UD 7 - Apache Kafka¶
En los últimos años el número de aplicaciones a desarrollar por las empresas ha aumentado considerablemente con la llegada de las arquitecturas basadas en microservicios y sistemas de Big Data.
Uno de los aspectos más relevantes es la comunicación entre ellos, o la necesidad de tener que integrarse con otros sistemas enviando o recibiendo información. En estos casos, estas comunicaciones deberán ser rápidas, seguras y fiables con una alta disponibilidad.
Una de las soluciones para solventar este tipo de casos han supuesto el uso de tecnologías basadas en colas de mensajes, las cuales permiten la comunicación asíncrona, lo que significa que los puntos de conexión que producen y consumen los mensajes interactúan con la cola, no entre sí. Además, ayudan a simplificar de forma significativa la escritura de código para aplicaciones desacopladas, mejorando el rendimiento, la fiabilidad y la escalabilidad.
A la hora de utilizar un sistema de colas de mensajes que requieren la transmisión de datos a tiempo real encontramos Apache Kafka como una de nuestras mejores soluciones.
Según Apache Kafka, más del 80% de todas las empresas del 100 Fortune confían y usan Kafka. Puedes ver la lista en su página oficial
1. ¿Qué es Apache Kafka?¶
1.1 Definición¶
Apache Kafka es un sistema de transmisión de datos distribuido con capacidad de escalado horizontal y tolerante a fallos. Gracias a su alto rendimiento nos permite transmitir datos en tiempo real utilizando el patrón de mensajería publish/subscribe.
Kafka fue creado por LinkedIn y actualmente es un proyecto open source mantenido por Confluent, empresa que está bajo la administración de Apache. Apache Kafka está escrito en Java y Scala y se distribuye con licencia Apache 2.0
Proporciona la plataforma para publicar y suscribirse a flujos de eventos y permite almacenar estos eventos de una forma tolerante a fallos, escalable, persistente y con capacidad de replicación.
Además de almacenar estos eventos, la funcionalidad se extiende con la capacidad de procesarlos en tiempo real, a medida que se reciben de múltiples fuentes de datos. Kafka se integra con numerosas tecnologías, de esta forma, permite construir flujos de datos en tiempo real entre distintos sistemas y aplicaciones de manera desacoplada.
Por estas razones, Apache Kafka es muy popular en la arquitectura Big Data de muchas empresas en la actualidad. Debido a su arquitectura, consigue obtener una baja latencia, escalabilidad horizontal y absorber los picos de carga que pueden ocurrir en el sistema.
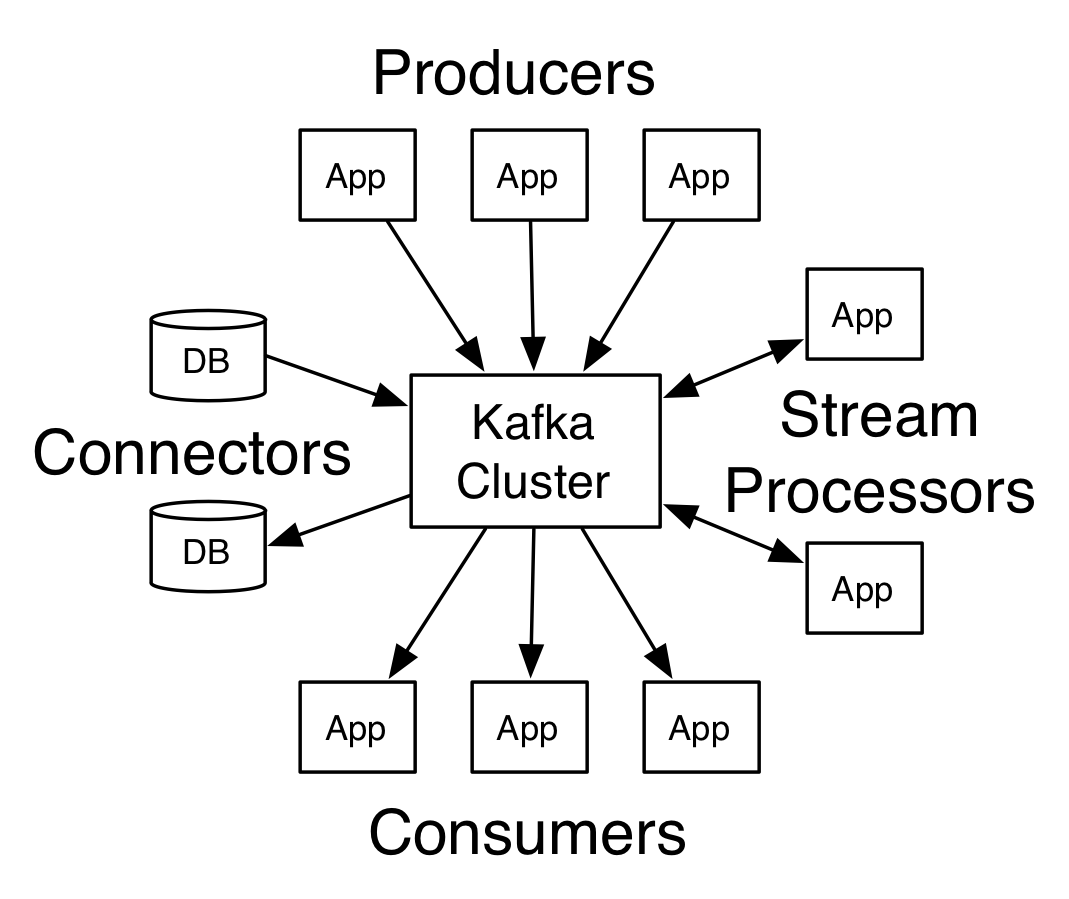
Hoy día, existe una gran variedad de fuentes generadoras de datos, tales como microservicios, bases de datos, todo tipo de IoTs, servidores web, registros de logs, análisis de rendimiento y monitoreo, etc. Kafka interviene en este punto para simplificar la arquitectura: vincula a todos los productores de datos con Kafka y, a su vez, Kafka se encarga de distribuir estos datos a los consumidores pertinentes, facilitando así un ecosistema de datos más ágil y desacoplado. Todo ello de una forma tolerante a fallos, escalable, persistente, con capacidad de replicación, baja latencia, escalabilidad horizontal y con capacidad de absorción de los picos de carga.
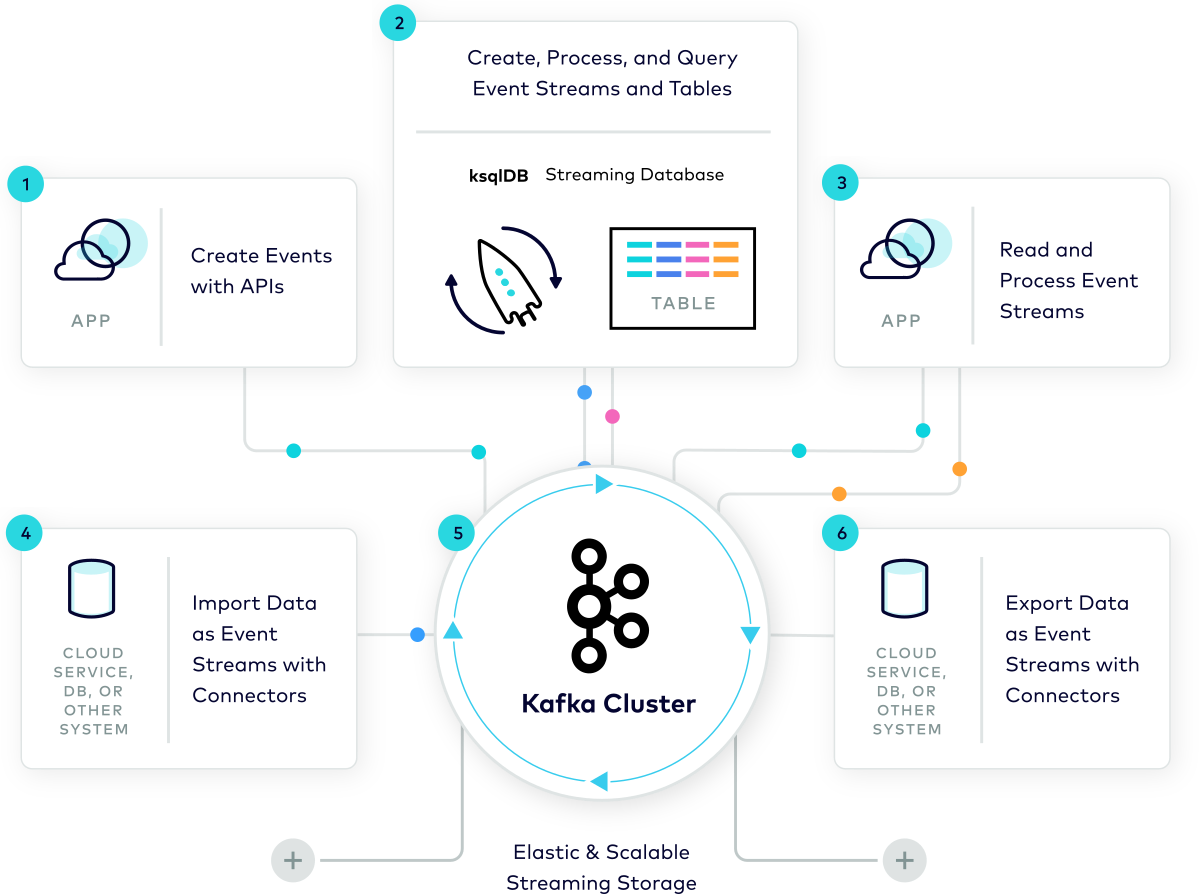
1.2 Plataforma de transmisión de eventos¶
Apache Kafka® es una plataforma de transmisión de eventos. ¿Qué significa eso?
Kafka combina tres capacidades clave para que pueda implementar sus casos de uso para la transmisión de eventos de un extremo a otro con una única solución:
- Para publicar (escribir) y suscribirse (leer) a transmisiones de eventos, incluida la importación/exportación continua de sus datos desde otros sistemas.
- Para almacenar transmisiones de eventos de forma duradera y confiable durante el tiempo que desee.
- Para procesar flujos de eventos a medida que ocurren o de forma retrospectiva.
Y toda esta funcionalidad se proporciona de forma distribuida, altamente escalable, elástica, tolerante a fallos y segura. Kafka se puede implementar en hardware básico, máquinas virtuales y contenedores, tanto en las instalaciones como en la nube. Puede elegir entre autoadministrar sus entornos Kafka y utilizar servicios totalmente administrados ofrecidos por una variedad de proveedores.
2. Elementos Kafka¶
Apache Kafka esta formado por una serie de conceptos y elementos que describiremos a continuación
2.1 Eventos¶
Un evento (También llamados registros o mensajes) registra el hecho de que "algo sucedió" en el mundo o en su negocio. Cuando lees o escribes datos en Kafka, lo haces en forma de eventos. Conceptualmente, un evento tiene una clave, un valor, una marca de tiempo(timestamp) y encabezados de metadatos opcionales. Aquí hay un evento de ejemplo:
- Clave del evento: "Alicia"
- Valor del evento: "Se realizó un pago de $200 a Bob"
- Marca de tiempo del evento: "25 de marzo de 2024 a las 14:06"
Eventos de ejemplo son transacciones de pago, actualizaciones de geolocalización desde teléfonos móviles, pedidos de envío, mediciones de sensores desde dispositivos IoT o equipos médicos, y mucho más.
2.2 Producers/Consumers¶
Los producers(productores) son aquellas aplicaciones cliente que publican (escriben) eventos en Kafka, y los consumers(consumidores) son aquellos que se suscriben (leen y procesan) estos eventos. En Kafka, los productores y los consumidores están completamente desacoplados y son agnósticos entre sí, lo cual es un elemento de diseño clave para lograr la alta escalabilidad por la que Kafka es conocido. Por ejemplo, los productores nunca necesitan esperar a los consumidores. Kafka ofrece varias garantías, como la capacidad de procesar eventos exactamente una vez (events exactly-once).

2.3 Topics¶
Los eventos se organizan y almacenan de forma duradera en topics (temas). De manera muy simplificada, un topic es similar a una carpeta en un sistema de archivos y los eventos son los archivos en esa carpeta. Un nombre de topic de ejemplo podría ser "pagos/payments". Los topics en Kafka son siempre multiproductor y multisuscriptor: un topic puede tener cero, uno o muchos productores que le escriban eventos, así como cero, uno o muchos consumidores que se suscriban a estos eventos.
Los eventos de un topic se pueden leer tantas veces como sea necesario; a diferencia de los sistemas de mensajería tradicionales, los eventos no se eliminan después de su consumo. En su lugar, se define durante cuánto tiempo Kafka debe retener sus eventos a través de una configuración por topic, después del cual se descartarán los eventos antiguos. El rendimiento de Kafka es efectivamente constante con respecto al tamaño de los datos, por lo que almacenar datos durante un período prolongado también podría ser correcto.
2.4 Partitions¶
Los topics están divididos, lo que significa que un topic se distribuye en varios "bucket(depósitos)" ubicados en diferentes brokers (veremos más adelante) de Kafka.
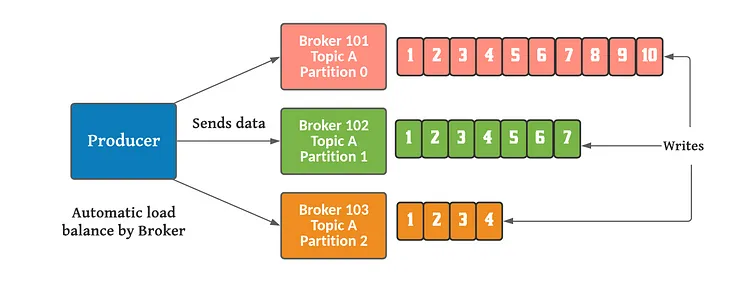
Esta ubicación distribuida de sus datos es muy importante para la escalabilidad porque permite que las aplicaciones cliente lean y escriban datos desde/hacia muchos brokers al mismo tiempo. Cuando se publica un nuevo evento en un topic, en realidad se agrega a una de las particiones del topic. Los eventos con la misma clave de evento (por ejemplo, un ID de cliente o de vehículo) se escriben en la misma partición, y Kafka garantiza que cualquier consumidor de una partición de topic determinada siempre leerá los eventos de esa partición exactamente en el mismo orden en que fueron escritos.
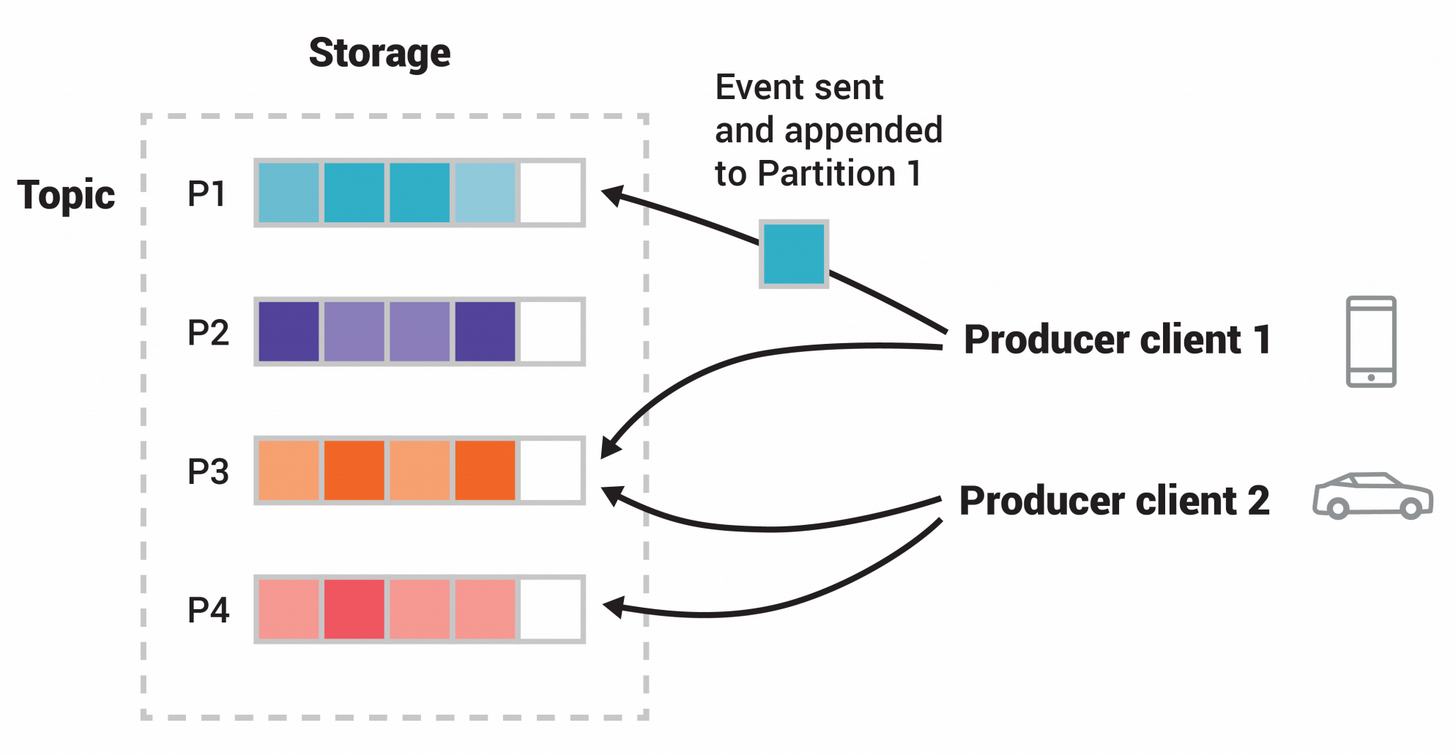
Este topic de ejemplo tiene cuatro particiones P1–P4. Dos clientes productores diferentes publican, independientemente uno del otro, nuevos eventos para el topic escribiendo eventos a través de la red en las particiones del topic. Los eventos con la misma clave (indicados por su color en la figura) se escriben en la misma partición. Tengamos en cuenta que ambos productores pueden escribir en la misma partición si corresponde.
