UD 6 - Apache Spark - Spark Streaming¶
1. Stream Processing¶
Antes de empezar a estudiar Spark Streaming, es recomendable hacer una pequeña introducción a Stream Processing
1.1 ¿Qué es el Stream Processing?¶
El stream processing está basado en la idea de procesar los datos de forma continua. En cuanto estos datos están disponibles se procesan de manera secuencial. Para ello, se usan flujos de datos infinitos y sin límites de tiempo. La manera tradicional de procesar los datos ha sido en batches, agrupados en grandes lotes, esta técnica se llama batch processing.
Actualmente, los servicios en tiempo real que usan estos mecanismos de stream processing cada vez tienen más demanda. A través de estas técnicas es posible acelerar la velocidad a la que se obtiene valor de los datos y generar acciones para interaccionar con los clientes con poca latencia.
Generalmente, las latencias que se consideran al hablar de los sistemas de tiempo real o de stream processing son del orden de 10 milisegundos a 1 segundo. En función del caso de uso o el ámbito de su aplicación, estas latencias pueden reducirse, aunque supondrán importantes desafíos.
Los requisitos más importantes a tener en cuenta a la hora de implementar una solución analítica en streaming son los siguientes:
- Cantidad de datos que se deben procesar de forma simultánea (picos de carga)
- Latencias extremo a extremo (end to end)
- Garantías de entrega de mensajes que debe asegurar la solución
1.2 Casos de uso de Streaming¶
Las fuentes de datos para casos de uso de stream processing pueden estar presentes en cualquier sector, a continuación tienes listados los más populares:
- Monitorización de sistemas, de redes y de aplicaciones
- Dispositivos Internet of Things (IoT)
- Sistemas de recomendación y optimización de resultados
- Transacciones financieras, detección de fraude y trading
- Seguimiento de usuarios en páginas web y comercio electrónico
- Notificaciones en dispositivos y aplicaciones móviles en tiempo real
Los procesos y flujos de trabajo con datos en streaming más usados son los filtros, la agregación y el enriquecimiento de datos, es decir, realizar un adecuado ETL adaptado a la solución de un entorno real. Esto nos permite reducir la cantidad de información, calcular agregados de datos en ventanas temporales, reducir la cantidad de información persistida, entre otras. También nos permite el enriquecimiento, agregar información a un dataset en tiempo real. Esto ofrece ventajas respecto a enriquecerla cuando ya se encuentra persistida en un almacenamiento, y es que permite tomar decisiones más rápido con los datos.
1.2 Conceptos Básicos en Stream Processing¶
A continuación vamos a desarrollar algunos conceptos y términos básicos que se han generado alrededor de las tecnologías de stream processing.
Los sistemas de streaming distribuidos tienen tres maneras de gestionar las garantías de entrega de los mensajes en sus protocolos:
- At-least-once: Garantiza que el mensaje siempre se entregará. Es posible que en caso de fallo se entregue varias veces, pero no se perderá ningún mensaje en el sistema.
- At-most-once: Garantiza que el mensaje se entregará una vez o no se entregará. Un mensaje nunca se entregará más de una vez.
- Exactly-once: Garantiza que todos los mensajes se van a entregar exactamente una vez, realizando el sistema las comprobaciones necesarias para que esto suceda.
Existen numerosas aplicaciones que no se pueden permitir la existencia mensajes duplicados o perdidos debido a fallos en la comunicación o en las aplicaciones. Por esta razón es tan importante que existan sistemas que garanticen la entrega exactamente una vez como Apache Kafka o Flink.
-
Tupla o evento: conjunto de elementos o de tipos de datos simples guardados de forma consecutiva. También, los podemos llamar eventos o mensajes. Los eventos representan un cambio de estado en el sistema y normalmente tienen un orden basado en el tiempo.
-
Flujo de datos: También llamado stream o stream de eventos. Se trata de una secuencia infinita de tuplas o de eventos en la que el orden importa. Este flujo de datos viaja desde los productores hacia los consumidores de datos.
-
Ventanas de procesamiento: Dividen los datos de entrada en partes finitas. Permiten tratar las secuencias infinitas con unos recursos limitados como la memoria del sistema. Pueden estar basadas en tiempo o en el número de elementos y se pueden desplazar a medida que se procesa su contenido. Existen varios tipos de ventanas dependiendo de las características del sistema.
-
Operaciones con y sin estado: Las operaciones sin estado permiten obtener un resultado por cada uno de los eventos procesados. Las operaciones con estado operan sobre un conjunto de elementos para generar una salida.
Para mantener la tolerancia a fallos, los sistemas de streaming usan checkpointing y no eliminan los eventos del sistema una vez procesados. De esta manera, almacenan de forma persistente el estado del sistema en instantes de tiempo y el punto en el que se encuentran para poder recuperar la información en el caso de que ocurra algún fallo de red o en los propios nodos.
- Backpressure: Es el mecanismo que indica a la tecnología que los consumidores no pueden procesar más eventos en un instante concreto. Evita que el sistema se sature cuando se publican eventos a más velocidad de la que se consumen. Normalmente, se implementa un mecanismo de buffering. Si se excede su capacidad, se pueden eliminar los eventos con una política definida de tipo LIFO, FIFO, etc. La capacidad de escalar junto a un buen mecanismo de backpressure son esenciales para garantizar la alta disponibilidad y el rendimiento del sistema.
