UD 6 - Apache Spark¶
Apache Spark es un motor de análisis unificado para el procesamiento de datos a gran escala. Proporciona API de alto nivel en Java, Scala, Python y R, y un motor optimizado que admite gráficos de ejecución general. También admite un amplio conjunto de herramientas de nivel superior que incluyen Spark SQL para SQL y procesamiento de datos estructurados, API de pandas en Spark para cargas de trabajo de pandas, MLlib para aprendizaje automático, GraphX para procesamiento de gráficos y Structured Streaming para computación y transmisión incrementales.
1. Introducción¶
Apache Spark es un framework de computación distribuida similar a Hadoop MapReduce, pero en lugar de almacenar los datos en un sistema de ficheros distribuidos o utilizar un sistema de gestión de recursos, lo hace en memoria RAM. El hecho de almacenar en memoria los cálculos intermedios implica que sea mucho más eficiente que MapReduce.
En el caso de tener la necesidad de almacenar los datos o gestionar los recursos, se apoya en sistemas ya existentes como HDFS, S3 o bases de datos SQL para leer y escribir los datos. Por lo tanto, Hadoop y Spark son sistemas complementarios.
2. Características¶
Las características clave de Apache Spark incluyen:
-
Velocidad: Spark es conocido por su capacidad para procesar grandes volúmenes de datos a una velocidad significativamente más alta que otros motores de big data, como Hadoop MapReduce, gracias a su motor DAG (Directed Acyclic Graph) y el procesamiento en memoria. Esto se debe en gran medida a su capacidad para realizar procesamientos en memoria (in-memory processing), lo que minimiza la lectura y escritura en el disco.
-
Facilidad de Uso: Proporciona APIs sencillas para trabajar en lenguajes como Python, Java, Scala y R, lo que hace que sea más accesible para los desarrolladores y analistas de datos. También soporta una variedad de operaciones de datos, como transformaciones y acciones, lo que facilita la manipulación de datos.
-
Procesamiento de Datos en Tiempo Real: A diferencia de Hadoop, que está diseñado principalmente para el procesamiento por lotes, Spark soporta tanto el procesamiento por lotes como el procesamiento en tiempo real, que lo hace adecuado para una gama más amplia de aplicaciones, como la detección de fraudes en tiempo real y el análisis de datos de streaming.
-
Librerías Integradas: Viene con varias librerías integradas, incluyendo Spark SQL para el procesamiento de datos estructurados, MLlib para machine learning, GraphX para el procesamiento de gráficos y Spark Streaming para el procesamiento de datos en tiempo real.
-
Escalabilidad y Flexibilidad: Apache Spark puede ejecutarse en una variedad de entornos, desde una sola máquina hasta clústeres de miles de nodos. Es compatible con varias plataformas de almacenamiento de datos y puede integrarse con sistemas de big data como Hadoop.
-
Spark Connect (Novedad en v4): Una arquitectura cliente-servidor desacoplada que permite conectar IDEs remotos, notebooks y aplicaciones ligeras al clúster de Spark sin depender de la JVM en el cliente. Esto facilita el desarrollo y la interacción con Spark desde diversos entornos.
-
Extensible: Al centrarse únicamente en el procesamiento, la gestión de los datos se puede realizar a partir de Hadoop, Cassandra, HBase, MongoDB, Hive o cualquier SGBD relacional, haciendo todo en memoria RAM. Además, se puede extender el API para utilizar otras fuentes de datos, como Apache Kafka, Amazon S3 o Azure Storage.
En resumen, Apache Spark es una herramienta poderosa y versátil para el procesamiento de big data, apreciada por su velocidad, facilidad de uso y capacidades avanzadas de procesamiento de datos. Su diseño lo hace ideal tanto para el análisis de grandes volúmenes de datos históricos como para aplicaciones que requieren el procesamiento de datos en tiempo real.
3. Spark y Hadoop¶
La principal diferencia es que la computación se realiza en memoria, lo que puede implicar un mejora de hasta 100 veces mejor rendimiento. Para ello, se realiza una evaluación perezosa de las operaciones, de manera, que hasta que no se realiza una operación, los datos realmente no se cargan.
Para solucionar los problemas asociados a MapReduce, Spark crea un espacio de memoria RAM compartida entre los ordenadores del clúster. Este permite que los NodeManager/WorkerNode compartan variables (y su estado), eliminando la necesidad de escribir los resultados intermedios en disco. Esta zona de memoria compartida se traduce en el uso de RDD, DataFrames y DataSets, permitiendo realizar procesamiento en memoria a lo largo de un clúster con tolerancia a fallos.
