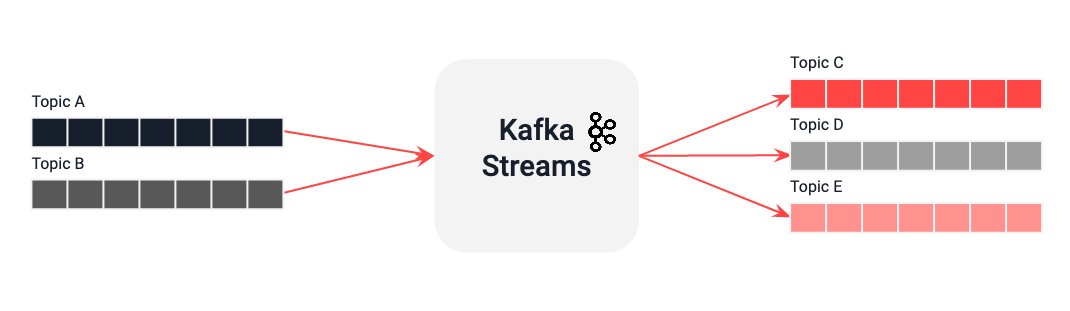
Además, Kafka Streams gestiona de forma transparente el equilibrio de carga de varias instancias de la misma aplicación aprovechando el modelo de paralelismo de Kafka.
2. Concepto¶
El concepto de kafka stream se basa en una topología, denominada Stream Processing Topology. Esta topología de procesamiento de streams es el esquema o diseño de cómo se procesan los streams en una aplicación Kafka Streams. Se compone de stream processor o nodos de procesador que son entidades lógicas que procesan los datos. Cada nodo en la topología está vinculado a otros nodos para formar un grafo dirigido acíclico (DAG).
2.1 Stream Processing Topology¶
Una topología de procesamiento de streams es el esquema o diseño de cómo se procesan los streams en una aplicación Kafka Streams. Se compone de nodos de procesador que son entidades lógicas que procesan los datos. Cada nodo en la topología está vinculado a otros nodos para formar un grafo dirigido acíclico (DAG).
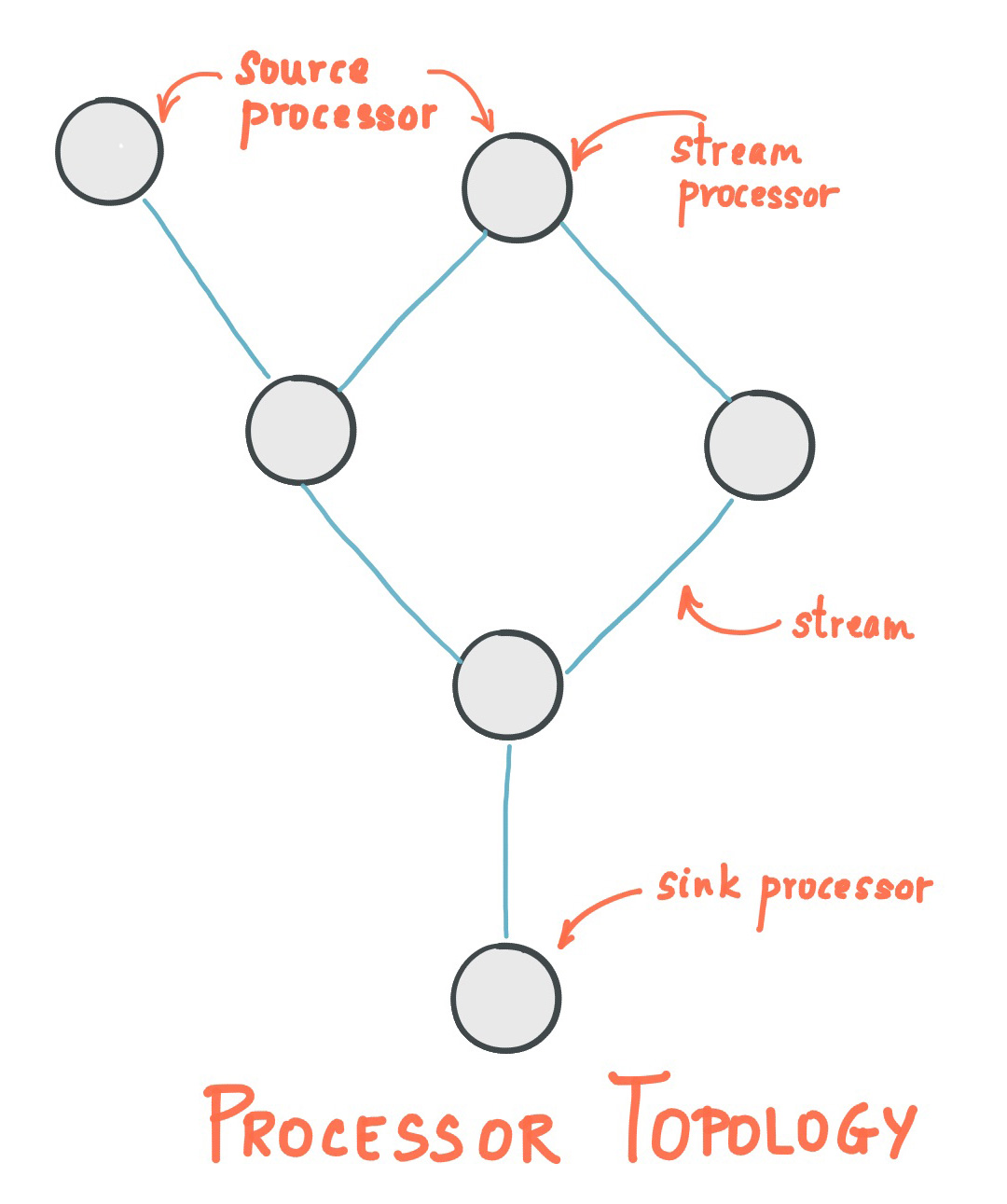
Estos nodos pueden ser de 2 tipos
- Source Processor: Es un tipo especial de source processor que no tienen otros processor anteriores. Por tanto, producen un stream de entrada a su topología a partir de uno o varios topics Kafka consumiendo registros de estos topics y reenviándolos a sus procesadores de stream descendente