2. Spark Streaming¶
Spark Streaming es una extensión del core Spark API que permite el procesamiento de flujos de datos en forma continua, escalables, de alto rendimiento y tolerante a fallos. Los datos se pueden ingerir de muchas fuentes, como Kafka, Kinesis o sockets TCP, y se pueden procesar utilizando algoritmos complejos expresados con funciones de alto nivel como map, reduce, join and window. Finalmente, los datos procesados se pueden enviar a sistemas de archivos, bases de datos y paneles de control en tiempo real. De hecho, puede aplicar los algoritmos de procesamiento de gráficos y aprendizaje automático de Spark en flujos de datos.

Spark tiene 2 soluciones de Streaming:
- Spark DStream: Generación previa del motor Spark Streaming. Está basada en RDDs
- Spark Structured Streaming: Introducido en Spark 2.0, está basada en el uso de Dataframe. Facilita la creación de aplicaciones y canalizaciones en tiempo real usando las APIs Spark.
2.1 DStream¶
Internamente funciona de la siguiente manera. Spark Streaming recibe flujos de datos de entrada en tiempo real(stream) y los divide en lotes (batch), que luego son procesados por el motor Spark para generar el flujo final de resultados en lotes.
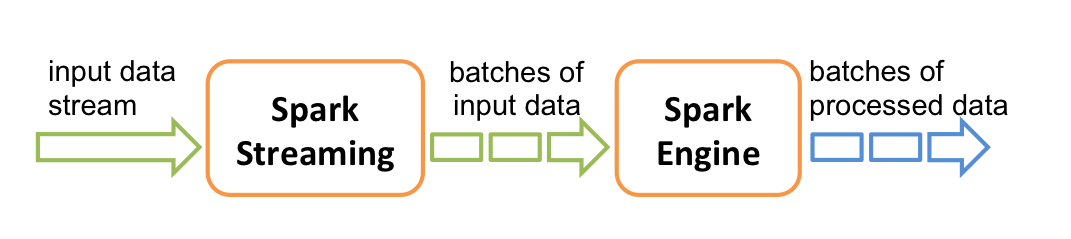
Spark Streaming proporciona una abstracción de alto nivel llamada discretized stream o DStream, que representa un flujo continuo de datos. Los DStreams se pueden crear a partir de flujos de datos de entrada de fuentes como Kafka y Kinesis, o aplicando operaciones de alto nivel en otros DStreams. Internamente, un DStream se representa como una secuencia de RDD.
2.2 Spark Structured Streaming¶
Structured Streaming es un motor de stream processing escalable y tolerante a fallos integrado en el motor Spark SQL. El motor Spark SQL se encargará de ejecutarlo de forma incremental y continua y de actualizar el resultado final a medida que sigan llegando datos de streaming. También se crean canalizaciones y aplicaciones de streaming de baja latencia y coste eficiente.
Puede utilizar la API Dataset/DataFrame en Scala, Java, Python o R para expresar agregaciones de transmisión, ventanas de tiempo de evento, join y uniones de stream a batch, etc. Finalmente, el sistema garantiza tolerancia a fallos de extremo a extremo mediante la entrega de mensajes de una sola vez (exactly-once) a través de checkpointing y logs.
Además, proporciona las mismas API estructuradas (DataFrames y Datasets) que Spark, por lo que no es necesario desarrollar ni mantener (ni aprender) dos stack de tecnología diferentes para batch y streaming. Además, las API unificadas facilitan la migración de sus trabajos Spark por lotes existentes a trabajos de transmisión.