4. Componentes del Ecosistema¶

-
Apache Spark Core: Spark Core es el motor de ejecución general básico para la plataforma Spark en el que se basan todas las demás funcionalidades. Proporciona registro en memoria y conjuntos de datos conectados en marcos de almacenamiento externos.
-
Spark SQL: Spark SQL es un segmento sobre Spark Core que presenta otra abstracción de información llamada SchemaRDD, que ofrece ayuda para sincronizar información estructurada y no estructurada.
-
Spark Streaming: Spark Streaming utiliza la capacidad de programación rápida de Spark Core para realizar Streaming Analytics. Ingiere información en grupos a escala reducida y realiza cambios de RDD (Conjuntos de datos distribuidos resistentes) en esos grupos de información a pequeña escala.
-
MLlib (Machine Learning Library): MLlib es una estructura de aprendizaje automático distribuido por encima de Spark en vista de la arquitectura Spark basada en memoria distribuida. Es, como lo indican los puntos de referencia, realizado por los ingenieros de MLlib contra las ejecuciones de mínimos cuadrados alternos (ALS).
-
GraphX: GraphX es un marco distribuido de procesamiento de gráficos de Spark. Proporciona una API para comunicar el cálculo del gráfico que puede mostrar los diagramas caracterizados por el cliente utilizando la API de abstracción de Pregel. Asimismo, proporciona un tiempo de ejecución optimizado y mejorado a esta abstracción.
-
Spark R: Esencialmente, para utilizar Apache Spark de R. Es el paquete R el que da una interfaz de usuario ligera. Además, permite a los investigadores de la información desglosar conjuntos de datos expansivos.

5. Flujo de aplicaciones de Spark¶
Una aplicación Spark se compone de dos partes:
- La lógica de procesamiento de los datos, realizada mediante API de Spark(que veremos en el siguiente punto) o la propia shell interactiva.
- Driver: es el coordinador central encargado de interactuar con el clúster Spark y averiguar qué máquinas deben ejecutar la lógica de procesamiento. Para cada una de esas máquinas, el driver realiza una petición para lanzar un proceso conocido como ejecutor (Executor). Además, el driver Spark es responsable de gestionar y distribuir las tareas a cada ejecutor, y si es necesario, recoger y fusionar los datos resultantes para presentarlos al usuario. Estas tareas se realizan a través de la
SparkSession.
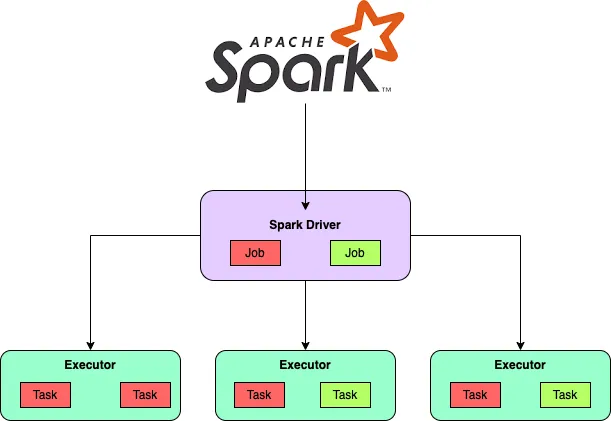
La ejecución se descompone en 3 partes a bajo nivel:
5.1 Spark Job¶
Un Spark Job representa una tarea informática completa que Spark realiza en un conjunto de datos. Consta de múltiples etapas y abarca todos los pasos necesarios para transformar y analizar datos. Los Jobs se envían a Spark a través del driver program y se dividen en unidades más pequeñas llamadas etapas de ejecución (Executor).
5.2 Spark Stage¶
Un Spark Stage es una unidad lógica de trabajo dentro de un Spark Job. Representa un conjunto de tareas que se pueden ejecutar juntas, generalmente como resultado de una transformación estrecha (por ejemplo, map o filter) o una operación aleatoria (por ejemplo, groupByKey o reduceByKey). Las Stages las determina el motor Spark durante la fase de optimización de consultas, en función de las dependencias entre RDDs o DataFrames.
5.3 Spark Task¶
Un Spark Task es la unidad de trabajo más pequeña en Spark. Representa una operación única que se puede ejecutar en un subconjunto de datos particionado. Los nodos trabajadores ejecutan las tareas en paralelo, aprovechando las capacidades informáticas distribuidas de Spark. Cada tarea opera sobre una porción de los datos, aplicando las transformaciones requeridas y produciendo resultados intermedios o finales.