2.5 Replication¶
Para que los datos sean tolerantes a fallos y tengan alta disponibilidad, cada topic se puede replicar, incluso entre regiones geográficas o centros de datos, de modo que siempre haya varios intermediarios que tengan una copia de los datos en caso de que algo salga mal, hacer mantenimiento a los brokers, etc. Una configuración de producción común es un factor de replica 3, es decir, siempre habrá tres copias de sus datos. Esta replica se realiza a nivel de particiones de topics.
3. Estructura¶
3.1 Topics, mensajes y particiones¶
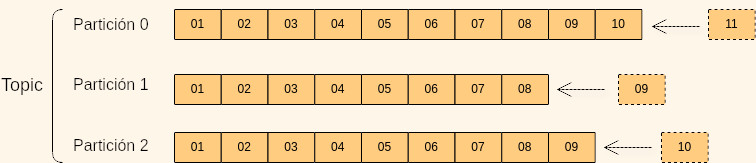
Podemos crear tantos topics como queramos y estos serán identificados por su nombre. Los topics pueden dividirse en particiones. Cada elemento que se almacena en un topic se denomina evento. Éstos son inmutables y son añadidos a una partición determinada (específica definida por la clave del mensaje o mediante round-robin en el caso de ser nula) en el orden el que fueron enviados, es decir, se garantiza el orden dentro de una partición pero no entre ellas.
Cada evento dentro de una partición tiene un identificador numérico incremental llamado offset. Con este mecanismo, se puede identificar un evento con el nombre del topic que lo contiene, la partición y el offset.
3.2 Brokers y Topics¶
Un clúster de Kafka consiste en uno o más servidores denominados Kafka brokers. Cada broker es identificado por un ID (integer) y contiene ciertas particiones de un topic, no necesariamente todas.
Además, permite replicar y particionar dichos topics balanceando la carga de almacenamiento entre los brokers. Esta característica permite que Kafka sea tolerante a fallos y escalable.
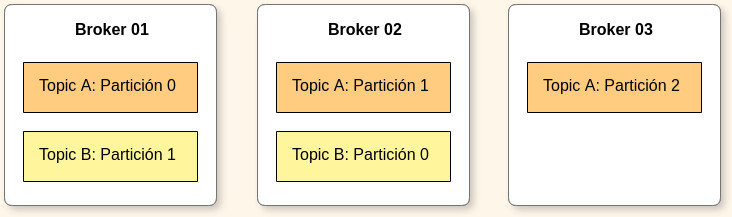
El número de particiones debería ser siempre igual o mayor que el número de brokers. Si no, habrá brokers que no estén consumiendo mensajes.
3.3 Topic replication¶
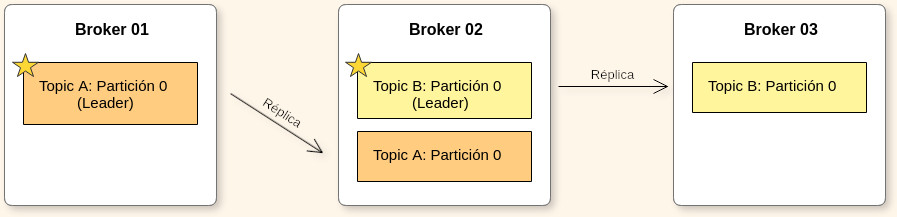
Los topics deberán tener un factor de replica mayor a 1 (normalmente 2 y 3), de esta forma si un broker se cae, otro broker puede servir los datos.
En cada momento sólo puede haber un broker líder para cada partición de un topic. Sólo el líder puede recibir y servir datos de una partición, mientras tanto los otros brokers sincronizarán sus datos como seguidores. Si este se cae, se cambia el líder.
3.4 Grupos de consumidores¶
Los consumidores de Kafka son los clientes conectados suscritos a los topics que consumen los mensajes. Cada consumidor tiene asociado un grupo de consumidores. Kafka garantiza que cada mensaje sólo es leído por un consumidor de cada grupo.
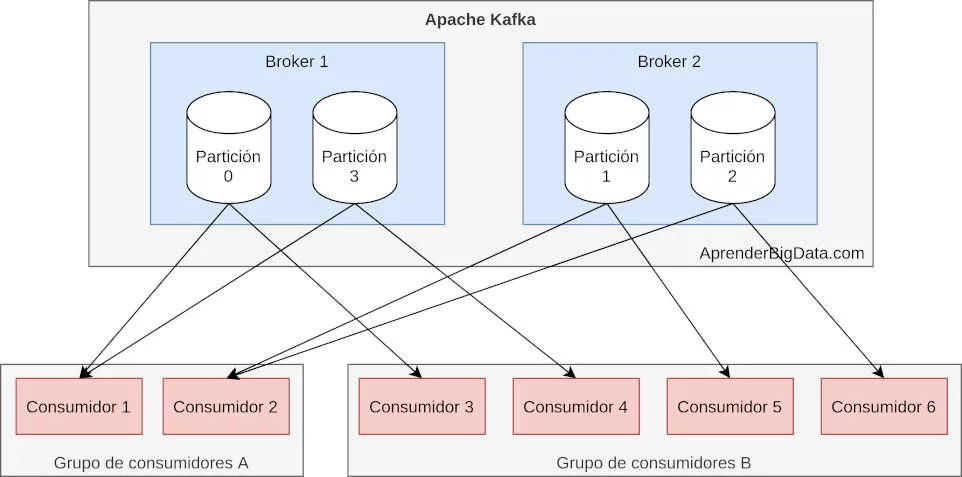
En la imagen, un cluster de kafka está formado por dos brokers con 4 particiones con dos grupos de consumidores. En el grupo de consumidores A, Kafka asigna dos particiones a cada consumidor, mientras que en el grupo B, al haber 4 consumidores para 4 particiones, es posible asignar una partición a cada consumidor.
Video resumen
Si no te ha quedado claro, puedes ver el siguiente video que explica brevemente estos conceptos
3.5 Gestión de Sistemas distribuidos¶
Para ayudar en la gestión del cluster de Kafka en este sistema distribuido, existen 2 posibles soluciones:
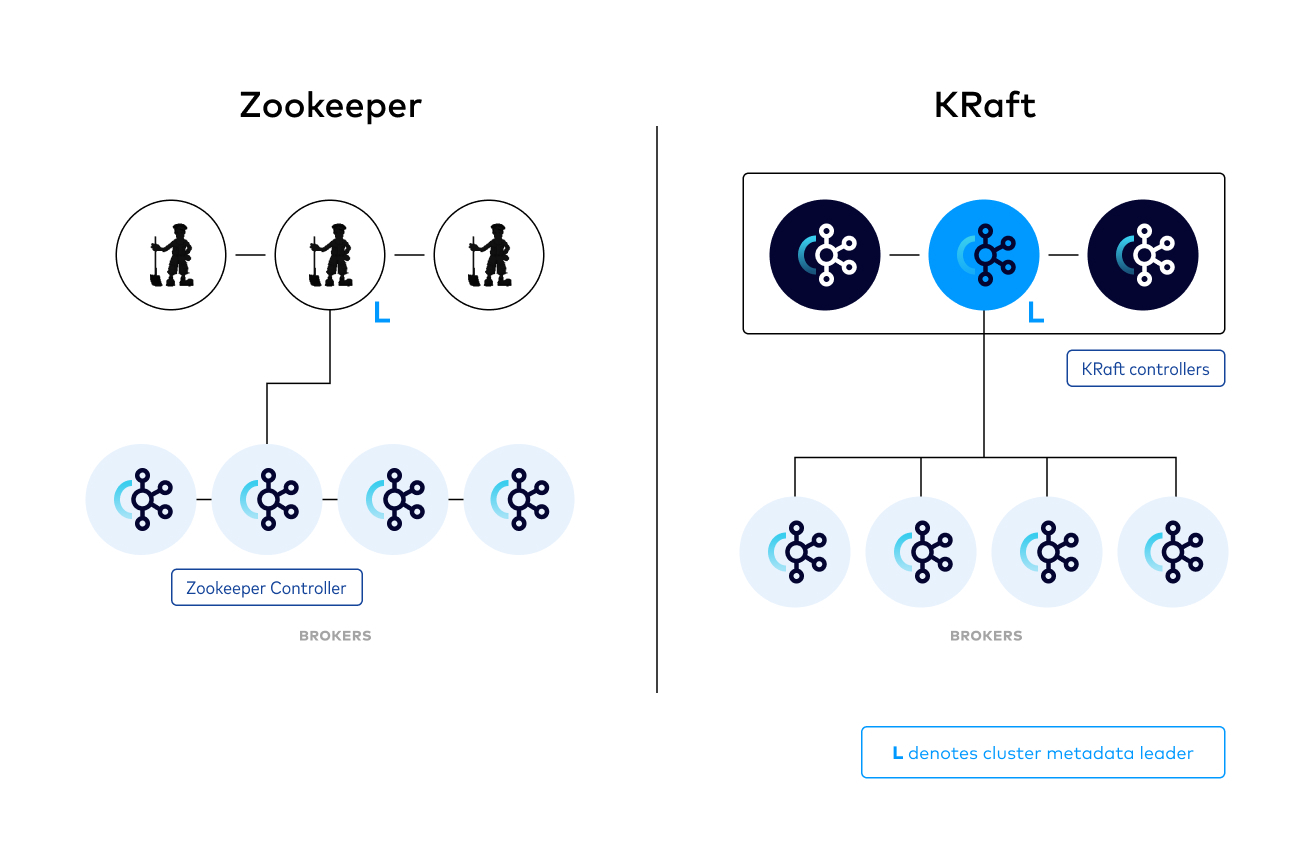
Zookeeper¶
Entre los nodos de Zookeeper, se elige uno como líder. El resto de nodos del clúster se denominan seguidores, y uno de ellos es elegido como nuevo líder en el caso de que el líder actual tenga un fallo. Generalmente, los clusters de Zookeeper se despliegan con 3 ó 5 nodos.
Para gestionar un clúster de Kafka, Zookeeper almacena información del estado del clúster: detalles de los topics como el nombre, las particiones, las réplicas y los grupos de consumidores.
En el momento en el que Zookeeper detecta que uno de los brokers de Kafka está caído, realiza las siguientes acciones:
- Elige un nuevo broker para tomar el lugar del broker caído.
- Actualiza los metadatos para la distribución de carga de los productores y los consumidores para que no exista pérdida de servicio.
Tras estas acciones, se pueden volver a escribir y leer mensajes con normalidad.
KRaft¶
Se propone eliminar la dependencia de Kafka con Zookeeper reemplazándola con un mecanismo interno. KRaft funciona como un mecanismo de consenso para el protocolo de quorum. Kafka 3.3 marca este mecanismo como listo para producción. A partir de la versión 3.5 se proporciona un mecanismo de migración y se marca el soporte a Zookeeper como deprecated.
KRaft Mode desde 4.0.0
Desde la versión 4.0.0 de Kafka, KRaft mode es el modo por defecto. No existe la versión de Zookeeper
4. Kafka APIs¶
Una vez comentada la estructura de Apache Kafka, vamos a ver cómo se interactúa con él mediante APIs
4.1 Producer API¶
Producer API permite a las aplicaciones que pueda publicar/enviar mensajes a un topic de Kafka de forma asíncrona. Los productores automáticamente saben a qué broker y a qué partición deben escribir.
En el caso de que un broker se caiga, el productor sabe cómo recuperarse y seguirá escribiendo en el resto. Los productores envían los mensajes con clave (string, número, etc) o sin ella.
Si la clave es nula se enviarán en round robin entre los brokers. Si no es nula, todos los mensajes con esa clave se enviarán siempre a la misma partición.
Además, para confirmar que los mensajes han sido correctamente escritos en Kafka se podrá configurar la recepción de un ACK, ya sea por la recepción del mensaje por parte broker líder o por todos los brokers réplica:
- ACKs=0 (El productor no espera el acuse de recibo; posible pérdida de datos)
- ACKs=1 (El productor espera el reconocimiento del líder: pérdida de datos limitada)
- ACKs=all (El productor espera al líder + reconocimiento de réplicas; sin pérdida de datos)
La carga se balancea entre los brokers
4.2 Consumer API¶
Consumer API permite a las aplicaciones que puedan leer los mensajes desde un topic de Kafka y tratarlos desde nuestra aplicación. Podemos crear un consumidor o un grupo de consumidores.
La diferencia entre ellos es que el grupo de consumidores permite el consumo de mensaje de forma paralela, es decir, si un nodo de ese grupo consume un mensaje el resto no lo hará.
Esto es útil a la hora de tener más de una instancia de un microservicio corriendo en nuestro sistema. Cada consumidor del grupo de consumidores leerá de una partición exclusiva.
Si hay más consumidores que particiones, algunos de los consumidores estarán inactivos, para solucionar esto es recomendable tener el mismo número de particiones que de consumidores dentro de un grupo.
En el caso de que un broker de los que está leyendo se caiga, los consumidores saben cómo recuperarse. Los datos son leídos en orden dentro de cada partición pero no entre ellas. Kafka almacena los offsets de los grupos de consumidores cuando estos leen los datos.
Consumer offset¶
Los offsets son almacenados en un topic de Kafka denominado “consumer_offsets”. Cuando un consumidor de un grupo lee datos de Kafka, se actualiza el offset. Kafka almacena los offsets por el que va leyendo un grupo de consumidores, a modo de checkpoint. Si un consumidor se cae, cuando vuelva a ser levantado seguirá leyendo datos desde donde se quedó anteriormente.
Cuando un consumidor de un grupo ha procesado los datos que ha leído de Kafka, realizará un commit de sus offsets. Si el consumidor se cae, podrá volver a leer los mensajes desde el último offset sobre el que se realizó commit.
Garantías de Entrega¶
Como en otros sistemas distribuidos, Kafka tiene tres maneras de gestionar las garantías de entrega de los mensajes en sus protocolos:
- At-least-once: Garantiza que el mensaje siempre se entregará. Es posible que en caso de fallo se entregue varias veces, pero no se perderá ningún mensaje en el sistema.
- At-most-once: Garantiza que el mensaje se entregará una vez o no se entregará. Un mensaje nunca se entregará más de una vez.
- Exactly-once: Garantiza que todos los mensajes se van a entregar exactamente una vez, realizando el sistema las comprobaciones necesarias para que esto suceda.
4.3 Streams API¶
Streams API permiten transformar los streams de datos desde input topics hacia output topics. Podemos realizar modificaciones (ETL) sobre los mensajes (input topics) y escribir en otro topic (output topics) actuando como productor.
Combina la "simplicidad" del desarrollo de aplicaciones en lenguaje Java o Scala con los beneficios de la integración con el cluster de Kafka.
Los veremos con má profundidad más adelante.
4.4 Connect API¶
Se tratan de componentes listos para usar que nos permiten simplificar la integración entre sistemas externos y el cluster de Kafka. Podemos crear y ejecutar productores o consumidores reutilizables que conectan los topics de Kafka a las aplicaciones o sistemas externos, como por ejemplo una base de datos.
Además, algunos permiten realizar modificaciones simples sobre los mensajes que irán a los topics de Kafka. Se configuran mediante ficheros properties o a través de su API REST y entre sus características destacan ser distribuidos y escalables.
Los veremos con más profundidad más adelante.
4.5 Admin API¶
Admin API admite la gestión e inspección de topics, brokers, ACL y otros objetos de Kafka.
5. Quick Start¶
Usando algunas de las APIs
5.1 Obtener Kafka¶
Descarga la última versión de Kafka
5.2 Configura y arranca el Entorno de Kafka¶
- Debemos tener correctamente instalado y funcionando Java 17+
Versiones de Java
Debemos tener cuidado con las versiones de Java que usa cada aplicación, ya que Apache Hadoop, de momento, tiene soporte completo sólo para Java 8. Pero como añadimos la variable de entorno de JAVA_HOME en etc/hadoop/hadoop-env.sh, no debería entrar en conflicto si instalamos una nueva versión de Java para que Kafka funcione de manera correcta.
Recuerda que puedes usar el comando sudo update-alternatives -c java para gestionar las diferentes versiones de Java del sistema.