Internamente, de forma predeterminada, las consultas de Structured Streaming se procesan utilizando un micro-batch processing engine, que procesa flujos de datos como una serie de pequeños trabajos por lotes, logrando así latencias de extremo a extremo tan bajas como 100 milisegundos y garantías de tolerancia a fallos exactly-once.
2.3. Spark Structured Streaming. Programming Model¶
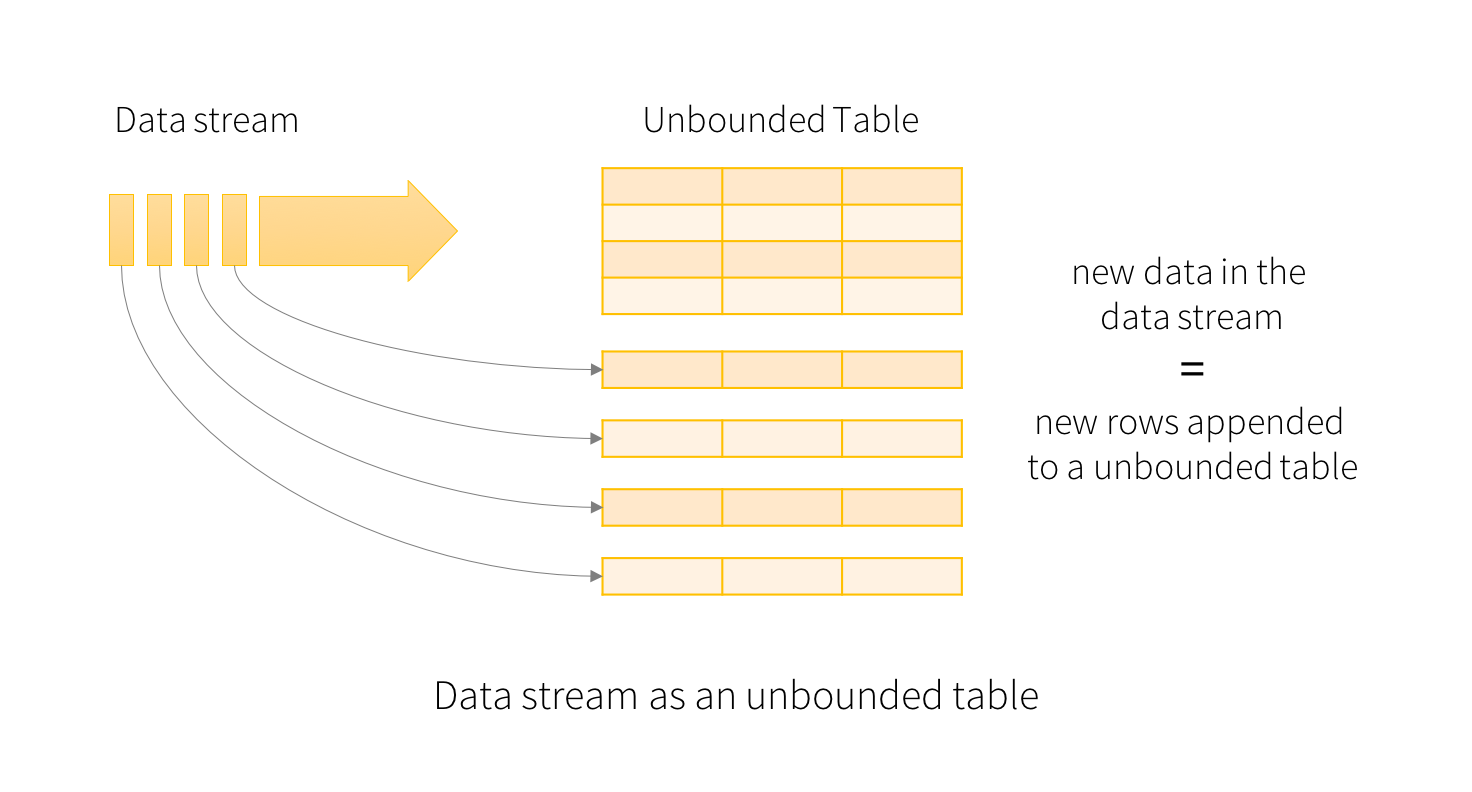
La idea clave en Structured Streaming es tratar un flujo de datos en tiempo real como una tabla que se agrega continuamente. Esto conduce a un nuevo modelo de procesamiento de flujos que es muy similar al modelo de procesamiento batch. Expresará su cálculo de transmisión como una consulta estándar batch como en una tabla estática, y Spark lo ejecutará como una consulta incremental en la tabla de entrada ilimitada.
Si consideramos el flujo de datos de entrada como la "Input Table". Cada elemento de datos que llega a la secuencia es como una nueva fila que se agrega a la tabla de entrada.
Info
En el contexto de Apache Spark, "unbounded" se refiere generalmente a datos que no tienen un límite definido en el tiempo, es decir, datos que continúan llegando de manera continua sin un punto final específico. Esto se contrasta con "bounded", que se refiere a conjuntos de datos con un límite claro y definido.
Una consulta sobre la entrada generará la “Result Table”. En cada intervalo de activación (por ejemplo, cada segundo), se agregan nuevas filas a la tabla de entrada, que eventualmente actualiza la tabla de resultados. Cada vez que se actualiza la tabla de resultados, queremos escribir las filas de resultados modificadas en un receptor externo.
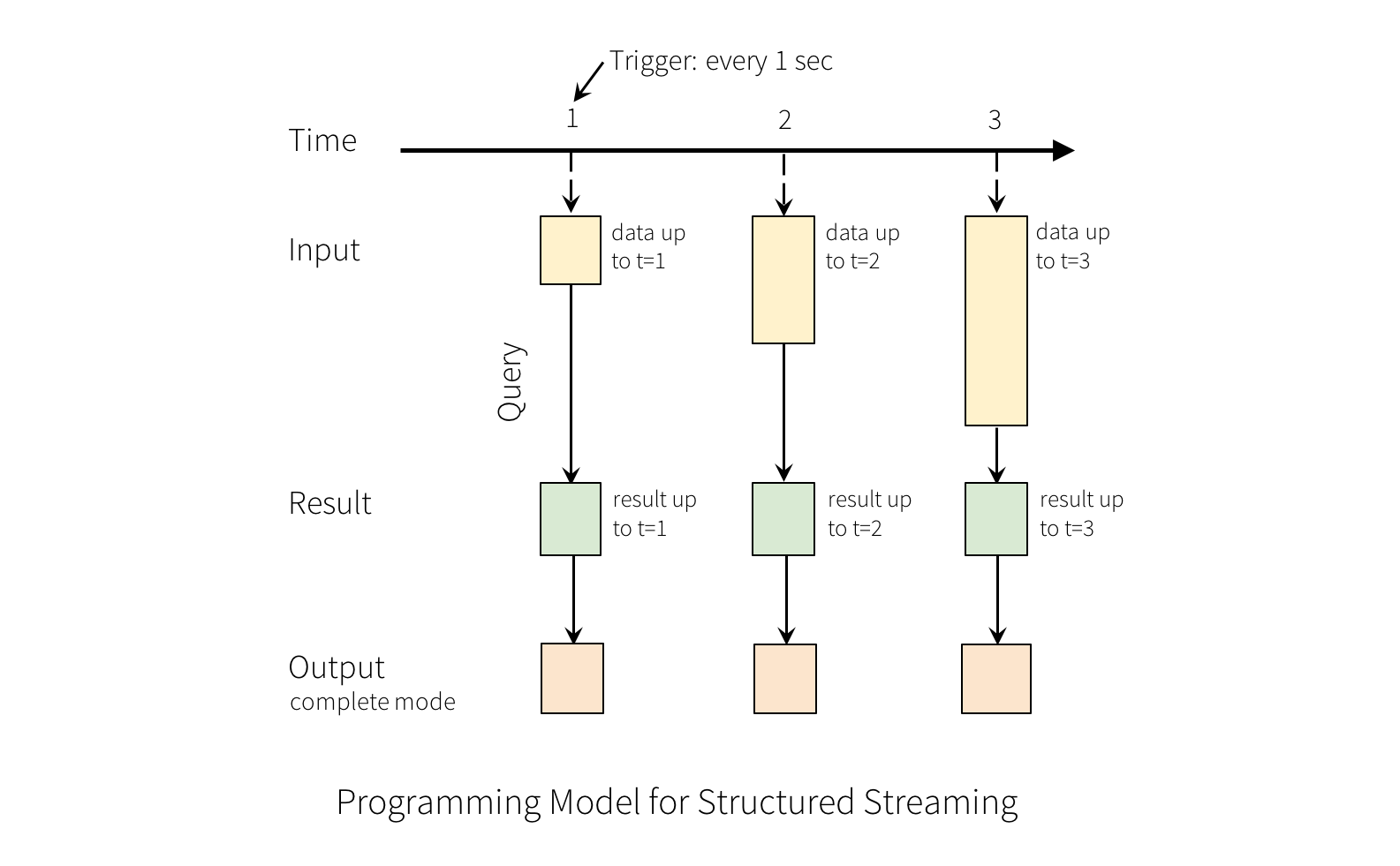
Note
En el siguiente punto profundizaremos sobre los "Outputs"
Handling Event-time and Late Data¶
Event-time (tiempo del evento) es el tiempo incrustado en los datos mismos. Para muchas aplicaciones, es posible que queramos operar en este momento del evento. Por ejemplo, si desea obtener la cantidad de eventos generados por dispositivos IoT cada minuto, entonces probablemente queramos usar la hora en la que se generaron los datos (es decir, la hora del evento en los datos), en lugar de la hora a la que la recibe Spark. Este tiempo de evento se expresa de manera muy natural en este modelo: cada evento de los dispositivos es una fila en la tabla y el tiempo de evento es un valor de columna en la fila.