Finalmente, al lanzar una aplicación Spark, podemos indicar el número de ejecutores que necesita la aplicación, así como la cantidad de memoria y número de núcleos que debería tener cada executor.
5.4 Cheat Sheet¶
- Spark Job
- Definición: tarea de cálculo completa realizada por Spark en un conjunto de datos.
- Relación: Consta de múltiples etapas.
- Envío: enviado a Spark a través del driver program.
- Ejecución: Dividido en etapas para ejecución paralela.
- Spark Stage
- Definición: unidad lógica de trabajo dentro de un job de Spark.
- Relación: Comprende un conjunto de tareas que se pueden ejecutar juntas.
- Determinación: determinada durante la optimización de consultas en función de las dependencias de RDD/DataFrame.
- Transformaciones: normalmente asociadas con operaciones estrechas o aleatorias.
- Spark Task:
- Definición: unidad de trabajo más pequeña en Spark.
- Ejecución: ejecutada en paralelo por nodos workers.
- Subconjunto de datos: opera en un subconjunto de datos particionado.
- Operaciones: realiza las transformaciones requeridas en los datos.
5.5 Comprender el flujo¶
- Se envía un Spark Job a Spark para su procesamiento.
- El Job se divide en Stage según las transformaciones y dependencias en el cálculo.
- Cada Stage consta de múltiples Tasks que se pueden ejecutar en paralelo.
- Las Tasks se asignan a nodos Workers, que realizan los cálculos necesarios en las particiones de datos que se les asignan.
- Los resultados intermedios y finales se producen a medida que las tareas completan sus cálculos.
- El trabajo general se completa cuando todas las Stages y Tasks terminan de ejecutarse.
6. Spark Connect: Arquitectura Desacoplada¶
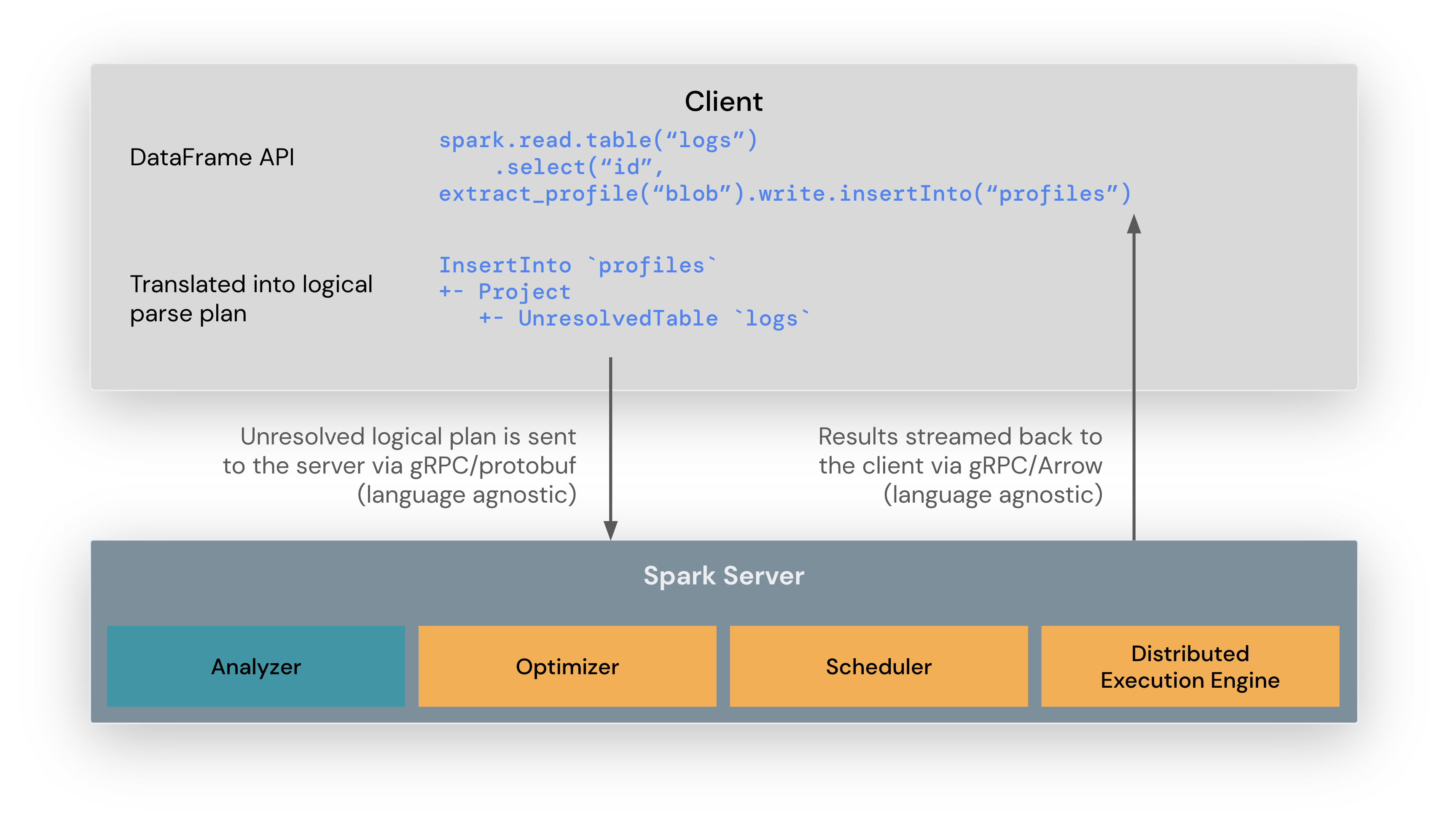
Con la llegada de Spark 3.4 y su consolidación en Spark 4.0, se introduce Spark Connect, una arquitectura cliente-servidor desacoplada que resuelve uno de los mayores dolores de cabeza históricos de Spark: la dependencia del cliente.