- Movemos el directorio a nuestro directorio
/optpara una correcta organización
- Accedemos al directorio de Kafka
- Apache Kafka puede ser iniciado usando Zookeeper o KRaft
- Arranca los servicios Zookeeper
- Abre otra terminal y ejecuta
-
Kafka se puede ejecutar usando el modo KRaft mediante scripts locales y archivos descargados o mediante la imagen de docker
-
Usando los archivos descargados
- Genera un cluster UUID
- Formatea el directorio de log
- Ejecuta el servidor Kafka
-
Usando la imagen de docker
- Obtenemos la imagen de docker
- Iniciamos el contenedor docker de kafka
Una vez que el servidor Kafka se haya iniciado exitosamente, tendremos un entorno Kafka básico ejecutándose y listo para usar.
5.3 Crea un Topic para Almacenar tus eventos¶
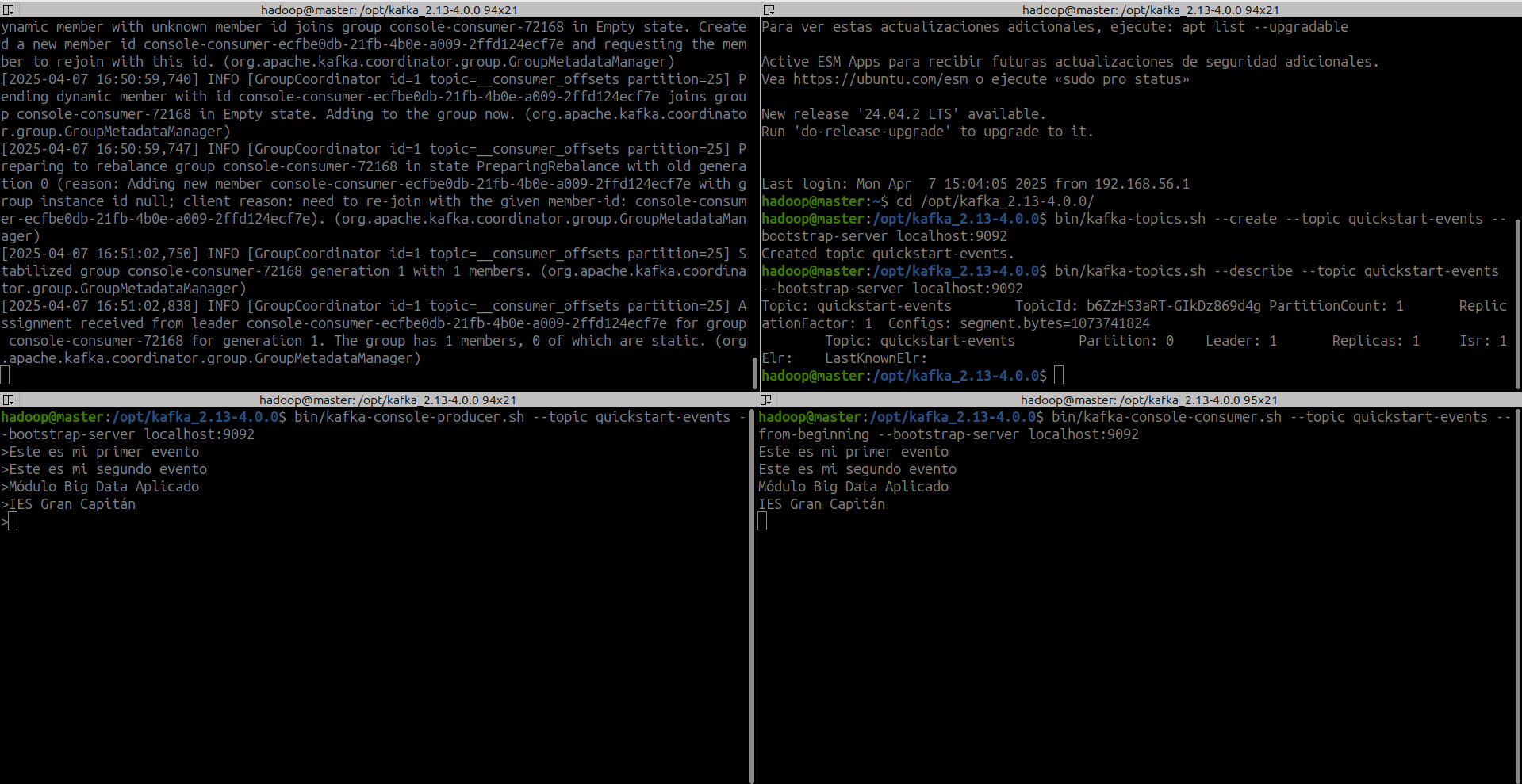
Antes de que podamos escribir nuestros primeros eventos, debemos crear un topic. Abre otra sesión de terminal y ejecute:
Argumentos en comandos de Kafka
Todos los scripts de línea de comandos de Kafka tienen opciones adicionales: para saber cuales ejecútalos sin ningún argumento para mostrar información de uso, por ejemplo: kafka-topics.sh.
También podemos mostrar los detalles y partición de un topic:
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
Topic: quickstart-events TopicId: b6ZzHS3aRT-GIkDz869d4g PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: quickstart-events Partition: 0 Leader: 1 Replicas: 1 Isr: 1Elr: LastKnownElr:
5.4 Escribe algún evento en el topic¶
Un cliente de Kafka se comunica con los brokers de Kafka a través de la red para escribir (o leer) eventos. Una vez recibidos, los brokers almacenarán los eventos de forma duradera y tolerante a fallos durante el tiempo que sea necesario, incluso para siempre.
Ejecutamos el cliente productor (Producer API) para escribir algunos eventos en el topic. De forma predeterminada, cada línea que ingresemos dará como resultado que se escriba un evento separado en el topic.
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
>Este es mi primer evento
>Este es mi segundo evento
>Módulo Big Data Aplicado
>IES Gran Capitán
Podemos parar el cliente en cualquier momento con Ctrl-C
5.5 Lee los eventos¶
Abre otra sesión de terminal y ejecute el cliente consumidor (Consumer API) de consola para leer los eventos que acabamos de crear:
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
Este es mi primer evento
Este es mi segundo evento
Módulo Big Data Aplicado
IES Gran Capitán
5.1 Obtener Kafka (Docker)¶
Obtenemos la imagen oficial de Apache Kafka de Docker Hub.(Puedes consultar la documentación de kafka para el quickstart)
¿JVM o Native?
Como puedes ver en la documentación de kafka quickstart y en las imágenes de kafka en docker hub, verás que también existe una imagen llamada apache/kafka-native. Esta versión usa GraalVM para compilar Kafka a código máquina directo.
- Ventaja: Arranca en milisegundos y gasta mucha menos RAM. Ideal para entornos Serverless o Kubernetes.
-
Nosotros usaremos: La versión estándar (
apache/kafka), que corre sobre la Máquina Virtual de Java (JVM), ya que es la más robusta para entornos de desarrollo y aprendizaje:- Estándar: Es lo que se van a encontrar en la mayoría de empresas todavía.
- Menos problemas raros: La versión nativa es muy buena, pero a veces, si el alumno tiene un procesador con arquitectura rara (ARM antiguos, etc.) o quiere hacer depuración (debugging), la versión JVM da más información y es más "transparente".
- Rendimiento a largo plazo: Aunque la nativa arranca más rápido, la versión JVM suele tener mejor rendimiento cuando lleva horas funcionando a máxima carga (el JIT de Java es muy bueno optimizando).
-
Pocos recursos: Si tienes pocos recursos en tu laboratorio o host donde estas lanzando tus contenedores, la versión nativa puede ser una buena opción para no saturar tu máquina. Pero si tu host tiene suficientes recursos, la JVM va a funcionar sin problemas.
Para información más detallada sobre las diferencias entre las versiones, sigue leyendo a continuación:
JVM vs. Native (GraalVM)
apache/kafka(JVM Based). Es la forma tradicional de ejecutar Java.
- Funcionamiento: El contenedor tiene dentro una Máquina Virtual de Java (JVM) completa (normalmente OpenJDK).
- Uso de recursos: Cuando arrancas el contenedor, la JVM tiene que "despertarse", cargar las librerías, leer el código de Kafka (que está en bytecode) y traducirlo a lenguaje máquina sobre la marcha (JIT - Just In Time).
- Ventajas: Es súper estable, compatible con todo y es el estándar de la industria para servidores que van a estar encendidos meses.
- Inconvenientes: Tarda unos segundos (o minutos) en arrancar del todo y "calentar motores". Además, consume mucha memoria RAM porque tiene que cargar toda la maquinaria de la JVM.
apache/kafka-native(GraalVM Based). Aquí entra GraalVM y la compilación AOT (Ahead-of-Time).
- Funcionamiento: Antes de crear la imagen Docker, se ha cogido el código de Kafka y se ha "pre-cocinado" (compilado) directamente a código binario nativo de Linux.
- Uso de recursos: El contenedor NO tiene JVM dentro. Es un ejecutable puro, como si fuera un programa en C++ o Go.
- Ventajas:
- Arranque Instantáneo: Pasa de 0 a 100 en milisegundos.
- Menos recursos: Consume muchísima menos RAM (a veces un 60-70% menos) porque no necesita la JVM.
- Imagen más ligera: El archivo descargado ocupa menos espacio.
- Inconvenientes: Es menos flexible si quieres inyectar código dinámico o plugins raros en tiempo de ejecución.
5.2 Configura y arranca el Entorno de Kafka (Docker)¶
Ventaja de Docker
Al usar Docker, nos olvidamos de la gestión de versiones de Java (JAVA_HOME) en nuestro sistema operativo principal. La imagen de Docker ya trae una versión de Java optimizada y compatible con Kafka 4.2.0 en su interior.
- Arrancamos el contenedor de Docker de Kafka
- Verificamos que está funcionando:
- Deberíamos ver el contenedor
kafka-testen estado "Up". Una vez que el contenedor está activo, tenemos un clúster de Kafka de un solo nodo listo para recibir datos.
5.3 Crea un Topic para Almacenar tus eventos (Docker)¶
- Antes de que podamos escribir nuestros primeros eventos, debemos crear un topic. Abre otra sesión de terminal y ejecuta:
¿Qué es ese mensaje de 'What's next'?
Es posible que al final de la ejecución veas un mensaje que dice:
What's next: Try Docker Debug for seamless...
¡Ignóralo! No es un error. Es simplemente Docker sugiriéndote herramientas avanzadas. Si ves la información de tu Topic, tu ejercicio está perfecto.
docker exec -it kafka-test /opt/kafka/bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
Argumentos en comandos de Kafka
Todos los scripts de línea de comandos de Kafka tienen opciones adicionales: para saber cuales ejecútalos sin ningún argumento para mostrar información de uso, por ejemplo: kafka-topics.sh.
También podemos mostrar los detalles y partición de un topic:
docker exec -it kafka-test /opt/kafka/bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
Topic: quickstart-events TopicId: 9yrxj4VLSOqKtRjVnBLHng PartitionCount: 1 ReplicationFactor: 1 Configs: min.insync.replicas=1,segment.bytes=1073741824
Topic: quickstart-events Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
5.4 Escribe algún evento en el topic (Docker)¶
Un cliente de Kafka se comunica con los brokers de Kafka a través de la red para escribir (o leer) eventos. Una vez recibidos, los brokers almacenarán los eventos de forma duradera y tolerante a fallos durante el tiempo que sea necesario, incluso para siempre.
Ejecutamos el cliente productor (Producer API) para escribir algunos eventos en el topic. De forma predeterminada, cada línea que ingresemos dará como resultado que se escriba un evento separado en el topic.
docker exec -it kafka-test /opt/kafka/bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
>Este es mi primer evento
>Este es mi segundo evento
>Módulo Big Data Aplicado
>IES Gran Capitán
Podemos parar el cliente en cualquier momento con Ctrl-C
5.5 Lee los eventos (Docker)¶
Abre otra sesión de terminal y ejecute el cliente consumidor (Consumer API) de consola para leer los eventos que acabamos de crear:
docker exec -it kafka-test /opt/kafka/bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
Este es mi primer evento
Este es mi segundo evento
Módulo Big Data Aplicado
IES Gran Capitán
Podemos parar el cliente en cualquier momento con Ctrl-C

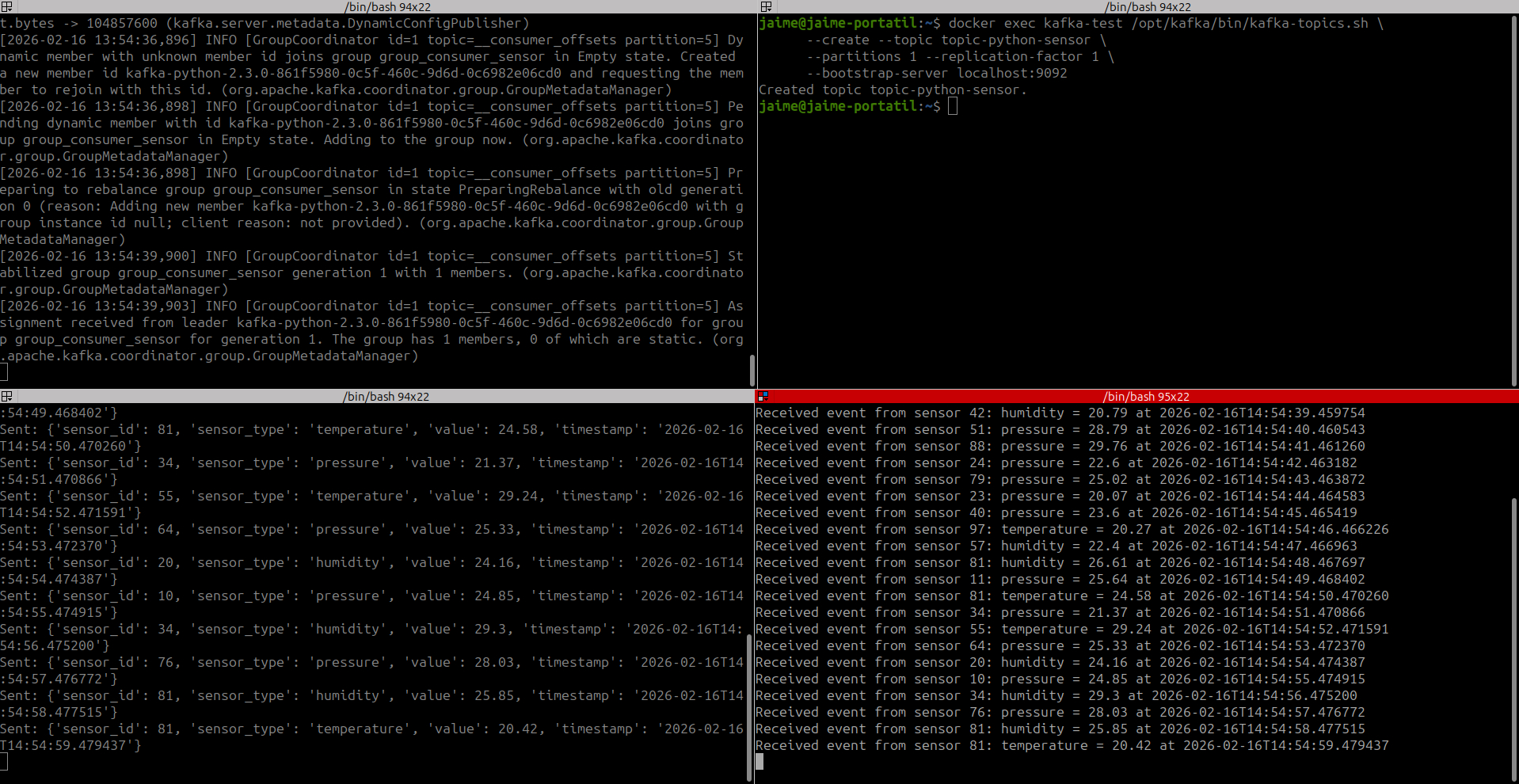
6. Ejemplo1. Python en Kafka¶
En principio, Kafka sólo tiene soporte para crear aplicaciones en lenguaje Java y Scala. Pero gracias a la librería Kafka-python, podemos crear aplicaciones en Python para ser usadas con Kafka. Para ello vamos a crear el productor a través de KafkaProducer y el consumidor a través de KafkaConsumer
Elaboraremos una pequeña aplicación para implementar un sistema de registro de eventos de sensores. En este escenario, el productor enviará eventos (simulados) que contienen lecturas de sensores en formato JSON, y el consumidor procesará estos eventos para imprimir la información.