Esto permite que las agregaciones basadas en ventanas (por ejemplo, número de eventos por minuto) sean solo un tipo especial de agrupación y agregación en la columna de tiempo del evento: cada ventana de tiempo es un grupo y cada fila puede pertenecer a múltiples ventanas/grupos. Por lo tanto, dichas consultas de agregación basadas en ventanas de tiempo de eventos se pueden definir de manera consistente tanto en un conjunto de datos estáticos (por ejemplo, a partir de registros de eventos de dispositivos recopilados) como en un flujo de datos, lo que hace la vida del usuario mucho más fácil.
Continuous Processing
Desde Spark 2.3, existe un nuevo modo de ejecución llamado continuous processing (procesamiento continuo) que permite una baja latencia de extremo a extremo baja (~1 ms) con garantías de tolerancia a fallas exactly-once. Está en fase experimental y la trataremos cuando entre en versión estable
3. Arquitectura Spark Streaming¶
Una vez vista las 2 soluciones que ofrece Spark Streaming, vamos a intentar dar una pequeña representación de la Arquitectura y WorkFlow de Spark Streaming.
Spark Streaming, de forma general, y dejando atrás muchas particularidades:
- Recepción de datos (inputs) en tiempo real de diferentes fuentes (source)
- Estos son procesados por la lógica de procesamiento
- Los datos de salida (outputs) del procesamiento, la envía a diferentes "almacenamientos externos" o sumideros (sink) y en un modo (mode) determinado. Vamos a dar una pequeña explicación de cada uno de ellos
3.1 Input source¶
Algunas de las fuentes integradas. Puedes consultarlas todas en input source
-
File source: Lee archivos de un directorio como un flujo de datos. Los archivos se procesarán en el orden de modificación del archivo. Los formatos de archivo admitidos son texto, CSV, JSON, ORC, Parquet.
-
Socket source (for testing): Lee datos de texto UTF8 desde una conexión de socket. Esta fuente de datos escuchará el socket especificado e incorporará cualquier dato en Spark Streaming. Se utiliza únicamente para pruebas.
-
Rate source (for testing): Genera automáticamente datos que incluyen 2 columnas que contienen
timestampandvalue. Dondetimestampes un tipo de marca de tiempo que contiene la hora de envío del mensaje yvalue, que es Long Type y contiene el recuento de mensajes, comenzando desde 0 como primera fila. Se utiliza únicamente para pruebas. -
Rate Per Micro-Batch source (for testing): Genera automáticamente datos especificando el número de filas por micro-batch. Cada fila de salida contiene
timestampandvalue. -
Kafka source: lee datos de Kafka. Es compatible con las versiones 0.10.0 o superiores de Kafka broker. Consulte la Guía de integración de Kafka para obtener más detalles.