- Sink Processor: Es un tipo especial de stream processor que no tiene procesadores de stream descendente. Envía todos los registros recibidos de sus strem process ascendente a un topic Kafka especificado.
2.2 Construcción de la Topología¶
La topología de procesamiento se define programáticamente usando la Streams DSL o la Processor API:
-
Streams DSL: Proporciona abstracciones de alto nivel, como KStream, KTable, y GlobalKTable, que permiten definir transformaciones complejas con poco código, como
map,filter,joinandaggregations -
Processor API: Ofrece control granular sobre el procesamiento de streams y permite definir operaciones personalizadas, gestionar el estado y conectarse con otros sistemas.
2.3 KStream vs KTable¶
En Kafka Streams, KStream y KTable son dos abstracciones fundamentales que representan diferentes formas de ver los datos en un stream de Apache Kafka. Cada uno tiene características y usos específicos dependiendo de la naturaleza de los datos y el tipo de operaciones de procesamiento de streams que necesitas realizar.
KStream¶
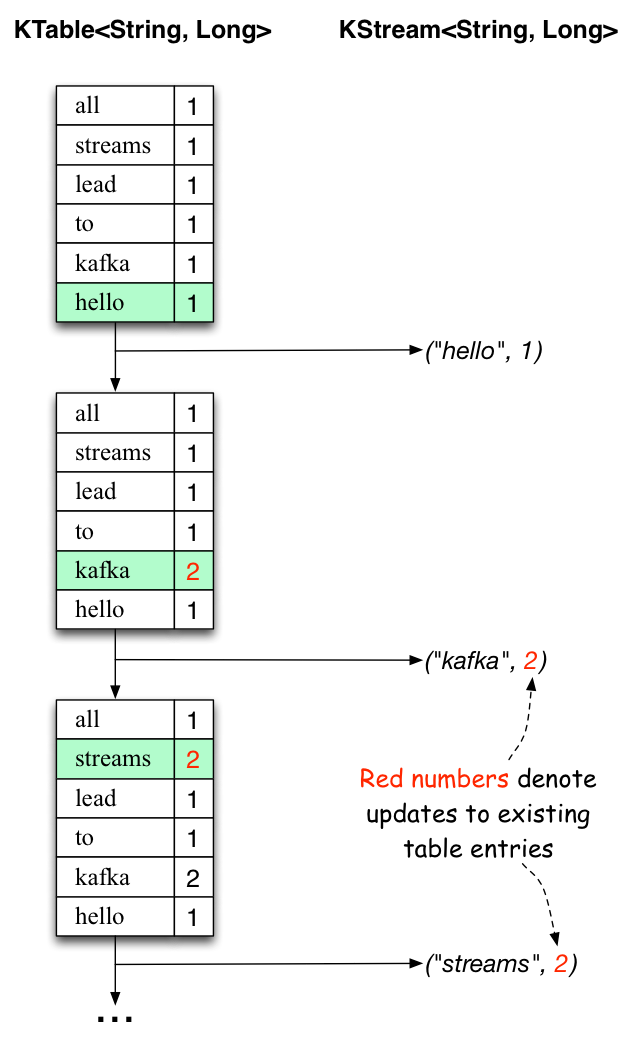
Representa un stream de registros de datos donde cada registro en el stream es considerado un evento independiente. Se utilizan para modelar datos, donde cada registro es una pieza autocontenida de los datos dentro de un conjunto de datos sin consolidar. Esto debe entenderse como un flujo de registros, donde los nuevos registros no reemplazarán una parte de los datos existentes con un nuevo valor. Los streams contienen una historia o una secuencia de los datos.