- Instalamos la librería
- Suponemos que tendremos la siguiente configuración kafka, que crearemos después
- Servidor en
localhost:9092 - Topic llamado
topic-python-sensor -
Grupo de consumidores
group_consumer_sensor -
Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
from datetime import datetime
import random
import time
# Configuración del productor con serialización JSON
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
# Simulación de envío de eventos de sensores
while True:
sensor_event = {
'sensor_id': random.randint(1, 100),
'sensor_type': random.choice(['temperature', 'humidity', 'pressure']),
'value': round(random.uniform(20.0, 30.0), 2),
'timestamp': datetime.now().isoformat()
}
# Enviamos un mensaje
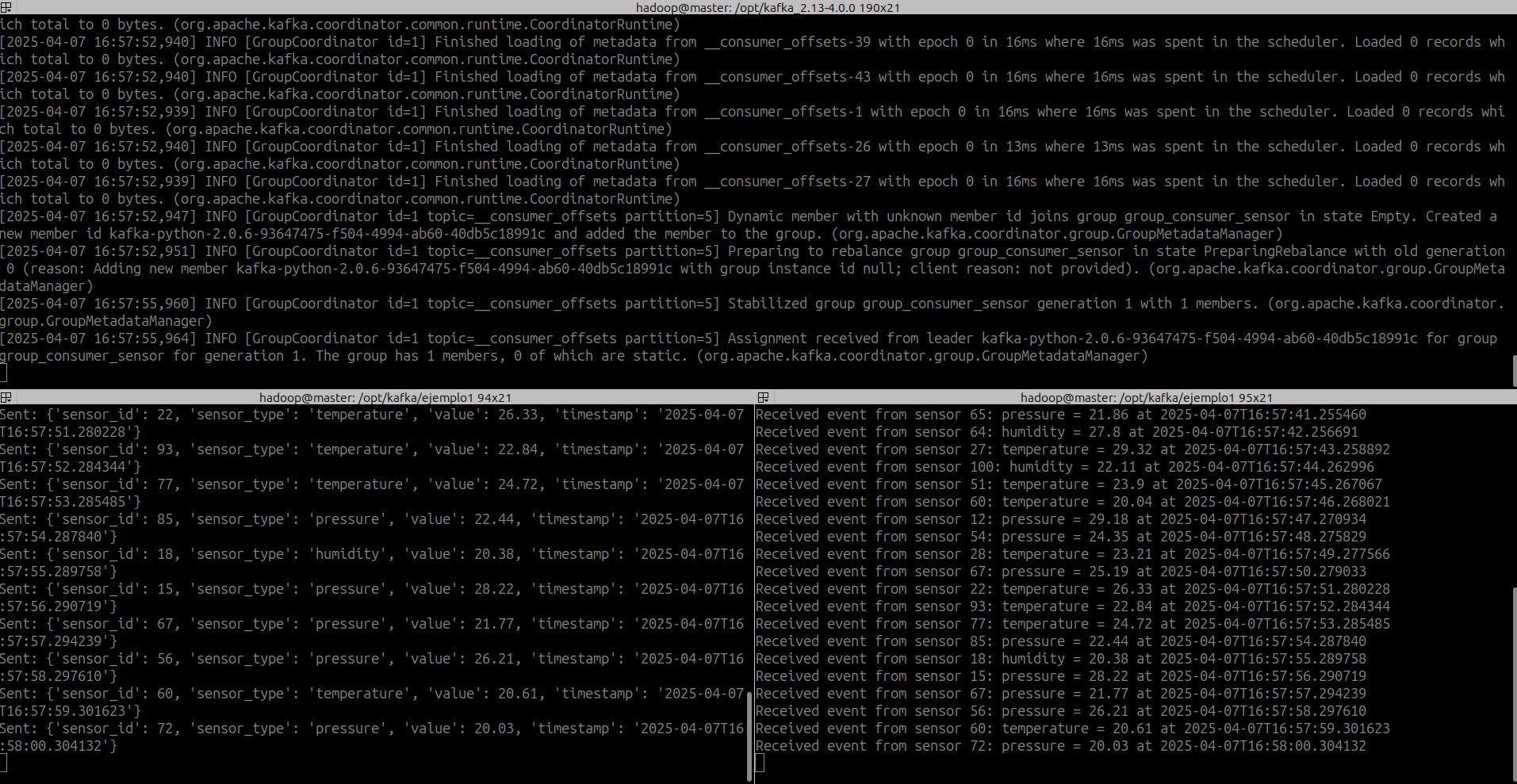
producer.send('topic-python-sensor', value=sensor_event)
print(f"Sent: {sensor_event}")
time.sleep(1)
- Creamos el productor con KafkaConsumer
from kafka import KafkaConsumer
import json
# Configuración del consumidor con deserialización JSON
consumer = KafkaConsumer(
'topic-python-sensor',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # Para leer mensajes desde el inicio del topic
enable_auto_commit=True, # Para confirmaciones automáticas
group_id='group_consumer_sensor', # Identificador del grupo de consumidores
value_deserializer=lambda x: json.loads(x.decode('utf-8')) # Para deserializar los mensajes desde JSON
)
# Procesamiento de eventos de sensores
for message in consumer:
event = message.value
print(f"Received event from sensor {event['sensor_id']}: {event['sensor_type']} = {event['value']} at {event['timestamp']}")
- Iniciamos Kafka
#Genera un cluster UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
#Si no te permite formatear (con el comando siguiente) es debido a que se mantienen los logs del ejemplo anterior. debes borrarlos
#sudo rm -r /tmp/kraft-combined-logs/
#Formatea el directorio de log
bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/server.properties
#Ejecuta el servidor Kafka
bin/kafka-server-start.sh config/server.properties
- Creamos el topic sensores
bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic topic-python-sensor --bootstrap-server localhost:9092
- Lanzamos el productor
- Lanzamos el consumidor
- Como estamos trabajando desde nuestro ordenador local (fuera de Docker), necesitamos preparar el entorno y las librerías. Por tanto, instalamos la librería
Instalación de librería kafka-python y preparación del entorno
Para no tener que estar creando un entorno para cada ejemplo, vamos a preparar el entornos instalar la librería kafka-python en una carpeta de donde colgarán todos los ejemplos/ejercicios de kafka. Así sólo tendremos que activar el entorno virtual cada vez que quieras ejecutar un ejemplo o ejercicio desde este directorio. En mi caso, crearé un directorio llamado kafka_ejemplos desde el que colgarán todos los demás. Este será tomado como referencia para el resto de ejemplos y ejercicios de kafka para su uso en cualquier editor de código o terminal (VS Code en mi caso).
- Creamos el entorno virtual e instalamos la librería en el directorio
kafka_ejemplos
mkdir kafka_ejemplos
cd kafka_ejemplos
python -m venv venv
source venv/bin/activate
pip install kafka-python
- Creamos el directorio
kafka_ejemplos/ejemplo1y dentro de él los archivosproducer.pyyconsumer.pycon el código que se muestra a continuación:
- Suponemos que tendremos la siguiente configuración kafka, que crearemos después
- Servidor en
localhost:9092 - Topic llamado
topic-python-sensor -
Grupo de consumidores
group_consumer_sensor -
Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
from datetime import datetime
import random
import time
# Configuración del productor con serialización JSON
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
# Simulación de envío de eventos de sensores
while True:
sensor_event = {
'sensor_id': random.randint(1, 100),
'sensor_type': random.choice(['temperature', 'humidity', 'pressure']),
'value': round(random.uniform(20.0, 30.0), 2),
'timestamp': datetime.now().isoformat()
}
# Enviamos un mensaje
producer.send('topic-python-sensor', value=sensor_event)
print(f"Sent: {sensor_event}")
time.sleep(1)
- Creamos el productor con KafkaConsumer
from kafka import KafkaConsumer
import json
# Configuración del consumidor con deserialización JSON
consumer = KafkaConsumer(
'topic-python-sensor',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # Para leer mensajes desde el inicio del topic
enable_auto_commit=True, # Para confirmaciones automáticas
group_id='group_consumer_sensor', # Identificador del grupo de consumidores
value_deserializer=lambda x: json.loads(x.decode('utf-8')) # Para deserializar los mensajes desde JSON
)
# Procesamiento de eventos de sensores
for message in consumer:
event = message.value
print(f"Received event from sensor {event['sensor_id']}: {event['sensor_type']} = {event['value']} at {event['timestamp']}")
- Iniciamos Kafka
docker start kafka-test
# O si lo borraste:
docker run -d --name kafka-test -p 9092:9092 apache/kafka:4.2.0
- Creamos el topic sensores
docker exec kafka-test /opt/kafka/bin/kafka-topics.sh \
--create --topic topic-python-sensor \
--partitions 1 --replication-factor 1 \
--bootstrap-server localhost:9092
- Necesitaremos 2 terminales para ejecutar el productor y el consumidor, así que abre dos terminales nuevas y activa el entorno virtual en ambas:
# Si no lo has activado antes, hazlo ahora en ambas terminales
cd kafka_ejemplos/ejemplo1
source venv/bin/activate
- Lanzamos el productor en una terminal
- Lanzamos el consumidor en otra terminal
7. Kafka on KRaft(Kafka Raft Metadata mode)¶
Como hemos visto anteriormente, recordemos que desde la versión 3.5 se elimina la dependencia de Kafka con Zookeeper y se marca el soporte de Zookeeper como deprecated, pasándose a usar de manera estable el sistema interno KRaft para la gestión del cluster de Kafka en este sistema distribuido.
El modo KRaft utiliza un nuevo servicio de controlador de quorum en Kafka que reemplaza al controlador anterior y utiliza una variante basada en eventos del protocolo de consenso Raft.
Esto nos trae ciertas consideraciones a tener en cuenta (además de otras ventajas):
- Kafka no necesita un sistema de terceros para la gestión del sistema distribuido.
- Todos los nodos del cluster son nodos Kafka, que tomarán roles diferentes dependiendo de su función en el cluster en Kraft mode:
controller,broker(como puedes ver en la figura) yserver.
Por tanto, a la hora de configurar un cluster Kafka, estos roles de cada nodo hay que configurarlos para un correcto diseño de nuestro sistema.
Dynamic KRaft Quorums
Los controladores en KRaft son nodos Kafka que utilizan el algoritmo de consenso Raft para elegir un líder (controlador activo) y replicar los metadatos del clúster. Antes de Kafka v3.9.0, los clusters basados en KRaft sólo permitían configuraciones de quórum estáticas, en las que el conjunto de nodos controladores (también conocidos como votantes) es fijo y no puede cambiarse sin reiniciar.
Kafka v3.9.0 introduce soporte para quórum dinámico con KIP-853. Esta es una de las características que faltaban para alcanzar la paridad de características con los clústeres basados en ZooKeeper. A partir de ahora, el quórum dinámico debería ser la forma preferida de configurar un clúster basado en KRaft, ya que no requiere tiempo de inactividad del clúster.
El escalado dinámico del clúster es importante para una serie de casos de uso:
- Escalado: Queremos escalar el número de controladores añadiendo o quitando un controlador (esto es bastante raro en la práctica, ya que el quórum del controlador se establece una vez y rara vez se cambia).
- Sustitución: Queremos sustituir un controlador debido a un fallo de disco o hardware.
- Migración: Necesitamos migrar el clúster de máquinas antiguas a nuevas, o cambiar la arquitectura de KRaft (por ejemplo, pasar de controladores dedicados a nodos de modo combinado).
Static versus Dynamic KRaft Quorums¶
Por tanto, ahora hay dos formas de ejecutar KRaft: la antigua, utilizando quórums de controladores estáticos, y la nueva, utilizando quórums de controladores dinámicos KIP-853.
Cuando se utiliza un quórum estático, el archivo de configuración para cada broker y controlador debe especificar los IDs, nombres de host y puertos de todos los controladores en controller.quorum.voters.
En cambio, cuando se utiliza un quórum dinámico, se debe configurar controller.quorum.bootstrap.servers. No es necesario que esta clave de configuración contenga todos los controladores, pero debe contener tantos como sea posible para que todos los servidores puedan localizar el quórum. En otras palabras, su función es muy parecida a la configuración bootstrap.servers utilizada por los clientes Kafka.
Desde la versión 4.0.0 de kafka, Dynamic Quorum es la configuración por defecto que debemos usar, y por tanto, es la que usaremos.
7.1 Roles¶
Cuando opera Apache Kafka® en modo KRaft, debemos configurar la propiedad process.roles. Esta propiedad especifica si el servidor(nodo que forma parte del cluster Kafka) actúa como controller, broker(como puedes ver en la figura) o combinado, aunque actualmente el modo combinado no es compatible con cargas de trabajo de producción.
A) Controller¶
- Role: El controller es un componente crítico en Kafka que gestiona el estado del clúster. Esto incluye, pero no se limita a, la asignación de particiones a los brokers y la gestión de los cambios en la membresía del clúster. En el modo KRaft, el controlador también gestiona el quorum y los metadatos del clúster sin depender de Zookeeper.
- Configuración: Cuando levantas un nodo en modo controller en KRaft, específicas
process.roles=controlleren la configuración. Esto indica que el nodo debe actuar exclusivamente como un controlador. - Comunicación: El controlador se comunica con los brokers para coordinar la gestión del clúster. Se configura un conjunto de votantes del quorum dinámico(
controller.quorum.bootstrap.servers) para participar en el consenso Raft.
En el modo KRaft, se seleccionan servidores Kafka específicos para que sean controladores, almacenando metadatos para el clúster en el registro de metadatos, y se seleccionan otros servidores para que sean intermediarios. Los servidores seleccionados para ser controladores participarán en el quorum de metadatos. Cada controlador es activo o de reserva activa para el controlador activo actual.
En un entorno de producción, el quorum del controlador se implementará en varios nodos. A esto se le llama ensemble. Ensemble es un conjunto de 2n + 1 controladores donde n es cualquier número mayor que 0. El número impar de controladores permite que el quorum de controladores realice elecciones mayoritarias para el liderazgo. En cualquier momento dado, puede haber hasta n servidores fallidos en un conjunto y el clúster mantendrá el quorum. Por ejemplo, con 3 controladores, el clúster puede tolerar un fallo de controlador. Si en algún momento se pierde el quorum, el clúster dejará de funcionar. Actualmente, no se recomiendan más de 3 controladores en entornos críticos.
B) Broker¶
- Role: Los brokers son los nodos que realmente almacenan y sirven datos (es decir, los mensajes de Kafka) a los productores y consumidores. En un clúster de Kafka, puedes tener muchos brokers para escalar horizontalmente el rendimiento y la capacidad de almacenamiento.
- Configuración: Levantar un nodo en modo broker en KRaft implica configurar
process.roles=brokeren las propiedades del nodo. Esto lo designa para servir como un broker, manejando las solicitudes de los clientes y el almacenamiento de los datos. - Comunicación: Los brokers se registran con el controlador y siguen sus instrucciones para la asignación de particiones y otras tareas de gestión del clúster. Los brokers no participan directamente en el consenso Raft; solo el controlador gestiona los metadatos del clúster.
C) Combinado¶
- Role: En algunos contextos, especialmente en entornos de desarrollo o pruebas, puedes querer que un nodo actúe tanto como controlador como broker. Esto simplifica la configuración y reduce la cantidad de recursos necesarios, ya que no es necesario ejecutar nodos separados para los roles de controlador y broker.
- Configuración: Para levantar un nodo en modo combinado (server), configuras
process.roles=broker,controlleren las propiedades del nodo. Esto indica que el nodo debe asumir ambos roles. - Comunicación: Como este nodo combina ambos roles, gestionará tanto los metadatos del clúster como el almacenamiento y la transmisión de los datos de los mensajes.
Resumen¶
- Controller: Gestiona el estado del clúster y los metadatos, no almacena ni sirve datos de los mensajes.
- Broker: Almacena y sirve datos de los mensajes, pero no gestiona los metadatos del clúster directamente.
- Combinado: Realiza ambas funciones, tanto la gestión de metadatos del clúster como el almacenamiento y servicio de los datos de los mensajes, útil para configuraciones simplificadas.
Al configurar un clúster Kafka en modo KRaft, es importante planificar el número y tipo de nodos según los requisitos de escala, rendimiento y alta disponibilidad de tu aplicación o sistema.
A continuación, vamos a ver algunos de las configuraciones más importantes y de uso más frecuente para una correcta configuración de nuestro cluster Kafka en Kraft mode teniendo en cuenta los posibles roles de cada uno de los servers que componen el cluster.
7.2 Server Basic¶
7.2.1 process.roles¶
Como ya hemos visto, puede tener los siguientes valores: controller, broker,controller,broker.
- Type: string
- Default:
- Importance: required for KRaft mode
7.2.2 node.id¶
El identificador único de este servidor. Cada ID de nodo debe ser único en todos los servidores de un clúster en particular. No hay dos servidores que puedan tener el mismo ID de nodo independientemente de su valor de process.roles. Este identificador reemplaza a broker.id, que se utiliza cuando se opera en modo ZooKeeper.
- Type: int
- Default:
- Importance: required for KRaft mode
7.2.3 controller.quorum.bootstrap.servers¶
Todos los servidores (controllers y brokers) en un clúster de Kafka deben establecer la propiedad controller.quorum.bootstrap.servers, debido a que todos deben descubrir los votantes del quórum. Por tanto, debemos identificar a todos los controllers incluyéndolos en la lista que proporciona esta propiedad controller.quorum.bootstrap.servers, separados por comas.
Además, todos los controladores deben estar enumerados. Cada controlador se identifica con su información de host y puerto con el siguiente formato: {host}:{port}. Varias entradas estarán separadas por comas y pueden tener un aspecto similar al siguiente:
Por ejemplo, si un clúster Kafka tiene 3 controladores denominados controller1, controller2 y controller3, entonces el controller1 tendría la siguiente configuración:
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.bootstrap.servers=controller1.example.com:9093,controller2.example.com:9093,controller3.example.com:9093
controller.listener.names=CONTROLLER
- Type: string
- Default:
- Importance: required for KRaft mode
Cada broker y controller deben establecer la propiedad controller.quorum.bootstrap.servers.