3.2 Output Mode¶
Output Mode se define como lo que se escribe en el almacenamiento externo. La salida se puede definir en un modo diferente:
-
Complete Mode: toda la tabla de resultados actualizada se escribirá en el almacenamiento externo. Depende del conector de almacenamiento decidir cómo manejar la escritura en toda la tabla.
-
Append Mode: solo las nuevas filas agregadas en la tabla de resultados desde el último trigger se escribirán en el almacenamiento externo. Esto solo se aplica a las consultas en las que no se espera que cambien las filas existentes en la tabla de resultados.
-
Update Mode: solo las filas que se actualizaron en la tabla de resultados desde el último trigger se escribirán en el almacenamiento externo (disponible desde Spark 2.1.1). Debemos tener en cuenta que esto es diferente del complete mode en que este modo solo genera las filas que han cambiado desde el último trigger. Si la consulta no contiene agregaciones, será equivalente al append mode.
Info
Hay que tener en cuenta que cada modo es aplicable a ciertos tipos de consultas. Esto se analiza en detalle más adelante.
3.3 Output Sinks¶
Output Sinks indican a que tipo de almacenamiento externo se envían los datos procesados.
- File sink: Almacena el contenido del Dataframen en un fichero dentro de un directorio. Los tipos de archivos admitidos son
csv, json, orc, and parquet.
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
- Kafka sink: Publica los datos en uno o mas topics en Kafka.
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
- Memory sink (for debugging): la salida se almacena en la memoria como una tabla en memoria. Se admiten append y complete mode. Esto debe usarse con fines de depuración en volúmenes de datos bajos, ya que toda la salida se recopila y almacena en la memoria del controlador.
Para comprender el modelo, lo veremos paso a paso en el Ejemplo1.
4. Ejemplo 1. Custom Wordcount¶
Supongamos que queremos mantener un recuento continuo de palabras de los datos de texto recibidos de un servidor de datos que escucha en un socket TCP.
Observa con detalle la descripción de la documentación oficial de cada enlace y los métodos que tiene.
- Tenemos que importar las clases necesarias y crear una
SparkSessionlocal, el punto de partida de todas las funcionalidades relacionadas con Spark.
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetwork_CustomWordCount_BDA") \