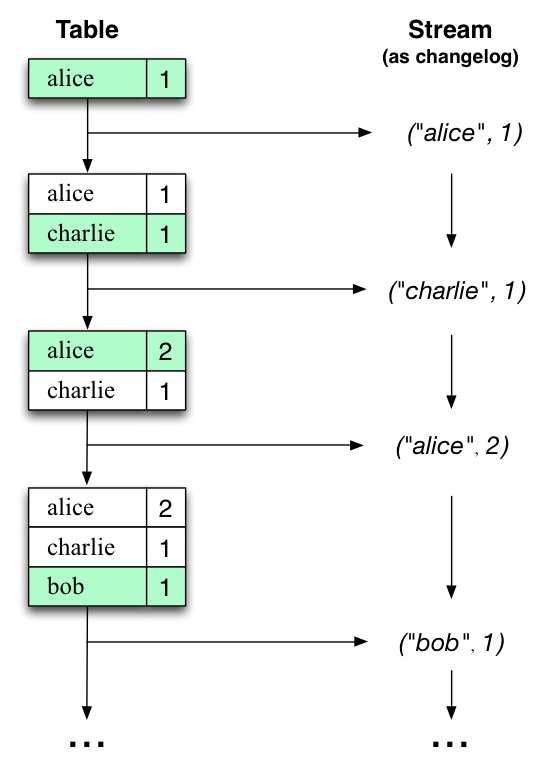
KTable¶
Representa una tabla de registros, donde cada registro es considerado un estado actual (última actualización) de la clave. Es similar a una base de datos relacional donde cada clave tiene un valor actual que puede ser actualizado o borrado.

2.3. Manejo del tiempo¶
El manejo del tiempo es crucial en Kafka Streams, y se distinguen tres tipos principales:
-
Event time: Momento en el que se produjo un evento o registro de datos, es decir, cuando se creó originalmente "en la fuente". Ejemplo: Si el evento es un cambio de geo-localización reportado por un sensor GPS en un coche, entonces el evento-tiempo asociado sería el momento en que el sensor GPS capturó el cambio de localización
-
Processing time: El momento en que el evento o registro de datos es procesado por la aplicación, es decir, cuando el registro está siendo consumido. El tiempo de procesamiento puede ser milisegundos, horas o días, etc. más tarde que el tiempo del evento original. Ejemplo: Imaginemos una aplicación analítica que lee y procesa los datos de geolocalización notificados por los sensores de los coches para presentarlos en un cuadro de mandos de gestión de flotas. En este caso, el tiempo de procesamiento en la aplicación analítica podría ser de milisegundos o segundos (por ejemplo, para canalizaciones en tiempo real basadas en Apache Kafka y Kafka Streams) o de horas (por ejemplo, para canalizaciones por lotes basadas en Apache Hadoop o Apache Spark) después del momento del evento.
-
Ingestion time: El punto en el tiempo cuando un evento o registro de datos es almacenado en una partición de topic por un broker Kafka. La diferencia con el tiempo de evento es que esta marca de tiempo de ingestión se genera cuando el broker Kafka añade el registro al topic de destino, no cuando el registro se crea "en el origen". La diferencia con el tiempo de procesamiento es que el tiempo de procesamiento es cuando la aplicación de procesamiento de stream procesa el registro. Por ejemplo, si un registro nunca se procesa, no hay noción de tiempo de procesamiento para él, pero sigue teniendo un tiempo de ingestión. Podríamos resumirlo como el momento en que el evento es añadido al log de Kafka.