7.3 Socket Server Settings¶
7.3.1 listeners¶
Los servidores Kafka admiten la escucha (listening) de conexiones en varios puertos. Esto se configura a través de la propiedad listeners en la configuración del servidor, que acepta una lista separada por comas de los listeners habilitados. Debe definirse al menos una escucha en cada servidor. El formato de cada listener definido en listeners es el siguiente: {LISTENER_NAME}://{hostname}:{port}.
LISTENER_NAME suele ser un nombre descriptivo que define el propósito de la escucha. Por ejemplo, muchas configuraciones utilizan un listener independiente para el tráfico de clientes, por lo que podrían referirse al listener correspondiente como CLIENT en la configuración:
Hostname config
Si no se configura el nombre del host, este será igual al valor de java.net.InetAddress.getCanonicalHostName() con el nombre de listener PLAINTEXT, y el puerto 9092. Por ejemplo, ocurre cuando dejamos la configuración listeners=PLAINTEXT://:9092
Para más información sobre la seguridad de la comunicación entre las conexiones de escucha, consulta la documentación oficial
- Type: string with the format
listener_name://host_name:port - Default: If not configured, the host name will be equal to the value of
java.net.InetAddress.getCanonicalHostName(), withPLAINTEXTlistener name, and port9092. Example:listeners=PLAINTEXT://your.host.name:9092 - Importance: high
Por otro lado, el protocolo de seguridad de cada oyente (listener) se define en una configuración independiente: listener.security.protocol.map.
7.3.2 listener.security.protocol.map¶
Como hemos dicho, el protocolo de seguridad de cada oyente se define en esta configuración. El valor es una lista separada por comas de cada listener mapeado a su protocolo de seguridad. Por ejemplo, la siguiente configuración de valores especifica que el listener CLIENT utilizará SSL mientras que el listener BROKER utilizará plaintext.
A continuación se indican las opciones posibles (sin distinguir mayúsculas de minúsculas) para el protocolo de seguridad:
- PLAINTEXT
- SSL
- SASL_PLAINTEXT
- SASL_SSL
El protocolo de texto plano (PLAINTEXT) no proporciona seguridad y no requiere ninguna configuración adicional. Puedes mirar la documentación oficial que indica como configurar los demás protocolos.
Si cada oyente (listener) necesario utiliza un protocolo de seguridad distinto, también es posible utilizar el nombre del protocolo de seguridad como nombre del oyente en los oyentes. Usando el ejemplo anterior, podríamos omitir la definición de los escuchadores CLIENT y BROKER usando la siguiente definición:
Sin embargo, recomendamos a los usuarios que proporcionen nombres explícitos para los escuchadores (listeners) ya que lo hace más descriptivo e intuitivo para su configuración.
7.3.3 controller.listener.names¶
Una lista separada por comas de entradas listener_name para los listeners utilizados por el controller. En un nodo con process.roles=broker, sólo el primer listener de la lista será utilizado por el broker. Para controladores KRaft en modo aislado o combinado, el nodo escuchará como controlador KRaft en todos los listeners que estén listados para esta propiedad, y cada uno debe aparecer en la propiedad listeners.
- Type: string
- Default: null
- Importance: required for KRaft mode.
7.4 Log Basics¶
7.4.1 log.dir¶
Directorio en el que se guardan los datos de registro (complementario por la propiedad log.dirs)
- Type: string
- Default:
/tmp/kafka-logs - Importance: high
7.4.2 log.dirs¶
Lista separada por comas de los directorios donde se almacenan los datos de registro. Si no se define, se utiliza el valor de log.dir
- Type: string
- Default: null
- Importance: high
7.4.3 num.partitions¶
El número por defecto de particiones de registro por topic. Más particiones permiten un mayor paralelismo para el consumo, pero esto también resultará en más archivos a través de los brokers. Establece esta configuración sólo para los brokers. Esto será ignorado por los controladores KRaft.
- Type: int
- Default: 1
- Importance: medium
7.4.4 metadata.log.dir¶
Se utiliza para especificar dónde se aloja el registro de metadatos de los clusters en modo KRaft. Si no se establece, el registro de metadatos se coloca en el primer directorio de registro especificado en la propiedad log.dirs.
- Type: string
- Default: null
- Importance: high
7.5 Otras configuraciones¶
Para consultar el resto de propiedades puedes consultar la documentación oficial
7.6 Kraft Storage - Provisioning Nodes¶
El comando bin/kafka-storage.sh random-uuid se utilizaa para generar un ID de clúster para tu nuevo clúster. Este ID de clúster debe utilizarse al formatear cada servidor del clúster con el comando bin/kafka-storage.sh format.
Esto es diferente de cómo Kafka ha operado en el pasado. Anteriormente, Kafka formateaba automáticamente los directorios de almacenamiento vacíos y también generaba automáticamente un nuevo ID de clúster. Uno de los motivos de este cambio es que el formateo automático a veces puede ocultar una condición de error. Esto es particularmente importante para el registro de metadatos mantenido por los servidores controllers y brokers. Si la mayoría de los controllers pudieran comenzar con un directorio de registro vacío, podría elegirse un líder con datos comprometidos faltantes.
7.6.1 Bootstrap a Standalone Controller¶
El método recomendado para crear un nuevo cluster de controllers KRaft es arrancarlo con un votante (parámetro --standalone) y añadir dinámicamente el resto de controllers. El arranque del primer controlador se puede hacer con el siguiente comando CLI:
bin/kafka-storage.sh format --cluster-id <CLUSTER_ID> --standalone --config config/controller.properties
- creará un archivo meta.properties en metadata.log.dir con un directory.id generado aleatoriamente.
- creará una instantánea en 00000000000000000000-0000000000.checkpoint con los registros de control necesarios (KRaftVersionRecord y VotersRecord) para que este nodo Kafka sea el único votante para el quórum.
7.6.2 Bootstrap with Multiple Controllers¶
La partición de metadatos del clúster de controllers KRaft también se puede arrancar con más de un votante. Esto se puede hacer utilizando el indicador --initial-controllers:
CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_0_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_1_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_2_UUID="$(bin/kafka-storage.sh random-uuid)"
# In each controller execute
bin/kafka-storage.sh format --cluster-id ${CLUSTER_ID} \
--initial-controllers "0@controller-0:1234:${CONTROLLER_0_UUID},1@controller-1:1234:${CONTROLLER_1_UUID},2@controller-2:1234:${CONTROLLER_2_UUID}" \
--config config/controller.properties
Este comando es similar a la versión standalone, pero la instantánea en 00000000000000000000-0000000000.checkpoint contendrá en su lugar un VotersRecord que incluye información para todos los controllers especificados en --initial-controllers. Es importante que el valor de esta flag sea el mismo en todos los controllers con el mismo id de cluster. En la descripción de la réplica 0@controller-0:1234:3Db5QLSqSZieL3rJBUUegA, 0 es el id de la réplica, 3Db5QLSqSZieL3rJBUUegA es el id del directorio de la réplica, controller-0 es el host de la réplica y 1234 es el puerto de la réplica.
Consulta la documentación oficial para saber más sobre como añadir o eliminar controllers en un cluster Kafka existente.
7.6.3 Formateando nuevos Brokers y Controllers¶
A la hora de aprovisionar nuevos nodos broker y controller que queramos añadir a un cluster Kafka existente, utilizaremos el comando kafka-storage.sh format con el parámetro --no-initial-controllers.
bin/kafka-storage.sh format --cluster-id <CLUSTER_ID> --config config/server.properties --no-initial-controllers
7.7 Tools for debugging KRaft mode¶
Vamos a ver algunos de ellos, los de uso más frecuente.
7.7.1 Describe runtime status¶
Puede describir el estado en tiempo de ejecución de la partición de metadatos del clúster utilizando kafka-metadata-quorum
Output might look like the following:
ClusterId: fMCL8kv1SWm87L_Md-I2hg
LeaderId: 3002
LeaderEpoch: 2
HighWatermark: 10
MaxFollowerLag: 0
MaxFollowerLagTimeMs: -1
CurrentVoters: [{"id": 3000, "directoryId": "ILZ5MPTeRWakmJu99uBJCA", "endpoints": ["CONTROLLER://localhost:9093"]},
{"id": 3001, "directoryId": "b-DwmhtOheTqZzPoh52kfA", "endpoints": ["CONTROLLER://localhost:9094"]},
{"id": 3002, "directoryId": "g42deArWBTRM5A1yuVpMCg", "endpoints": ["CONTROLLER://localhost:9095"]}]
CurrentObservers: [{"id": 0, "directoryId": "3Db5QLSqSZieL3rJBUUegA"},
{"id": 1, "directoryId": "UegA3Db5QLSqSZieL3rJBU"},
{"id": 2, "directoryId": "L3rJBUUegA3Db5QLSqSZie"}]
7.7.2 Dump Log Tool¶
Podemos utilizar kafka-dump-log para depurar los segmentos de registro y las instantáneas del directorio de metadatos del clúster. La herramienta escaneará los archivos proporcionados y decodificará los registros de metadatos. Por ejemplo, el siguiente comando decodifica e imprime los registros del primer segmento de registro:
bin/kafka-dump-log.sh --cluster-metadata-decoder --files metadata_log_dir/__cluster_metadata-0/00000000000000000000.log
7.7.3 Inspect the metadata partition¶
Podemos utilizar kafka-metadata-shell para inspeccionar de forma interactiva el clúster de metadatos. El siguiente ejemplo muestra cómo abrir el shell.
bin/kafka-metadata-shell.sh --snapshot metadata_log_dir/__cluster_metadata-0/00000000000000000000.checkpoint
>> ls /
brokers local metadataQuorum topicIds topics
>> ls /topics
foo
>> cat /topics/foo/0/data
{
"partitionId" : 0,
"topicId" : "5zoAlv-xEh9xRANKXt1Lbg",
"replicas" : [ 1 ],
"isr" : [ 1 ],
"removingReplicas" : null,
"addingReplicas" : null,
"leader" : 1,
"leaderEpoch" : 0,
"partitionEpoch" : 0
}
>> exit
8. Ejemplo 2. Cluster Kafka¶
Imagina que estamos construyendo un sistema para un banco que necesita procesar eventos de transacciones financieras (por ejemplo, transferencias de dinero entre cuentas) en tiempo real. El sistema debe ser capaz de manejar un alto volumen de transacciones de forma eficiente y confiable. Utilizaremos Kafka para construir la infraestructura de mensajería que soportará este procesamiento.
Configuración cluster Kafka
Vamos a configurar el cluster de Kafka usando mode KRaft. Siguiendo las consideraciones del punto anterior y teniendo en cuenta que estamos en un entorno de pruebas y no de producción, para este ejemplo de concepto, vamos a configurar un cluster con 3 servidores (en un sólo nodo o máquina) con 1 controller y 2 brokers
8.1 Requisitos¶
Vamos a configurar un cluster las siguientes características:
- 1 topic con 2 particiones
- 1 factor de replica de 2
- 1 nodo con 2 brokers y 1 controller
8.2 Configuración del Clúster de Kafka¶
- Consideraciones previas:
- Vamos a establecer todos los archivos de configuración en una carpeta de ejemplo llamada ejemplo2, que en mi caso estará alojada en
/opt/kafka/ejemplo2 - Dado que todas las instancias se ejecutarán en el mismo nodo, es crucial asignar puertos únicos y directorios de log para cada broker y el controller.
- Configuración:
- Para el controller, debemos usar como base la configuración de propiedades de controller de kafka (KRaft mode) que se encuentran
config/controller.properties -
Para cada broker, necesitaremos crear un archivo de configuración por separado. Para ello debemos usar como base la configuración de propiedades de brokers de kafka que se encuentran
config/broker.properties -
Creamos los directorios necesarios para nuestro
ejemplo2
- Hacemos 2 y 1 copia de los ficheros correspondientes de configuración para cada uno
cp config/controller.properties /opt/kafka/ejemplo2/config/controller1.properties
cp config/broker.properties /opt/kafka/ejemplo2/config/broker1.properties
cp config/broker.properties /opt/kafka/ejemplo2/config/broker2.properties
- Asignamos la configuración al controller
# Server Basics
process.roles=controller
node.id=1
controller.quorum.bootstrap.servers=localhost:9093
# Socket Server Settings
listeners=CONTROLLER://:9093
advertised.listeners=CONTROLLER://localhost:9093
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo2/logs/controller1
- Asignamos la siguiente configuración para cada broker
- Iniciamos Kafka
#Genera un cluster UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
echo $KAFKA_CLUSTER_ID
#Formateamos los directorios de log
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID --standalone -c /opt/kafka/ejemplo2/config/controller1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo2/config/broker1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo2/config/broker2.properties
- Iniciamos los server(1 controller y 2 brokers) cada uno en una terminal
#Ejecuta el servidor Kafka
bin/kafka-server-start.sh /opt/kafka/ejemplo2/config/controller1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo2/config/broker1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo2/config/broker2.properties
8.3 Creación del Topic¶
- Creamos el topic con factor de replica 2 y 2 particiones. El topic debe conectarse a un broker.