.getOrCreate()
-
Creamos un streaming DataFrame que represente datos de texto recibidos de un servidor que escucha en localhost:9999 y transformemos el DataFrame para calcular el recuento de palabras.
-
Source (fuente de datos): Creamos un flujo de lectura con
readStream. Como puedes ver en la documentación, éste devuelve unDataStreamReaderque será usado para crear un streaming DataFrame. - Indicamos el formato tipo socket y el resto de configuración y lo cargamos con load() para que devuelva el DataFrame
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
-
Realizamos ahora la lógica de procesamiento en cualquieras de las APIs Spark(Dataframe API y/o Spark SQL)
-
linesva a contener ahora el DataFrame resultante del texto recogido en streaming. - Partimos las palabras de cada línea por un espacio
- Contamos las palabras agrupando por el alias
word
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
-
Configuramos la salida de los datos ya procesados (sink) con
writeStreamque devuelve unDataStreamWriter- Configuramos un output sink por consola
- Configuramos un output mode complete
- Iniciamos con start()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
- Por último, Dejamos a la con
awaitTermination()
- La aplicación completa sería:
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetwork_CustomWordCount_BDA") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
# Waiting
query.awaitTermination()
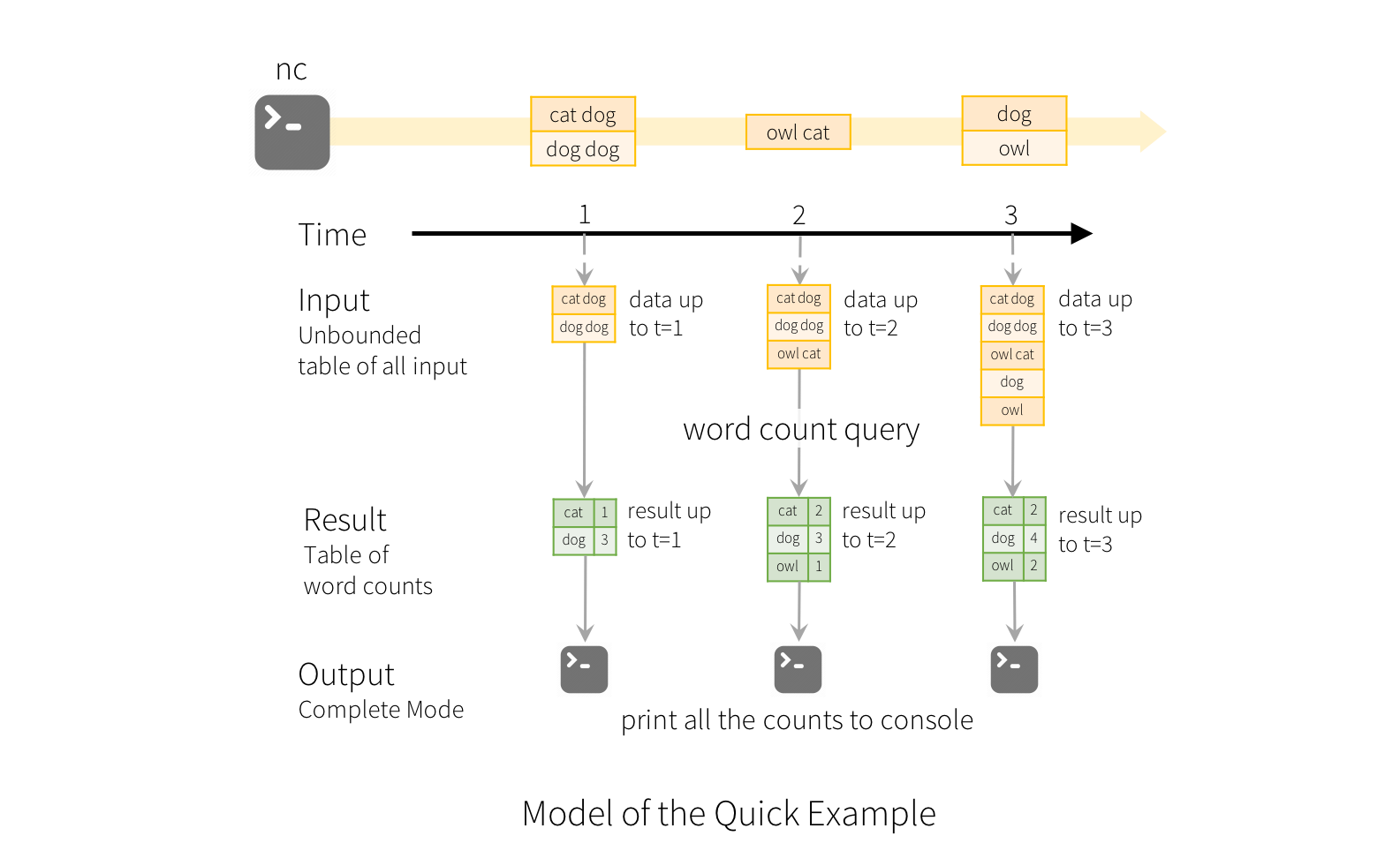
- Ejecutamos el comando NetCat en el puerto 9999 que es donde nuestra app estará escuchando
- Ejecutamos nuestra app de Spark Streaming
Ejecución
Puedes realizar el ejercicio tanto en Databricks como en nuestro propio cluster. Para DataBricks debes tener activo "Web Terminal" en la configuración de usuario: Usuario -> Settings -> Workspace admin -> Compute -> Web Terminal (Enabled). Para ver la salida, accede a Driver logs -> Standard output (No podrás verlo en tiempo real, tendrás que ir actualizando, a diferencia de en nuestro propio cluster Spark).
En nuestro cluster, puedes tanto ejecutarlo con spark-submit o pyspark, ya sea como shell o levantando jupyter
- Ejecutado en Databrick
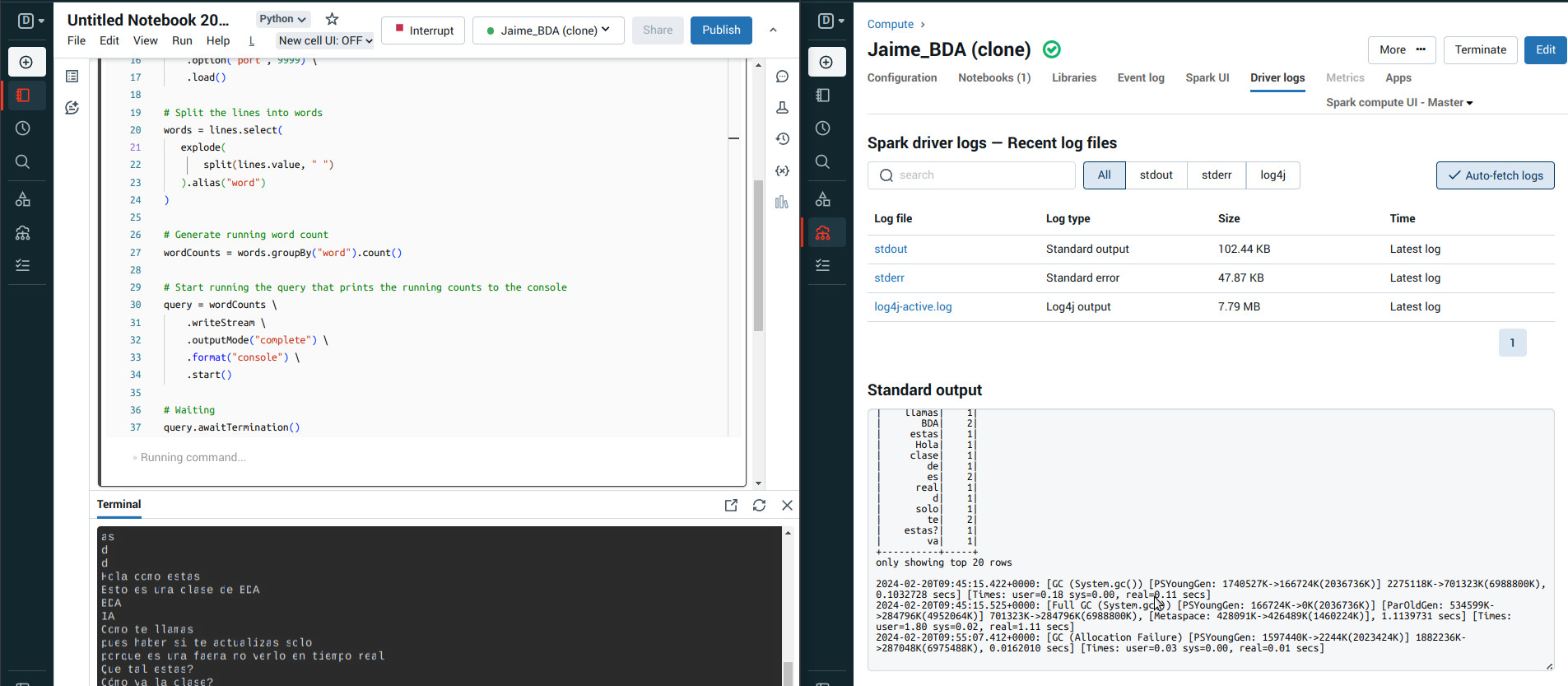
- Ejecutado en nuestro cluster
5. Ejemplo2. Usando Rate Source¶
Vamos a usar ratesource y consolesink. Rate Source generará automáticamente datos que luego imprimiremos en consola.