3. Ejemplo 6. Demo KStreams¶
Como hemos comentado, Kafka Streams combina la simplicidad de escribir y desplegar aplicaciones Java y Scala estándar en el lado del cliente con los beneficios de la tecnología de clúster del lado del servidor de Kafka para hacer estas aplicaciones altamente escalables, elásticas, tolerantes a fallos, distribuidas y mucho más.
Realizaremos una demo con la aplicación WordCount (convertido para utilizar expresiones Java 8 lambda para facilitar la lectura)
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream(
"streams-plaintext-input",
Consumed.with(stringSerde, stringSerde)
);
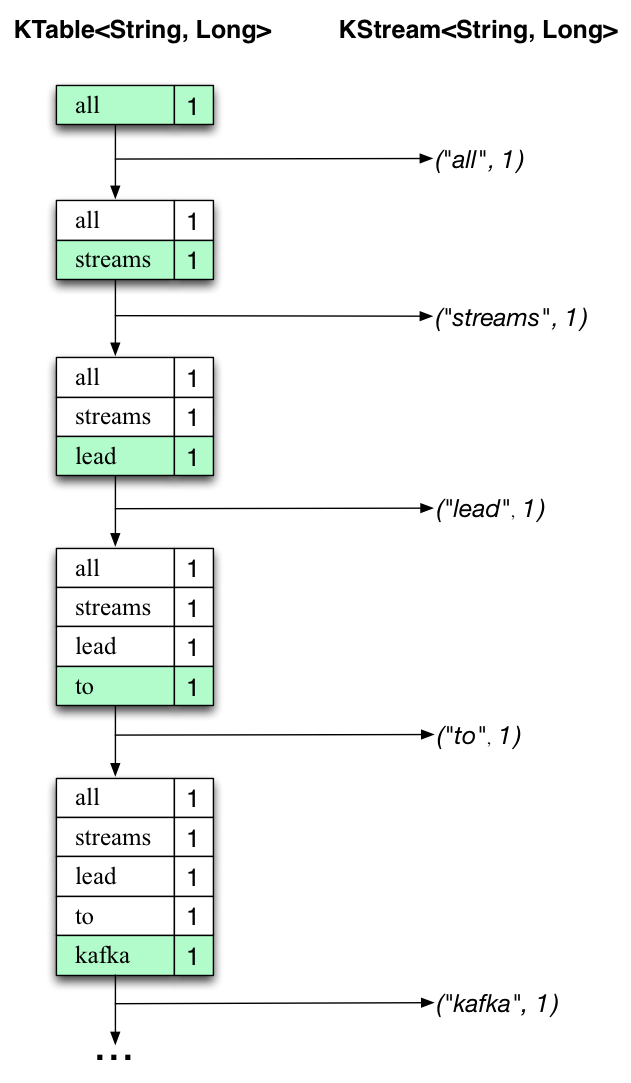
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count();
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
-
Aprovecharemos nuestra configuración de un cluster Kafka realizada en el ejemplo 2, pero en esta ocasión cambiaremos los puertos de escucha del controller(9094) y del broker1(9092) y broker2(9093). Puedes usar el ejemplo de un sólo nodo si lo crees conveniente
-
Creamos los directorios necesarios para nuestro
ejemplo6
- Hacemos 2 y 1 copia de los ficheros correspondientes de configuración para cada uno
cp config/controller.properties /opt/kafka/ejemplo6/config/controller1.properties
cp config/broker.properties /opt/kafka/ejemplo6/config/broker1.properties
cp config/broker.properties /opt/kafka/ejemplo6/config/broker2.properties
- Asignamos la configuración al controller
# Server Basics
process.roles=controller
node.id=1
controller.quorum.bootstrap.servers=localhost:9094
# Socket Server Settings
listeners=CONTROLLER://:9093
advertised.listeners=CONTROLLER://localhost:9094
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo6/logs/controller1
- Asignamos la siguiente configuración para cada broker
- Iniciamos Kafka
#Genera un cluster UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
echo $KAFKA_CLUSTER_ID
#Formateamos los directorios de log
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID --standalone -c /opt/kafka/ejemplo6/config/controller1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo6/config/broker1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo6/config/broker2.properties
- Iniciamos los servers(1 controller y 2 brokers) cada uno en una terminal
#Ejecuta el servidor Kafka
bin/kafka-server-start.sh /opt/kafka/ejemplo6/config/controller1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo6/config/broker1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo6/config/broker2.properties
- Topic de entrada
streams-plaintext-input
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 2 \
--partitions 2 \
--topic streams-plaintext-input
- Topic de salida
streams-wordcount-output
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 2 \
--partitions 2 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
- Vemos la descripción de los topics:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
Topic: streams-wordcount-output TopicId: aMxC8-rXTzOoAPzvGrm-qA PartitionCount: 2 ReplicationFactor: 2 Configs: cleanup.policy=compact,segment.bytes=1073741824
Topic: streams-wordcount-output Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: streams-wordcount-output Partition: 1 Leader: 3 Replicas: 3,2 Isr: 3,2 Elr: LastKnownElr:
Topic: streams-plaintext-input TopicId: t1-QB0dWSmCrqdszEFAuSQ PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: streams-plaintext-input Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2 Elr: LastKnownElr:
Topic: streams-plaintext-input Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
- Iniciamos la aplicación
La aplicación leerá los flujos del topic streams-plaintext-input, realizará los cálculos del algoritmo WordCount en cada uno de los mensajes leídos, y escribirá continuamente sus resultados actuales en el topic streams-wordcount-output. Por lo tanto, no habrá ninguna salida STDOUT excepto las entradas de registro, ya que los resultados se escriben de nuevo en Kafka.