bin/kafka-topics.sh --create --topic financial-transactions --bootstrap-server localhost:9094 --replication-factor 2 --partitions 2
- Podemos ver la descripción del topic creado
Topic: financial-transactions TopicId: wQ94xoPJRVCkm9UdaaOKCw PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: financial-transactions Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: financial-transactions Partition: 1 Leader: 3 Replicas: 3,2 Isr: 3,2 Elr: LastKnownElr:
8.4 Productor y Consumidor¶
- Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers=['localhost:9094', 'localhost:9095'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'))
while True:
transaction = {
"source_account": random.randint(1000, 1999),
"destination_account": random.randint(2000, 2999),
"amount": round(random.uniform(10.00, 1000.00), 2),
"currency": "EUR",
"timestamp": time.time()
}
producer.send('financial-transactions', value=transaction)
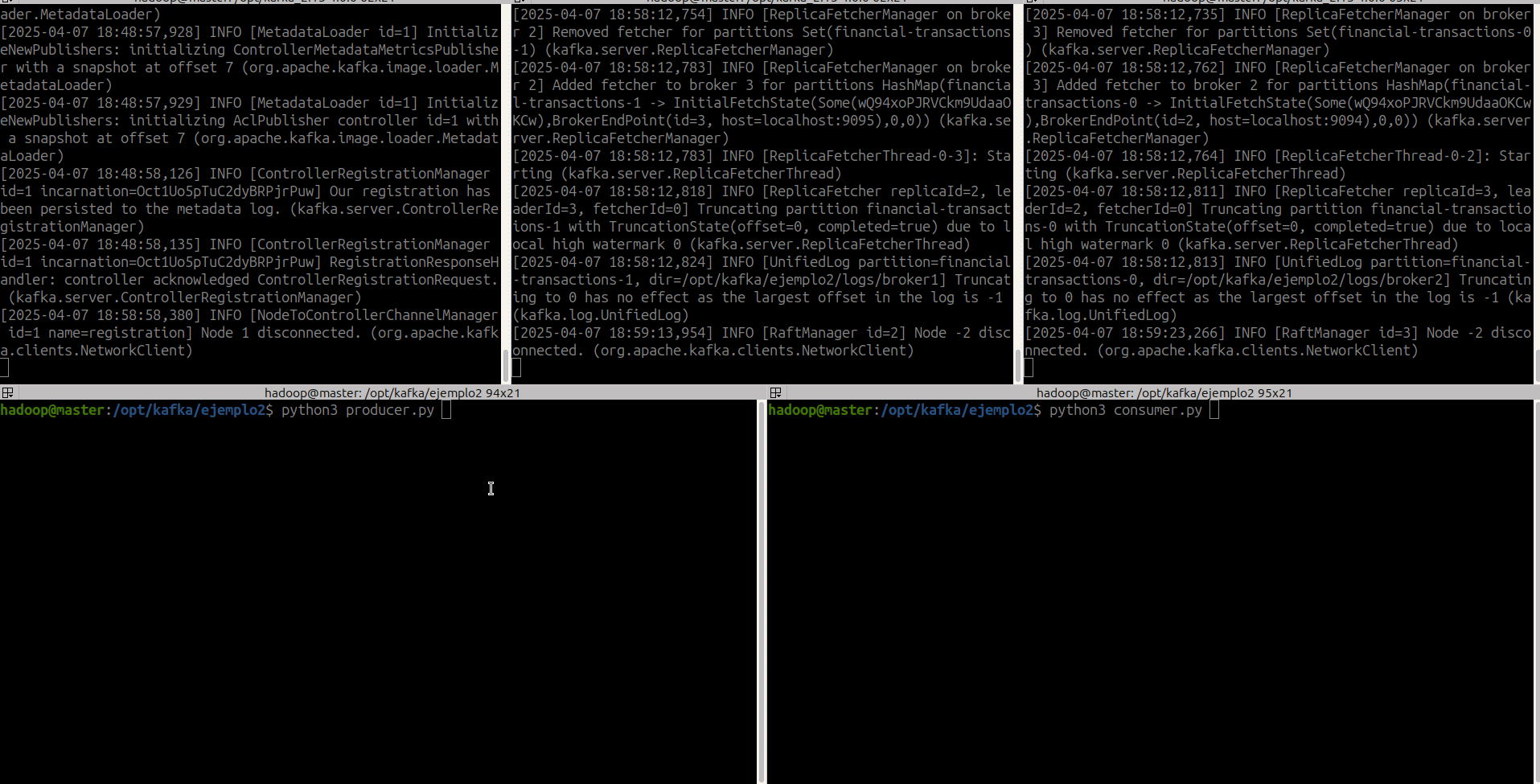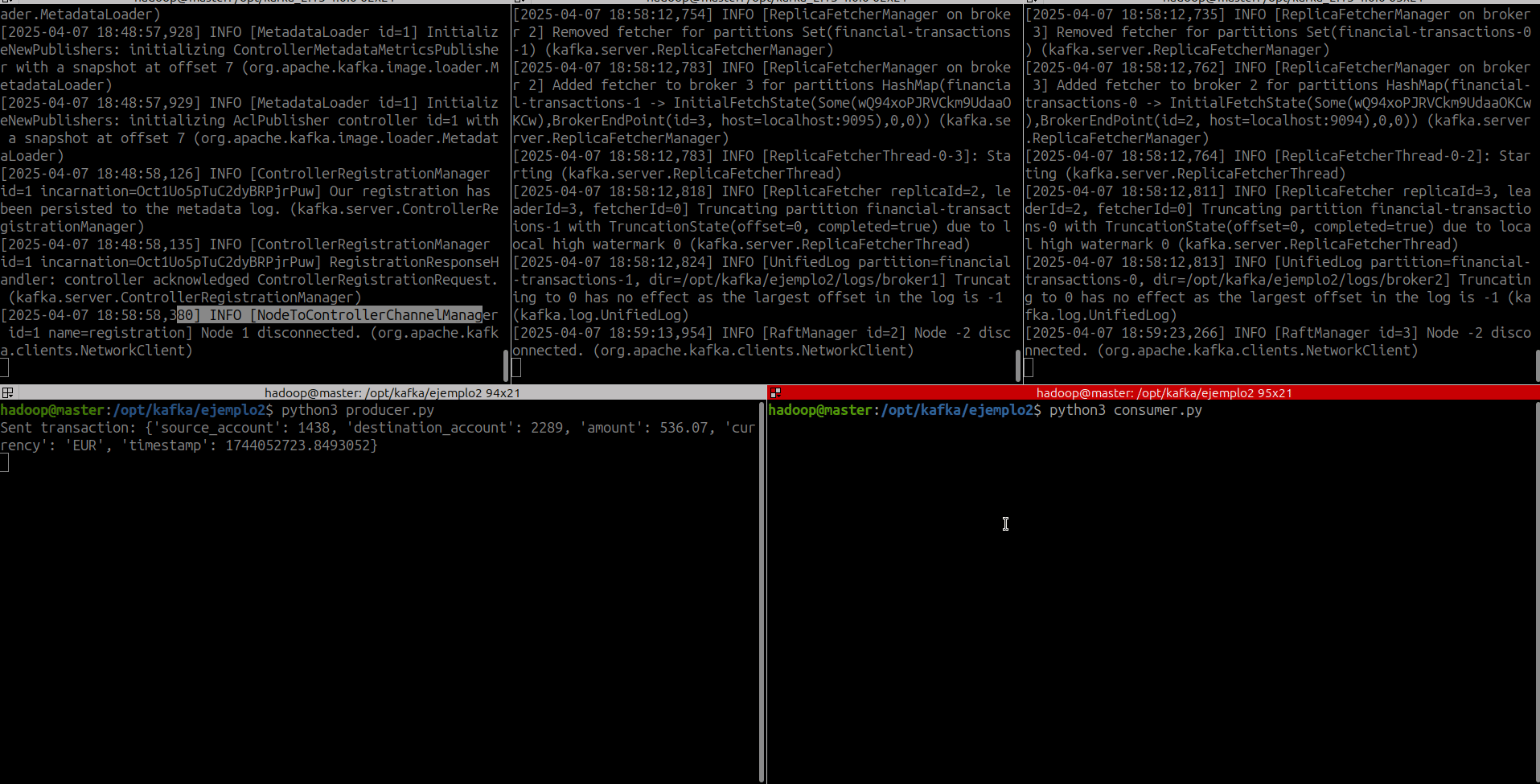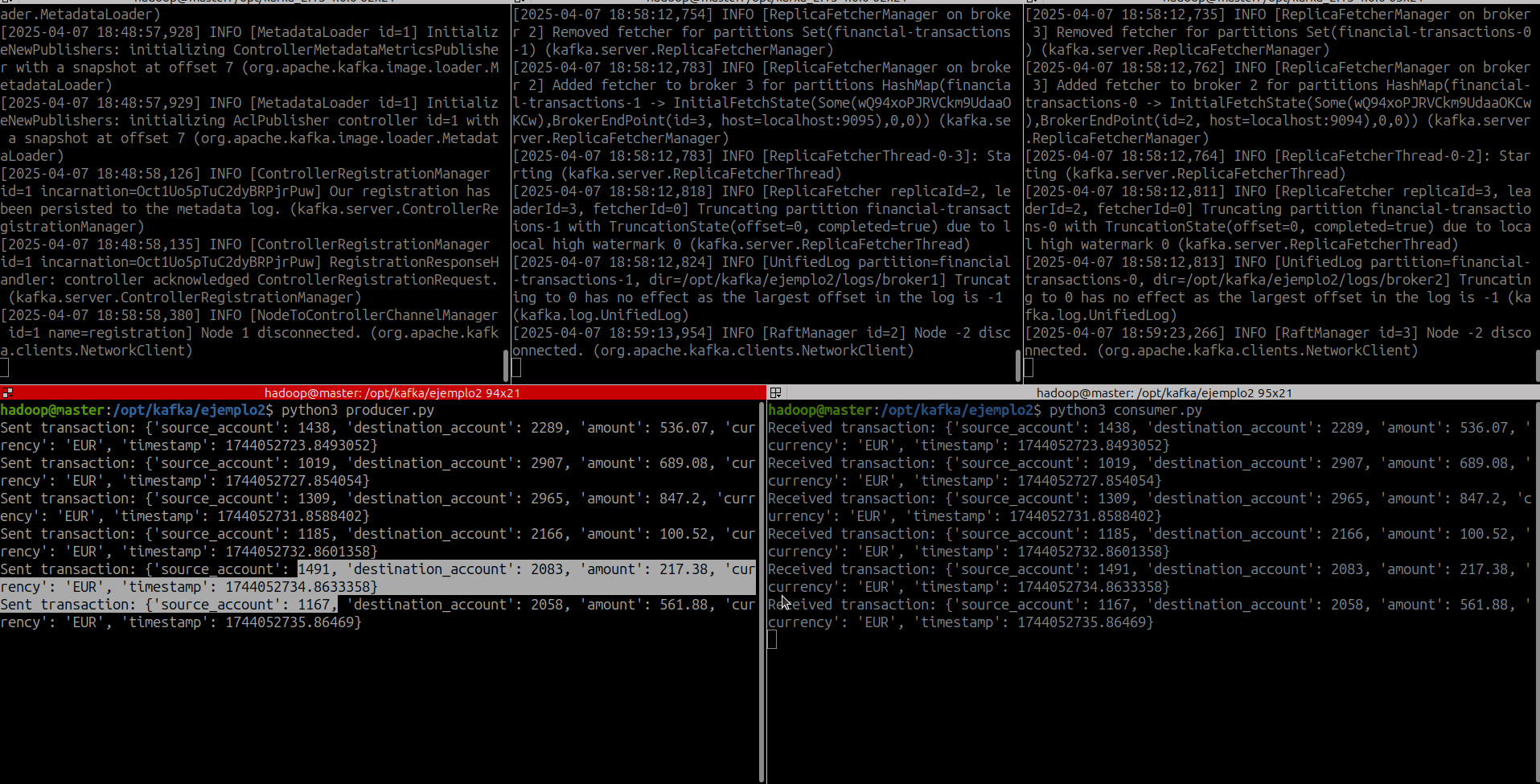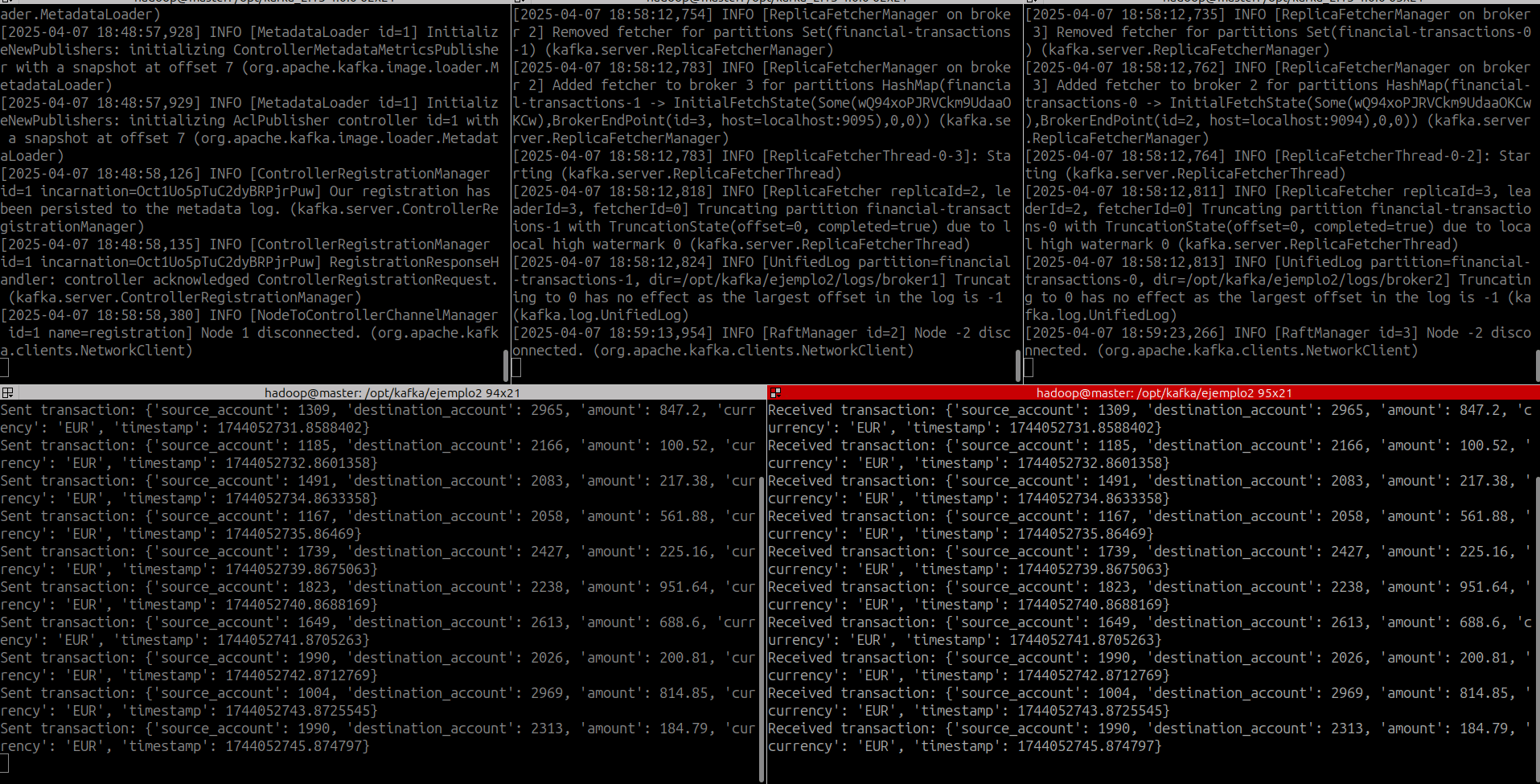
print(f"Sent transaction: {transaction}")
time.sleep(random.randint(1, 5))
- Creamos el consumidor con KafkaConsumer
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer('financial-transactions',
bootstrap_servers=['localhost:9094', 'localhost:9095'],
auto_offset_reset='earliest',
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
transaction = message.value
print(f"Received transaction: {transaction}")
8.5 Ejecución de la aplicación¶
- Lanzamos el productor
- Lanzamos el consumidor
Configuración cluster Kafka
Vamos a configurar el cluster de Kafka usando mode KRaft. Siguiendo las consideraciones del punto anterior y teniendo en cuenta que estamos en un entorno de pruebas y no de producción, para este ejemplo de concepto, vamos a configurar un cluster con 3 servidores con 1 controller y 2 brokers
8.1 Requisitos (Docker)¶
Vamos a configurar un cluster las siguientes características:
- 1 topic con 2 particiones
- 1 factor de replica de 2
- 2 contenedores con 1 broker cada uno y un contenedor con 1 controller
Para que esto funcione, necesitamos crear una Red de Docker para que se vean entre ellos, y exponer puertos distintos hacia afuera para que tus scripts de Python (que se ejecutan en nuestro host) puedan alcanzarlos.
Por tanto, la arquitectura de nuestro cluster Kafka en Docker será la siguiente:
- Red: Una red puente (
bridge) llamadakafka-net-testpara que los contenedores se hablen entre sí por nombre DNS. - 1 Controller: Gestionará el quórum KRaft.
- 2 Brokers: Almacenarán los datos.
- Acceso Externo: Expondremos los brokers en los puertos
9094y9095de nuestro máquina host (localhost) para los scripts de Python.
8.2 Configuración del Clúster de Kafka (Docker)¶
- Consideraciones previas:
- Creamos el directorio
kafka_ejemplos/ejemplo2y dentro de él estarán los archivos de las aplicaciones de python que harán de productor y consumidor respectivamente:
mkdir ejemplo2
cd ejemplo2
touch producer.py consumer.py # O créalos desde tu editor de código
# Recuerda establecer tu entorno virtual de Python en el directorio padre `kafka_ejemplos` para que ambos scripts puedan usar las mismas dependencias
- Configuración:
- Creamos una red de Docker para que los contenedores se comuniquen entre sí por nombre DNS
- Generamos un ID de cluster para nuestro cluster Kafka. En KRaft, todos los nodos deben compartir el mismo identificador único. Lo generamos usando la imagen de forma efímera:
# Ejecutamos el comando una vez y guardamos el resultado
docker run --rm apache/kafka:4.2.0 /opt/kafka/bin/kafka-storage.sh random-uuid
Njfc8tLGSDiYN7sGQFnyaw. Lo usaremos en la variable KAFKA_CLUSTER_ID para todos los nodos).
- Levantamos el Controller (Nodo 1). No necesita exponer puertos hacia afuera (tus scripts Python no hablan con el Controller, hablan con los Brokers), pero lo dejaremos accesible en la red interna.
Estrategia de ejecución
Obviamos el parámetro -d para ver el log de salida del contenedor. Si no quieres ver el log, puedes añadir -d para ejecutarlo en segundo plano. Así no necesitarás abrir más terminales (una para cada nodo del cluster).
docker run --name kafka-controller \
--network kafka-net-test \
-e KAFKA_NODE_ID=1 \
-e KAFKA_PROCESS_ROLES=controller \
-e KAFKA_LISTENERS=CONTROLLER://:9093 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw \
apache/kafka:4.2.0
# Windows
docker run --name kafka-controller --network kafka-net-test -e KAFKA_NODE_ID=1 -e KAFKA_PROCESS_ROLES=controller -e KAFKA_LISTENERS=CONTROLLER://:9093 -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw apache/kafka:4.2.0
(Sustituye Njfc8tLGSDiYN7sGQFnyaw por el código que generaste).
- Levantamos el Broker 1 (Nodo 2) Aquí viene la parte crítica de Kafka en Docker: Los Listeners. El Broker necesita dos identidades:
- Interna (
PLAINTEXT): Para hablar con el Controller y el otro Broker dentro de Docker. Usará el puerto estándar 9092. - Externa (
EXTERNAL): Para que tu script Python (en tu Windows/Mac/Linux) pueda conectar. Usaremos el puerto 9094.
docker run --name kafka-broker-1 \
--network kafka-net-test \
-p 9094:9094 \
-e KAFKA_NODE_ID=2 \
-e KAFKA_PROCESS_ROLES=broker \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9094 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw \
apache/kafka:4.2.0
# Windows
docker run --name kafka-broker-1 --network kafka-net-test -p 9094:9094 -e KAFKA_NODE_ID=2 -e KAFKA_PROCESS_ROLES=broker -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 -e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9094 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT -e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw apache/kafka:4.2.0
(Sustituye Njfc8tLGSDiYN7sGQFnyaw por el código que generaste).
Explicación de ADVERTISED_LISTENERS
Fíjate en la línea KAFKA_ADVERTISED_LISTENERS.
Le estamos diciendo al broker: "Si alguien te pregunta desde dentro de Docker, diles que estás en kafka-broker-1:9092. Pero si alguien te pregunta desde fuera (cliente externo), diles que estás en localhost:9094". Sin esto, nuestro python fallaría.