- Tenemos que importar las clases necesarias y crear una
SparkSessionlocal, el punto de partida de todas las funcionalidades relacionadas con Spark.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("Ejemplo2_BDA") \
.getOrCreate()
- Establecemos el nivel de registro en
Errorpara evitar los logs deWarningeINFO.
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
- Creamos un streaming DataFrame usando
rate source. Especificamos el formatoratey las filas por segundo a 1 para generar 1 fila para cada microbatch y cargar los datos en el DataFrame de transmisión dedf_init. Además, verificamos si df_init es un DataFrame de transmisión o no.
df_init = spark \
.readStream \
.format("rate") \
.option("rowsPerSecond", 1) \
.load()
print("Streaming DataFrame : " + str(df_init.isStreaming))
La salida debería decir lo siguiente:
- Lógica de procesamiento: Realizamos una transformación básica
df_initpara generar otra columnaresultsimplemente sumando1a la columnavalue:
- Configuramos la salida de los datos ya procesados. Usamos
append modepara generar solo los datos recién generados y usamosconsole sinkpara mostrarlos por consola.
df_result \
.writeStream \
.outputMode("append") \
.option("truncate", False)
.format("console") \
.start() \
.awaitTermination()
- La aplicación completa sería:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("Ejemplo2_BDA") \
.getOrCreate()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
df_init = spark \
.readStream \
.format("rate") \
.option("rowsPerSecond", 1) \
.load()
print("Streaming DataFrame : " + str(df_init.isStreaming))
df_result = df_init \
.withColumn("result", col("value") + lit(1))
df_result \
.writeStream \
.outputMode("append") \
.option("truncate", False) \
.format("console") \
.start() \
.awaitTermination()
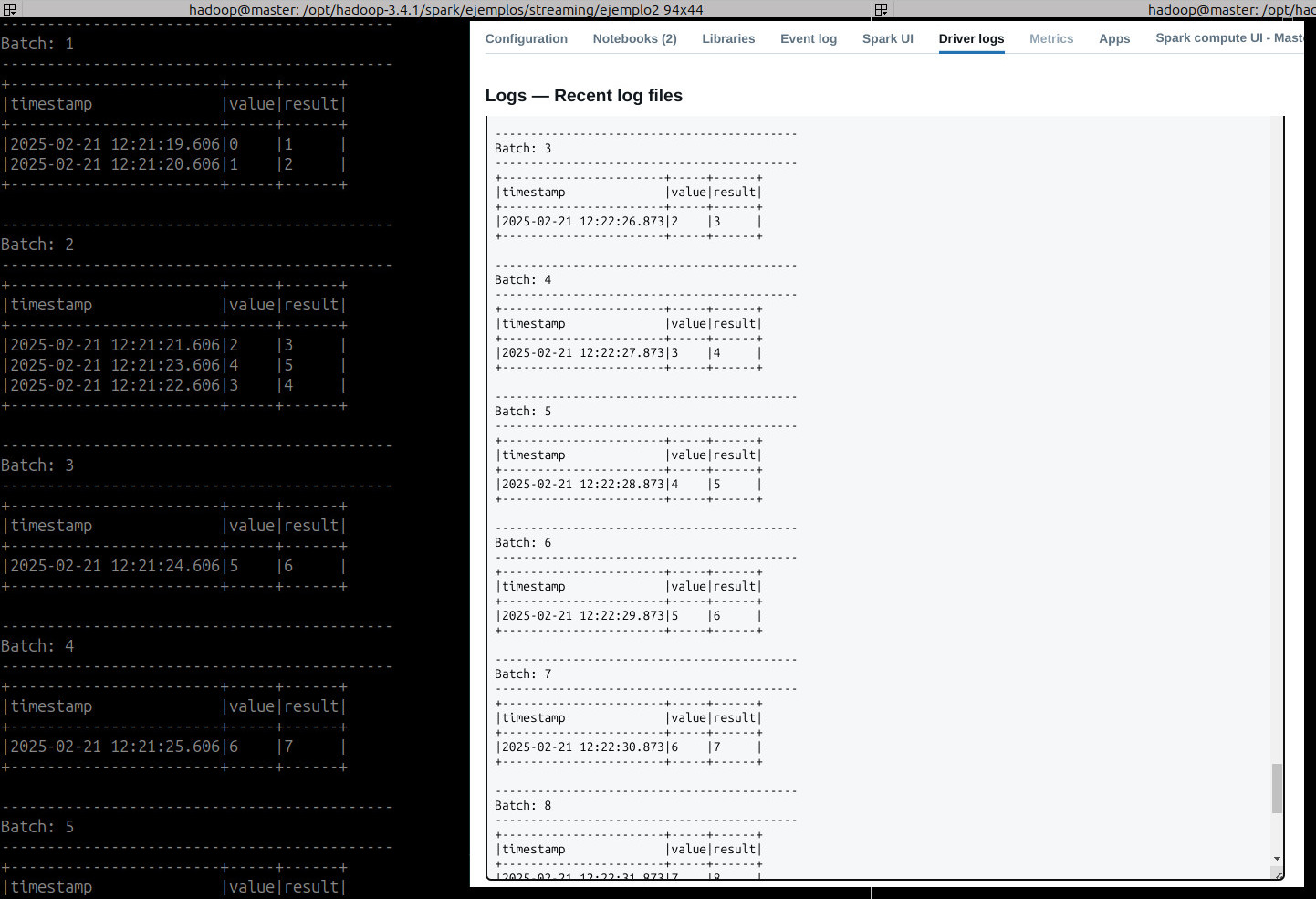
- Salida
-------------------------------------------
Batch: 1
-------------------------------------------
+-----------------------+-----+------+
|timestamp |value|result|
+-----------------------+-----+------+
|2025-02-21 12:21:19.606|0 |1 |
|2025-02-21 12:21:20.606|1 |2 |
+-----------------------+-----+------+
-------------------------------------------
Batch: 2
-------------------------------------------
+-----------------------+-----+------+
|timestamp |value|result|
+-----------------------+-----+------+
|2025-02-21 12:21:21.606|2 |3 |
|2025-02-21 12:21:23.606|4 |5 |
|2025-02-21 12:21:22.606|3 |4 |
+-----------------------+-----+------+
-------------------------------------------
Batch: 3
-------------------------------------------
+-----------------------+-----+------+
|timestamp |value|result|
+-----------------------+-----+------+
|2025-02-21 12:21:24.606|5 |6 |
+-----------------------+-----+------+
-------------------------------------------
Batch: 4
-------------------------------------------
+-----------------------+-----+------+
|timestamp |value|result|
+-----------------------+-----+------+
|2025-02-21 12:21:25.606|6 |7 |