- Usamos Consumer API para ver como se consume el stream cuando empecemos a producir datos.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter org.apache.kafka.tools.consumer.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
- Usamos Producer API para generar las palabras a contar por
WordCount
Y producimos datos en consola
- Vemos la salida en consumer API
- Seguimos produciendo datos en Producer API.
- Observamos los datos de nuevo los datos ya procesados y consumidos
- Más datos a producir
- Datos procesados y consumidos
En este ejemplo, ejecutaremos una aplicación de demostración llamada WordCountDemo que viene pre-compilada en los binarios de Kafka. Esta aplicación lee líneas de texto de un topic, las divide en palabras y cuenta las ocurrencias de cada palabra en tiempo real, escribiendo el resultado en otro topic.
No necesitamos copiarla en ningún sitio, ya que viene pre-compilada en los binarios de Kafka. Sin embargo, si quieres ver el código fuente de esta aplicación, puedes encontrarlo en el repositorio oficial de Kafka en GitHub. Aquí tienes el enlace directo al archivo WordCountDemo.java:
# Código de la aplicación WordCountDemo de la versión 4.2.0 (Fuente: kafka.apache.org)
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.kafka.streams.examples.wordcount;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/**
* Demonstrates, using the high-level KStream DSL, how to implement the WordCount program
* that computes a simple word occurrence histogram from an input text.
* <p>
* In this example, the input stream reads from a topic named "streams-plaintext-input", where the values of messages
* represent lines of text; and the histogram output is written to topic "streams-wordcount-output" where each record
* is an updated count of a single word.
* <p>
* Before running this example you must create the input topic and the output topic (e.g. via
* {@code bin/kafka-topics.sh --create ...}), and write some data to the input topic (e.g. via
* {@code bin/kafka-console-producer.sh}). Otherwise you won't see any data arriving in the output topic.
*/
public final class WordCountDemo {
public static final String INPUT_TOPIC = "streams-plaintext-input";
public static final String OUTPUT_TOPIC = "streams-wordcount-output";
static Properties streamsConfig(final String[] args) throws IOException {
final Properties props = new Properties();
if (args != null && args.length > 0) {
try (final FileInputStream fis = new FileInputStream(args[0])) {
props.load(fis);
}
if (args.length > 1) {
System.out.println("Warning: Some command line arguments were ignored. This demo only accepts an optional configuration file.");
}
}
props.putIfAbsent(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.putIfAbsent(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.putIfAbsent(StreamsConfig.STATESTORE_CACHE_MAX_BYTES_CONFIG, 0);
props.putIfAbsent(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.StringSerde.class);
props.putIfAbsent(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.StringSerde.class);
// setting offset reset to earliest so that we can re-run the demo code with the same pre-loaded data
// Note: To re-run the demo, you need to use the offset reset tool:
// https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Application+Reset+Tool
props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
static void createWordCountStream(final StreamsBuilder builder) {
final KStream<String, String> source = builder.stream(INPUT_TOPIC);
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}
public static void main(final String[] args) throws IOException {
final Properties props = streamsConfig(args);
final StreamsBuilder builder = new StreamsBuilder();
createWordCountStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
- Utilizaremos nuestro contenedor cliente (
kafka-client) ya configurad en nuestrodocker-compose.ymlpara gestionar los topics, apuntando a cualquiera de nuestros brokers (ej.kafka-broker-1:9092).