- Levantamos el Broker 2 (Nodo 3) Idéntico al anterior, pero cambiamos el ID a 3 y el puerto externo a 9095.
docker run --name kafka-broker-2 \
--network kafka-net-test \
-p 9095:9095 \
-e KAFKA_NODE_ID=3 \
-e KAFKA_PROCESS_ROLES=broker \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9095 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw \
apache/kafka:4.2.0
# Windows
docker run --name kafka-broker-2 --network kafka-net-test -p 9095:9095 -e KAFKA_NODE_ID=3 -e KAFKA_PROCESS_ROLES=broker -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller:9093 -e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9095 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT -e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=Njfc8tLGSDiYN7sGQFnyaw apache/kafka:4.2.0
(Sustituye Njfc8tLGSDiYN7sGQFnyaw por el código que generaste).
8.3 Creación del Topic (Docker)¶
- Creamos el topic con factor de replica 2 y 2 particiones. El topic debe conectarse a un broker.
docker exec -it kafka-broker-1 /opt/kafka/bin/kafka-topics.sh \
--create --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 2 --partitions 2
- Podemos ver la descripción del topic creado
docker exec -it kafka-broker-1 /opt/kafka/bin/kafka-topics.sh \
--describe --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092
Topic: financial-transactions TopicId: 1AlwcW-_T0iOkEAAFTbGbw PartitionCount: 2 ReplicationFactor: 2 Configs: min.insync.replicas=1
Topic: financial-transactions Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
Topic: financial-transactions Partition: 1 Leader: 3 Replicas: 3,2 Isr: 3,2 Elr: LastKnownElr:
8.4 Productor y Consumidor (Docker)¶
- Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers=['localhost:9094', 'localhost:9095'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'))
while True:
transaction = {
"source_account": random.randint(1000, 1999),
"destination_account": random.randint(2000, 2999),
"amount": round(random.uniform(10.00, 1000.00), 2),
"currency": "EUR",
"timestamp": time.time()
}
producer.send('financial-transactions', value=transaction)
print(f"Sent transaction: {transaction}")
time.sleep(random.randint(1, 5))
- Creamos el consumidor con KafkaConsumer
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer('financial-transactions',
bootstrap_servers=['localhost:9094', 'localhost:9095'],
auto_offset_reset='earliest',
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
transaction = message.value
print(f"Received transaction: {transaction}")
8.5 Ejecución de la aplicación (Docker)¶
- Necesitaremos 5 terminales para ejecutar todo: controller, broker1, broker2, productor y el consumer. El controller y los broker ya deben estar ejecutándose, así que abre dos terminales nuevas y activa el entorno virtual en ambas:
# Si no lo has activado antes, hazlo ahora en ambas terminales
# Recuerda que el entorno virtual debe estar en el directorio padre `kafka_ejemplos` para que ambos scripts puedan usar las mismas dependencias
cd kafka_ejemplos
python -m venv venv
source venv/bin/activate
cd kafka_ejemplos/ejemplo2
- Lanzamos el productor en una terminal
- Lanzamos el consumidor en otra terminal
- Cuando quieras parar el cluster, puedes usar el siguiente comando para eliminar los contenedores y la red de Docker:
9. Ejemplo 3. Cluster Kafka (Bootstrap with Multiple Controllers)¶
Para aprender a realizar un cluster con varios controller en el nuevo modo Dynamic Quorum, vamos a realizar el mismo ejemplo anterior, pero en este caso, levantando 3 controller y 3 brokers, para así entender las diferencias con la versión anterior y asegurarnos de haber aprendido correctamente el uso de Kafka.
9.1 Requisitos¶
Vamos a configurar un cluster las siguientes características:
- 1 topic con 3 particiones
- 1 factor de replica de 2
- 1 nodo con 3 brokers y 3 controllers
9.2 Configuración del Clúster de Kafka¶
- Consideraciones previas:
- Vamos a establecer todos los archivos de configuración en una carpeta de ejemplo llamada ejemplo3, que en mi caso estará alojada en
/opt/kafka/ejemplo3 - Dado que todas las instancias se ejecutarán en el mismo nodo, es crucial asignar puertos únicos y directorios de log para cada broker y el controller.
- Configuración:
- Para el controller, debemos usar como base la configuración de propiedades de controller de kafka (KRaft mode) que se encuentran
config/controller.properties -
Para cada broker, necesitaremos crear un archivo de configuración por separado. Para ello debemos usar como base la configuración de propiedades de brokers de kafka que se encuentran
config/broker.properties -
Creamos los directorios necesarios para nuestro
ejemplo3
- Hacemos 3 copias de los ficheros correspondientes de configuración para cada uno
cp config/controller.properties /opt/kafka/ejemplo3/config/controller1.properties
cp config/controller.properties /opt/kafka/ejemplo3/config/controller2.properties
cp config/controller.properties /opt/kafka/ejemplo3/config/controller3.properties
cp config/broker.properties /opt/kafka/ejemplo3/config/broker1.properties
cp config/broker.properties /opt/kafka/ejemplo3/config/broker2.properties
cp config/broker.properties /opt/kafka/ejemplo3/config/broker3.properties
- Como estamos en el mismo nodo, le vamos a dar los siguiente puertos y ids a cada server:
- controller1: puerto 9096, nodo 1
- controller2: puerto 9097, nodo 2
- controller3: puerto 9098, nodo 3
- broker1: puerto 9092, nodo 5
- broker2: puerto 9093, nodo 6
- broker3: puerto 9094, nodo 7
- Asignamos la configuración al controller
# Server Basics
process.roles=controller
node.id=1
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=CONTROLLER://:9096
advertised.listeners=CONTROLLER://localhost:9096
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/controller1
# Server Basics
process.roles=controller
node.id=2
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=CONTROLLER://:9097
advertised.listeners=CONTROLLER://localhost:9097
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/controller2
# Server Basics
process.roles=controller
node.id=3
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=CONTROLLER://:9098
advertised.listeners=CONTROLLER://localhost:9098
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/controller3
- Asignamos la siguiente configuración para cada broker
# Server Basics
process.roles=broker
node.id=5
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=PLAINTEXT://localhost:9092
advertised.listeners=PLAINTEXT://localhost:9092
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/broker1
# Server Basics
process.roles=broker
node.id=6
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=PLAINTEXT://localhost:9093
advertised.listeners=PLAINTEXT://localhost:9093
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/broker2
# Server Basics
process.roles=broker
node.id=7
controller.quorum.bootstrap.servers=localhost:9096,localhost:9097,localhost:9098
# Socket Server Settings
listeners=PLAINTEXT://localhost:9094
advertised.listeners=PLAINTEXT://localhost:9094
# Log Basics
log.dirs=/opt/kafka/ejemplo3/logs/broker3
- Generamos los uuid
#Generamos un cluster UUID y los IDs de los controllers
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_1_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_2_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_3_UUID="$(bin/kafka-storage.sh random-uuid)"
#Formateamos los directorios de log indicando los controllers iniciales
#controller1
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller1.properties
#controller2
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller2.properties
#controller3
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller3.properties
- Damos formato a los logs de los brokers
#Formateamos los directorios de log de los brokers
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker2.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker3.properties
- Iniciamos los servers(3 controllers y 3 brokers) cada uno en una terminal
#Ejecutamos los servidores Kafka (uno en cada terminal)
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/controller1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/controller2.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/controller3.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/broker1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/broker2.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo3/config/broker3.properties
Metadata Quorum Tool
Podemos ver la describir el estado en tiempo de ejecución de la partición de metadatos del clúster con:
Vemos como se encuentra la configuración del Quorum de los controllers además de la lista de brokers
ClusterId: pOScImhcQ2-exV4PwTonuA
LeaderId: 2
LeaderEpoch: 27
HighWatermark: 708
MaxFollowerLag: 2
MaxFollowerLagTimeMs: 966
CurrentVoters: [{"id": 1, "directoryId": "UIzTVxjnTIOEH3WW5VdOAw", "endpoints": ["CONTROLLER://localhost:9096"]}, {"id": 2, "directoryId": "187-ElH6RJqEc4QftkoSqQ", "endpoints": ["CONTROLLER://localhost:9097"]}, {"id": 3, "directoryId": "XGGfTEh6RaaXlpQBK-3dug", "endpoints": ["CONTROLLER://localhost:9098"]}]
CurrentObservers: [{"id": 6, "directoryId": "4D5AbljfLEOno0wnk-N7_w"}, {"id": 5, "directoryId": "e4KmRqCr0wweYkHqWn2qkw"}, {"id": 7, "directoryId": "cxJ2pf7x8mi93Oi0PrKKUA"}]
9.3 Creación del Topic¶
- Creamos el topic con factor de replica 3 y 3 particiones. El topic debe conectarse a un broker.
bin/kafka-topics.sh --create --topic financial-transactions --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3
- Podemos ver la descripción del topic creado
Topic: financial-transactions TopicId: 4WfNcmv3SU-Kh7mMmWRaTw PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: financial-transactions Partition: 0 Leader: 6 Replicas: 6,7,5 Isr: 6,7,5 Elr: LastKnownElr:
Topic: financial-transactions Partition: 1 Leader: 7 Replicas: 7,5,6 Isr: 7,5,6 Elr: LastKnownElr:
Topic: financial-transactions Partition: 2 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7 Elr: LastKnownElr:
9.4 Productor y Consumidor¶
- Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers=['localhost:9094', 'localhost:9095'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'))
while True:
transaction = {
"source_account": random.randint(1000, 1999),
"destination_account": random.randint(2000, 2999),
"amount": round(random.uniform(10.00, 1000.00), 2),
"currency": "EUR",
"timestamp": time.time()
}
producer.send('financial-transactions', value=transaction)
print(f"Sent transaction: {transaction}")
time.sleep(random.randint(1, 5))
- Creamos el consumidor con KafkaConsumer
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer('financial-transactions',
bootstrap_servers=['localhost:9094', 'localhost:9095'],
auto_offset_reset='earliest',
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
transaction = message.value
print(f"Received transaction: {transaction}")
9.5 Ejecución de la aplicación¶
- Lanzamos el productor
- Lanzamos el consumidor
9.1 Requisitos (Docker)¶
Vamos a configurar un cluster las siguiente arquitectura:
- Red:
kafka-net-quorum(nueva red aislada). - 3 Controladores:
controller-1,controller-2,controller-3. Formarán el quórum de votación. - 3 Brokers:
broker-1,broker-2,broker-3. Se conectarán al quórum de controladores. - Acceso Externo: Expondremos los 3 brokers en puertos distintos (
9094,9095,9096) para nuestros scripts Python.
9.2 Configuración del Clúster de Kafka (Docker)¶
- Consideraciones previas:
- Creamos el directorio
kafka_ejemplos/ejemplo3y dentro de él estarán los archivos de las aplicaciones de python que harán de productor y consumidor respectivamente:
mkdir ejemplo3
cd ejemplo3
cp ../ejemplo2/producer.py .
touch producer.py consumer.py # O créalos desde tu editor de código
# Recuerda establecer tu entorno virtual de Python en el directorio padre `kafka_ejemplos` para que ambos scripts puedan usar las mismas dependencias
- Configuración:
- Creamos una red de Docker para que los contenedores se comuniquen entre sí por nombre DNS
- Generamos un ID de cluster para nuestro cluster Kafka. En KRaft, todos los nodos deben compartir el mismo identificador único. Lo generamos usando la imagen de forma efímera:
VPC5CVQ-QtGaACRj3hlfLg como ejemplo, cámbialo por el tuyo).
Estrategia de ejecución
Recuerda: Obviamos el parámetro -d para ver el log de salida del contenedor. Si no quieres ver el log, puedes añadir -d para ejecutarlo en segundo plano. Así no necesitarás abrir más terminales (una para cada nodo del cluster).
(Sustituye VPC5CVQ-QtGaACRj3hlfLg por el código que generaste en todos los controllers y brokers).
- Levantamos los 3 Controladores. Aquí está la diferencia clave: la variable
KAFKA_CONTROLLER_QUORUM_VOTERSahora debe listar a todos los controladores.
- Formato:
id@host:port,id@host:port... - String de conexión:
1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
docker run --name kafka-controller-1 \
--network kafka-net-quorum \
-e KAFKA_NODE_ID=1 \
-e KAFKA_PROCESS_ROLES=controller \
-e KAFKA_LISTENERS=CONTROLLER://:9093 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-controller-1 --network kafka-net-quorum -e KAFKA_NODE_ID=1 -e KAFKA_PROCESS_ROLES=controller -e KAFKA_LISTENERS=CONTROLLER://:9093 -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
docker run --name kafka-controller-2 \
--network kafka-net-quorum \
-e KAFKA_NODE_ID=2 \
-e KAFKA_PROCESS_ROLES=controller \
-e KAFKA_LISTENERS=CONTROLLER://:9093 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-controller-2 --network kafka-net-quorum -e KAFKA_NODE_ID=2 -e KAFKA_PROCESS_ROLES=controller -e KAFKA_LISTENERS=CONTROLLER://:9093 -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
docker run --name kafka-controller-3 \
--network kafka-net-quorum \
-e KAFKA_NODE_ID=3 \
-e KAFKA_PROCESS_ROLES=controller \
-e KAFKA_LISTENERS=CONTROLLER://:9093 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-controller-3 --network kafka-net-quorum -e KAFKA_NODE_ID=3 -e KAFKA_PROCESS_ROLES=controller -e KAFKA_LISTENERS=CONTROLLER://:9093 -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
- Levantamos los 3 Brokers. Los brokers necesitan apuntar al mismo string de votantes (
KAFKA_CONTROLLER_QUORUM_VOTERS). Usaremos IDs 4, 5 y 6 para los brokers.
docker run --name kafka-broker-1 \
--network kafka-net-quorum \
-p 9094:9094 \
-e KAFKA_NODE_ID=4 \
-e KAFKA_PROCESS_ROLES=broker \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9094 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-broker-1 --network kafka-net-quorum -p 9094:9094 -e KAFKA_NODE_ID=4 -e KAFKA_PROCESS_ROLES=broker -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9094 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT -e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
docker run --name kafka-broker-2 \
--network kafka-net-quorum \
-p 9095:9095 \
-e KAFKA_NODE_ID=5 \
-e KAFKA_PROCESS_ROLES=broker \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9095 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-broker-2 --network kafka-net-quorum -p 9095:9095 -e KAFKA_NODE_ID=5 -e KAFKA_PROCESS_ROLES=broker -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9095 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT -e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
docker run --name kafka-broker-3 \
--network kafka-net-quorum \
-p 9096:9096 \
-e KAFKA_NODE_ID=6 \
-e KAFKA_PROCESS_ROLES=broker \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9096 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096 \
-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg \
apache/kafka:4.2.0
# Windows
docker run --name kafka-broker-3 --network kafka-net-quorum -p 9096:9096 -e KAFKA_NODE_ID=6 -e KAFKA_PROCESS_ROLES=broker -e KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093 -e KAFKA_LISTENERS=PLAINTEXT://:9092,EXTERNAL://:9096 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096 -e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT -e KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT -e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER -e KAFKA_CLUSTER_ID=VPC5CVQ-QtGaACRj3hlfLg apache/kafka:4.2.0
Arquitectura de Red en Kafka: Listeners y Docker
En la configuración de los brokers, observarás que definimos KAFKA_LISTENERS usando un comodín (PLAINTEXT://:9092). Esto equivale a decirle al servidor: "Escucha en TODAS las interfaces de red disponibles (0.0.0.0)".
¿Por qué esta es la Mejor Práctica en Docker?:
1. Diferencia entre "Escuchar" (Bind) y "Anunciar" (Route)
KAFKA_LISTENERS(BIND): Es la configuración física del socket. ¿Dónde estoy escuchando? Al usar//:9092, aceptamos conexiones en ese puerto vengan de donde vengan.KAFKA_ADVERTISED_LISTENERS(ROUTING): Es la "tarjeta de visita" que Kafka entrega a los clientes. Aquí es donde somos específicos:- Tráfico Interno: "Llámame a
kafka-broker-1:9092". - Tráfico Externo: "Llámame a
localhost:9094" (En nuestro caso de laboratorio, nuestro host/anfitrión).
- Tráfico Interno: "Llámame a
2. El Riesgo Técnico: IPs Dinámicas en Docker
Docker asigna IPs internas dinámicamente al arrancar. Si configuramos una IP fija o un hostname específico en el Listener (ej: kafka-broker-1), corremos dos riesgos:
- IPs cambiantes: Si reinicias la red, la IP puede cambiar y la configuración fija fallará.
- Race Condition: A veces, el proceso Java de Kafka arranca milisegundos antes de que Docker actualice el DNS interno (
/etc/hosts). Si Kafka intenta "atarse" (bind) akafka-broker-1y el sistema operativo aún no sabe quién es, el contenedor muere con el error:java.net.BindException: Cannot assign requested address.
Usamos el comodín 0.0.0.0 elimina estos riesgos por completo: Kafka arranca siempre, tenga la IP que tenga.
3. Seguridad en Contenedores
En un servidor físico con varias tarjetas de red, es vital especificar la IP para no exponer tráfico privado en la red pública. Sin embargo, un contenedor Docker suele tener una única interfaz virtual (eth0). Decirle "escucha en tu IP" o "escucha en todas" tiene el mismo efecto práctico.