Tradicionalmente, cuando ejecutabas una aplicación Spark desde tu equipo, imagen y/o contenedor (ej. usando pyspark o spark-submit), tu máquina actuaba como el Driver.
- Requisito: Debía tener instalada la misma versión de Java, Scala y librerías que el clúster.
- Fragilidad: Si tu script de Python fallaba o tu red parpadeaba, podías tumbar el trabajo entero en el clúster.
- Pesadez: El cliente era "pesado", consumiendo recursos significativos.
6.1 La Solución: Spark Connect¶
Spark Connect introduce una capa intermedia basada en el protocolo gRPC.

- Cliente Ligero ("Thin Client"): Ahora, tu script de Python (en VS Code, Jupyter, etc.) no arranca una JVM. Simplemente usa una librería ligera que traduce tus comandos de DataFrame a mensajes de protocolo (Protocol Buffers).
- Comunicación gRPC: Estos mensajes viajan por la red hasta el servidor de Spark Connect.
- Servidor: El servidor (que se ejecuta en el clúster) recibe el plan, lo traduce, lo optimiza y lo ejecuta.
6.2 Beneficios¶
- Estabilidad: Si tu cliente se desconecta, la sesión en el servidor puede mantenerse viva. Un fallo en el cliente no impacta la integridad del clúster.
- Desarrollo Remoto: Puedes programar en Python desde tu máquina local conectándote a un clúster remoto (Docker, Kubernetes, Cloud) sin instalar Java ni Hadoop en tu local. ¡Solo necesitas
pip install pyspark-connect! - Políglota Real: Facilita enormemente el uso de Spark con lenguajes que no son de la JVM, como Go o Rust, ya que solo necesitan implementar el cliente gRPC.
6.3 Roles¶
Para entender los roles en esta arquitectura que desplegaremos:
- Spark Master: Solo gestiona los recursos y sabe qué Workers están libres.
- Spark Workers: Hacen el trabajo duro (procesar datos).
- Spark Connect Server: Es la nueva pieza. Recibe código, por ejemplo Python, desde el cliente, lo traduce a Tasks y se lo pide al Spark Master para que asigne Workers.
Si Spark Connect Server se desconecta o falla, el cluster sigue funcionando.
6.4 Ejemplo de uso (Python)¶
La diferencia principal radica en la inicialización de la sesión. En lugar de Usamos remote() en lugar de master(), apuntando a una dirección remota usando el esquema sc://.
from pyspark.sql import SparkSession
# En lugar de master("local"), apuntamos al servidor Spark Connect
# Ejemplo: sc://localhost:15002 es el puerto por defecto de Spark Connect
spark = SparkSession.builder.remote("sc://localhost:15002").getOrCreate()
# A partir de aquí, el código es idéntico al estándar
df = spark.sql("SELECT 'Hola Spark Connect' as mensaje")
df.show()
Spark Connect en nuestros Laboratorios
En nuestros despliegues (que veremos más adelante), Spark Connect nos permitirá (en ejercicios futuros) ejecutar scripts de Python desde nuestro ordenador anfitrión (Host) que se comuniquen directamente con Spark en el clúster, sin necesidad de copiar el script dentro del contenedor ni instalar Java en nuestro Windows/Mac/Linux.