- Creamos el topic de entrada (
streams-plaintext-input): Aquí es donde escribiremos las frases completas.
# Linux
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh \
--create \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 2 \
--partitions 2 \
--topic streams-plaintext-input
# Windows
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh --create --bootstrap-server kafka-broker-1:9092 --replication-factor 2 --partitions 2 --topic streams-plaintext-input
- Creamos el topic de salida (
streams-wordcount-output): Aquí Kafka Streams escribirá los resultados. Nota: Activamos la políticacompactpara que Kafka mantenga solo el último valor (conteo) de cada palabra, ahorrando espacio.
# Linux
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh \
--create \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 2 \
--partitions 2 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
# Windows
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh --create --bootstrap-server kafka-broker-1:9092 --replication-factor 2 --partitions 2 --topic streams-wordcount-output --config cleanup.policy=compact
- Iniciamos la aplicación KStreams: Lanzaremos la aplicación Java pre-compilada en un contenedor efímero.
Resolviendo problemas en entorno Docker
En nuestro entorno de docker, para ejecutar la aplicación Java de ejemplo WordCountDemo, nos enfrentamos dos problemas:
-
El código de ejemplo WordCountDemo de Apache tiene la dirección del servidor programada en su código fuente en el binario como localhost:9092. Como no podemos modificar el código fuente de Java compilado fácilmente para decirle que apunte a kafka-broker-1. Vamos a solucionarlo compartiendo el Namespace de Red con la configuración:
--network container:kafka-broker-1. Esto hará que el contenedor efímero que ejecuta la aplicación Java comparta la misma "burbuja de red" (namespace) que el broker. Así, cuando el código Java llame alocalhost, se estará conectando al broker correcto. -
Al ejecutar el ejemplo
WordCountDemo, para contar las palabras, Kafka Streams necesita "recordar" cuántas llevaba antes. Esa memoria (estado) no se guarda en RAM pura, se guarda en una base de datos ultrarrápida incrustada llamada RocksDB. RocksDB está escrita en C++, no en Java. Para funcionar en Java, usa una interfaz nativa (JNI). Pero la imagen de docker de Kafka es tan minimalista que no incluye las librerías estándar de C++ necesarias para ejecutar RocksDB. Por lo tanto, antes de ejecutar la aplicación Java, necesitamos instalar estas dependencias en el contenedor efímero. Para ello, usaremosapk add --no-cache libstdc++ gcompatpara instalar las librerías necesarias de C++ en el contenedor efímero antes de arrancar la aplicación Java.
# Linux
docker run -it --rm -u 0 --network container:kafka-broker-1 apache/kafka:4.2.0 \
bash -c "apk add --no-cache libstdc++ gcompat > /dev/null && echo 'Dependencias instaladas. Arrancando KStreams...' && /opt/kafka/bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo"
# Windows
docker run -it --rm -u 0 --network container:kafka-broker-1 apache/kafka:4.2.0 bash -c "apk add --no-cache libstdc++ gcompat > /dev/null && echo 'Dependencias instaladas. Arrancando KStreams...' && /opt/kafka/bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo"
- Iniciamos el consumidor usando el cliente de consola del Consumer API, pero configurando deserializadores especiales, ya que el WordCount genera datos donde la clave (Key) es un
String(la palabra) y el valor (Value) es unLong(el número 64-bit del conteo). Si no usamos estos deserializadores, veremos símbolos extraños en la pantalla.
# Linux
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-broker-1:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter org.apache.kafka.tools.consumer.DefaultMessageFormatter \
--formatter-property print.key=true \
--formatter-property print.value=true \
--formatter-property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--formatter-property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
# Windows
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka-broker-1:9092 --topic streams-wordcount-output --from-beginning --formatter org.apache.kafka.tools.consumer.DefaultMessageFormatter --formatter-property print.key=true --formatter-property print.value=true --formatter-property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --formatter-property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
- Iniciamos el productor para enviar frases a contar usando Producer API
# Linux
docker exec -it kafka-client /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server kafka-broker-1:9092 \
--topic streams-plaintext-input
# Windows
docker exec -it kafka-client /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server kafka-broker-1:9092 --topic streams-plaintext-input
- Y producimos datos en consola
- Vemos la salida en consumer API
- Seguimos produciendo datos en Producer API.
- Observamos los datos de nuevo los datos ya procesados y consumidos
- Más datos a producir
- Datos procesados y consumidos