La seguridad en Docker no la da el Listener, sino el Mapeo de Puertos (
-p) y las Redes Virtuales.
Conclusión
- En Bare-Metal (Físico): Usa IPs específicas en
LISTENERSpara segregar tráfico. - En Docker / Kubernetes: Usa el comodín
//:9092. Es más robusto, facilita la automatización (misma config para todos los brokers) y evita fallos de arranque.
9.3 Creación del Topic (Docker)¶
- Creamos el topic con factor de replica 3 y 3 particiones. El topic debe conectarse a un broker.
# Crear topic con réplica en los 3 brokers
docker exec kafka-broker-1 /opt/kafka/bin/kafka-topics.sh \
--create --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 3 --partitions 3
- Podemos ver la descripción del topic creado
# Describir para ver la distribución
docker exec kafka-broker-1 /opt/kafka/bin/kafka-topics.sh \
--describe --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092
Topic: financial-transactions TopicId: IlDQ5OOcS4-lgjXKLNw4Xg PartitionCount: 3 ReplicationFactor: 3 Configs: min.insync.replicas=1
Topic: financial-transactions Partition: 0 Leader: 6 Replicas: 6,4,5 Isr: 6,4,5 Elr: LastKnownElr:
Topic: financial-transactions Partition: 1 Leader: 4 Replicas: 4,5,6 Isr: 4,5,6 Elr: LastKnownElr:
Topic: financial-transactions Partition: 2 Leader: 5 Replicas: 5,6,4 Isr: 5,6,4 Elr: LastKnownElr:
9.4 Productor y Consumidor (Docker)¶
Necesitamos actualizar la lista de servidores en nuestros scripts para incluir el nuevo broker en el puerto 9096.
- Creamos el productor con KafkaProducer
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers=['localhost:9094', 'localhost:9095', 'localhost:9096'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'))
while True:
transaction = {
"source_account": random.randint(1000, 1999),
"destination_account": random.randint(2000, 2999),
"amount": round(random.uniform(10.00, 1000.00), 2),
"currency": "EUR",
"timestamp": time.time()
}
producer.send('financial-transactions', value=transaction)
print(f"Sent transaction: {transaction}")
time.sleep(random.randint(1, 5))
- Creamos el consumidor con KafkaConsumer
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer('financial-transactions',
bootstrap_servers=['localhost:9094', 'localhost:9095', 'localhost:9096'],
auto_offset_reset='earliest',
group_id='python-banking-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
transaction = message.value
print(f"Received transaction: {transaction}")
9.5 Ejecución de la aplicación (Docker)¶
- Necesitaremos 8 terminales para ejecutar todo: 3 controllers, 3 brokers (el topic lo creo antes de ejecutar producer y consumer y después de levantar los controllers y brokers), el productor y el consumer. Los controllers y los brokers ya deben estar ejecutándose, así que abre dos terminales nuevas y activa el entorno virtual en ambas:
# Si no lo has activado antes, hazlo ahora en ambas terminales
# Recuerda que el entorno virtual debe estar en el directorio padre `kafka_ejemplos` para que ambos scripts puedan usar las mismas dependencias
cd kafka_ejemplos
python -m venv venv
source venv/bin/activate
cd kafka_ejemplos/ejemplo3
- Lanzamos el productor en una terminal
- Lanzamos el consumidor en otra terminal
- Prueba de Resiliencia
Sin detener el productor ni el consumidor, prueba a matar un controller y un broker para ver que el cluster sigue funcionando:
# Mata un Controller
# El clúster debe seguir funcionando (quedan 2 controladores para votar).
docker stop kafka-controller-1
# El flujo de datos no debe detenerse (los datos están replicados en kafka-broker-1 y kafka-broker-3)
docker stop kafka-broker-2
# Si lo levantas de nuevo, el cluster debería recuperarse automáticamente y reequilibrar las particiones y el quorum de los contreollers
docker start kafka-controller-1
docker start kafka-broker-2
- Cuando quieras parar el cluster, puedes usar el siguiente comando para eliminar los contenedores y la red de Docker:
docker rm -f kafka-controller-1 kafka-controller-2 kafka-controller-3 kafka-broker-1 kafka-broker-2 kafka-broker-3
docker network rm kafka-net-quorum
Observabilidad: ¿Por qué no veo los logs de mensajes en Docker?
Es posible que hayas notado una diferencia importante respecto a la ejecución en las Máquinas Virtuales: En Docker, los Brokers no muestran logs por cada mensaje que se envía o recibe, ni los offsets; y los controllers son muestran la sincronización de los quorum.
1. Optimización Productiva:
Esto es debido a que la imagen oficial de Docker está configurada por defecto para entornos de producción. En un sistema real que procesa millones de eventos por segundo, escribir una línea de log por cada mensaje (PRODUCE/FETCH) saturaría el disco y la CPU con facilidad. Por ello, el nivel de log por defecto filtra el "tráfico de datos" y solo muestra eventos del "ciclo de vida" (arranque, conexión de brokers, errores).
2. Cómo activarlo (Solo para Educación/Depuración): Si queremos ver las todos los logs del sistema (peticiones internas, sincronización y offsets) para entender el flujo, puedes sobreescribir la configuración de Log4j inyectando esta variable de entorno al arrancar los contenedores de los Brokers y Controllers:
⚠️ Advertencia: Esto generará una cantidad masiva de texto en la terminal. Úsalo solo para diagnósticos puntuales o curiosidad académica, nunca lo dejes activo en un despliegue estable.
10. Cluster kafka en Docker Compose¶
En esta sección integraremos un clúster de Apache Kafka 4.2.0 en nuestra infraestructura Docker.
Siguiendo las mejores prácticas de la industria y la (documentación de Github)[https://github.com/apache/kafka/blob/trunk/docker/examples/docker-compose-files/cluster/isolated/plaintext/docker-compose.yml], desplegaremos una Arquitectura Aislada (Isolated) utilizando el modo KRaft.
10.1 Arquitectura del Clúster (Plano de Control vs Datos)¶
Separaremos físicamente los roles en contenedores distintos para garantizar alta disponibilidad y rendimiento aislando la CPU/RAM de cada tarea:
- Capa de Control (3 Controllers): Mantienen el estado del clúster (Quórum 2n+1). Si uno cae, los otros dos mantienen el sistema vivo.
- Capa de Datos (3 Brokers): Almacenan las particiones y atienden a los productores/consumidores. Exponen puertos externos (
9094,9095,9096) para conectar scripts desde nuestro ordenador (Host). - Observabilidad (Kafka UI): Una interfaz gráfica conectada vía Traefik para monitorizar el flujo de datos.
Aviso de Recursos (RAM)
Levantar 6 nodos de Kafka + UI + Hadoop + Spark consume muchos recursos en nuestro ordenador. Usamos la variable KAFKA_JVM_PERFORMANCE_OPTS para limitar estrictamente la RAM a 256MB para los controllers y 512MB para los brokers. Puedes cambiarlos a tu decisión.
10.2 Implementación en Docker Compose¶
Añadimos los siguientes bloques a la sección services de tu docker-compose.yml.
El ID del Clúster en Docker Compose
A diferencia del entorno manual donde generábamos un UUID por consola, en Docker Compose fijamos un Cluster ID estático (ej. MkU3OEVBNTcwNTJENDM2Qk). Esto asegura que, si los contenedores se recrean, todos sigan perteneciendo al mismo clúster unificado.
10.3 Capa de Control (Controllers)¶
Los controllers no exponen puertos al exterior, solo se hablan entre ellos y con los brokers en la red interna (bda-network) por el puerto 9093.
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
10.4 Capa de Datos (Brokers)¶
Los Brokers (IDs 4, 5 y 6) tienen un doble Listener: uno interno (PLAINTEXT:9092) y otro externo (EXTERNAL) mapeado al Host.
KAFKA_ADVERTISED_LISTENERS
Esta variable es la que permite la comunicación externa e interna. Le dice al broker: "Si te llaman desde dentro, di que eres 'kafka-broker-1'. Si te llaman desde fuera, di que eres 'localhost'". Sin esto, tus clientes externos fallarían al intentar conectar.
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
10.5 Kafka UI (Monitorización)¶
Añadimos la herramienta estándar de mercado para visualizar gráficamente Kafka. La exponemos mediante Traefik.
Administrar Kafka desde la terminal de comandos es fundamental para entender su funcionamiento, pero en el día a día de un entorno de producción necesitamos visibilidad instantánea.
Para ello, añadiremos una interfaz gráfica que nos permita ver el estado de los Brokers, crear Topics, inspeccionar mensajes en tiempo real y vigilar a los grupos de consumidores.
Kafbat UI vs Provectus labs
Utilizaremos la imagen ghcr.io/kafbat/kafka-ui. Es importante destacar que esta es una bifurcación (fork) mantenida por la comunidad del proyecto original provectuslabs/kafka-ui, el cual lleva años desatendido. Usar software actualizado es una regla de oro en ciberseguridad y estabilidad.
Integración con Traefik¶
Dado que kafbat-ui está desarrollado sobre el framework Spring Boot (Java), a veces tiene problemas para generar enlaces internos y cargar recursos estáticos (CSS/JS) cuando se encuentra detrás de un Proxy Inverso como nuestro Traefik.
Para que la aplicación comprenda que el usuario está accediendo desde http://kafka.localhost (y no desde la IP interna del contenedor), debemos inyectar la variable de entorno SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK. Esto le indica a Spring Boot que debe confiar en las cabeceras HTTP que Traefik le está reenviando.
- Recursos Oficiales y Referencias
La configuración que aplicaremos a continuación ha sido diseñada estudiando la documentación oficial del proyecto. Es altamente recomendable tener estos enlaces como referencia:
- Repositorio Oficial (GitHub):https://github.com/kafbat/kafka-ui
- Documentación Oficial:https://ui.docs.kafbat.io/
- Topologías Docker: Nuestra configuración se ha adaptado a partir de los docker compose proporcionados por los desarrolladores.
Configuración en docker-compose.yml¶
Añade este bloque al final de la sección services:
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
Verificación¶
Cuando levantemos el cluster, debemos ver un panel indicando el estado del clúster bda-cluster en verde, confirmando que la interfaz puede comunicarse correctamente con los 3 Brokers.
10.6 Kafka - Node Edge¶
Vamos a introducir el concepto de "Edge Node" (Nodo Frontera). Un contenedor que no almacena datos ni procesa métricas; su única razón de existir es tener instalados los binarios de Kafka para que nosotros podamos entrar en él y lanzar comandos contra el clúster.
Nuestra Solución (Edge Node): Desplegaremos un contenedor llamado kafka-client. Este no almacena datos. Lo usaremos como "Nodo Frontera" para entrar en él y lanzar comandos administrativos contra los brokers a través de la red interna. Así conseguimos:
- Evitar instalar Kafka en nuestro Host (evitamos conflictos de versiones y dependencias).
- Robo de recursos: No consume RAM ni CPU del cluster de Kafka, ya que no procesa datos ni almacena logs.
- Añadimos una capa de seguridad: Si alguien accede a este contenedor, no tiene acceso directo a los datos ni a la configuración de los brokers, solo a las herramientas de cliente.
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
10.7 Declaración de Volúmenes¶
En nuestro docker-compose.yml, debemos registrar los 6 nuevos volúmenes para que los datos no se pierdan al reiniciar.
volumes:
# ... otros volúmenes ...
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
10.8 Stack completo del docker compose¶
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
10.9 Despliegue¶
- Arranca el ecosistema:
- Verificación(Kafka UI): Abre tu navegador en http://kafka.localhost. Deberías ver el clúster
bda-clusteren verde. Si vas a la pestaña "Brokers", verás 3 nodos activos.
10.10 Prueba de Productor y Consumidor¶
Usamermos exactamente los mismos scripts producer.py y consumer.py del Ejemplo 3 que creamos en el punto anterior.
-
Creación del Topic: Para crear un Topic, entraremos en nuestro nodo cliente y usaremos los scripts oficiales de Kafka apuntando a cualquiera de nuestros brokers (
kafka-broker-1:9092). -
Creamos el topic con factor de replica 3 (alta disponibilidad total) y 3 particiones:
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh \
--create --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 3 --partitions 3
- Podemos ver la descripción del topic para confirmar que se ha distribuido correctamente:
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh \
--describe --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092
Salida esperada:
Topic: financial-transactions TopicId: AuUZp_u1QPGd70pvrXNCvQ PartitionCount: 3 ReplicationFactor: 3 Configs: min.insync.replicas=1
Topic: financial-transactions Partition: 0 Leader: 6 Replicas: 6,4,5 Isr: 6,4,5 Elr: LastKnownElr:
Topic: financial-transactions Partition: 1 Leader: 4 Replicas: 4,5,6 Isr: 4,5,6 Elr: LastKnownElr:
Topic: financial-transactions Partition: 2 Leader: 5 Replicas: 5,6,4 Isr: 5,6,4 Elr: LastKnownElr:
-
También podemos verla en nuestro Kafka UI, y comprobar que las particiones están distribuidas entre los brokers.
-
Productores y Consumidores de Consola (Testing)
Si quisieras probar el envío de mensajes de texto rápidamente sin usar Python, también usarías este contenedor cliente:
Productor (consola):
docker exec -it kafka-client /opt/kafka/bin/kafka-console-producer.sh \
--topic financial-transactions \
--bootstrap-server kafka-broker-1:9092
Consumidor (consola):
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh \
--topic financial-transactions \
--from-beginning \
--bootstrap-server kafka-broker-1:9092
- Productores y Consumidores Python
Como hemos comentado anteriormente, usamos el ejercicio 3 para probar nuestros scripts Python.
- Lanzamos el productor
- Lanzamos el consumidor
Lanza el productor en tu terminal local, y al ir a Kafka UI -> Topics -> (tu topic) -> Messages, ¡verás los mensajes entrando en tiempo real!
10.11 Conclusión¶
Con este cambio, en tu arquitectura tienes:
- Controladores aislados (Plano de Control).
- Brokers aislados (Plano de Datos).
- Kafka UI (Plano de Observabilidad).
- Kafka Client (Plano de Administración).
- Scripts Python en el Host (Aplicaciones Externas).
11. Arquitectura en Producción: Seguridad (SSL/TLS)¶
En nuestro despliegue de laboratorio hemos utilizado el protocolo PLAINTEXT (Texto Plano) para todas las comunicaciones. Esto significa que los mensajes viajan por la red de Docker sin encriptar.
Zero Trust en Producción
En un entorno empresarial real (Enterprise), utilizar PLAINTEXT sería una negligencia. Las arquitecturas modernas asumen un modelo "Zero Trust" (Confianza Cero), donde cualquier dato en tránsito debe estar cifrado, incluso dentro de redes privadas.
Para llevar este clúster a un entorno de producción, Apache Kafka soporta SSL/TLS para encriptar los datos en tránsito y mTLS (Mutual TLS) para autenticar a los clientes y a los propios brokers.
11.1 ¿Qué cambia en la configuración?¶
Configurar Kafka con SSL requiere una infraestructura de claves públicas (PKI). A nivel de Docker, el cambio implica:
- Generación de Certificados: Crear un Keystore (con el certificado y clave privada del nodo) y un Truststore (con los certificados de las Autoridades Certificadoras en las que confiamos) para cada contenedor.
- Inyección de Secretos: Montar estos archivos (generalmente en formato
.jkso.pem) dentro de los contenedores mediante volúmenes. - Cambio de Protocolo: Sustituir
PLAINTEXTporSSLen los Listeners.
Ejemplo de variables de entorno SSL:
environment:
KAFKA_LISTENERS: SSL://:9092,EXTERNAL_SSL://:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:SSL,SSL:SSL,EXTERNAL_SSL:SSL
KAFKA_SSL_KEYSTORE_FILENAME: /etc/kafka/secrets/kafka.server.keystore.jks
KAFKA_SSL_KEYSTORE_CREDENTIALS: /etc/kafka/secrets/kafka.server.keystore.credentials
KAFKA_SSL_TRUSTSTORE_FILENAME: /etc/kafka/secrets/kafka.server.truststore.jks
KAFKA_SSL_TRUSTSTORE_CREDENTIALS: /etc/kafka/secrets/kafka.server.truststore.credentials
11.2 Referencia Oficial (Docker SSL)¶
Los mantenedores de Apache Kafka proporcionan una topologíade Arquitectura Aislada (Isolated), pero implementando SSL completo.
Puedes (y debes, si vas a llevar esto a producción) estudiar la configuración completa en el repositorio oficial de GitHub:
11.3 Justificación Didáctica del Laboratorio¶
¿Por qué no usamos SSL en este curso?
Implementar SSL añade una capa de complejidad operativa muy alta. Los errores más comunes en las primeras fases de aprendizaje pasan a ser de tipo SSLHandshakeException o CertificateExpiredException, en lugar de errores sobre el funcionamiento real de Kafka (particiones, réplicas, offsets).
Nuestro objetivo pedagógico es dominar la semántica de los eventos y la arquitectura distribuida. Una vez que domines cómo fluyen los datos en PLAINTEXT, activar SSL es un paso exclusivo de DevOps/SecOps que no altera la lógica de tu código de Big Data.