+-----------------------+-----+------+
- Ejecución en nuestro cluster y Databrick
6. Ejemplo 3. Stock Exchange Data¶
Vamos a usar file y consolesink.
File System Databricks
Puedes realizar el ejercicio tanto en Databricks como en nuestro propio cluster. Para DataBricks necesitas acceder al DBFS: Catalog -> DBFS -> FileStore -> shared_uploads -> tu_usuario o la ruta que tu tengas. Desde aquí upload y arrastráis la carpeta. Spark Streaming no lee archivos que ya estuvieran en el directorio, sólo los nuevos que van llegando
Para poder usar DBFS hay que activar DBFS File Browser. Para ello debes activar "DBFS File Browser" en la configuración de usuario: Usuario -> Admin settings -> Workspace setting -> DBFS File Browser (Enabled)
En nuestro cluster, sólo tienes que indicar la ruta del directorio de los ficheros para su lectura en streaming
-
Preparación del ejemplo. Para este ejemplo, dentro del directorio he creado dos carpetas:
dataystream, para ir añadiendo los ficheros de la carpeta data a stream y spark streaming los vaya leyendo. -
Vamos a usar como base el siguiente dataset de datos de precios diarios para índices que rastrean las bolsas de valores de todo el mundo de kaggle
-
Lo he partido en 4 partes para poder realizar la lectura de streaming de ficheros de un directorio
wget https://gist.githubusercontent.com/jaimerabasco/6a82b19a4f7aa3d855e4ae9d9e38df97/raw/7c066340d055b9f0943abfefa8d63aa32cdd70b4/indexData_part1.csv
wget https://gist.githubusercontent.com/jaimerabasco/6a82b19a4f7aa3d855e4ae9d9e38df97/raw/7c066340d055b9f0943abfefa8d63aa32cdd70b4/indexData_part2.csv
wget https://gist.githubusercontent.com/jaimerabasco/6a82b19a4f7aa3d855e4ae9d9e38df97/raw/7c066340d055b9f0943abfefa8d63aa32cdd70b4/indexData_part3.csv
wget https://gist.githubusercontent.com/jaimerabasco/6a82b19a4f7aa3d855e4ae9d9e38df97/raw/7c066340d055b9f0943abfefa8d63aa32cdd70b4/indexData_part4.csv
- Código del programa
- Creamos el schema
- Leemos en el directorio los ficheros entrantes (input files)
- Agrupamos por indice bursátil y valor más alto por año
- Mostramos en consola
- Prueba Output mode update y complete
- Está realizado en Dataframe API
- Comentada hay una versión Spark SQL
6.1 Databricks¶
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = SparkSession \
.builder \
.appName("Spark_Streaming_Ejemplo3_BDA") \
.getOrCreate()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
schema = StructType([
StructField("Index", StringType(), True),
StructField("Date", DateType(), True),
StructField("Open", DoubleType(), True),
StructField("High", DoubleType(), True),
StructField("Low", DoubleType(), True),
StructField("Close", DoubleType(), True),
StructField("Adj Close", DoubleType(), True),
StructField("Volume", LongType(), True)
])
# option("maxFilesPerTrigger",2) => This will read maximum of 2 files per mini batch. However, it can read less than 2 files.
df_init = spark \
.readStream \
.format("csv") \
.option("maxFilesPerTrigger",2) \
.option("header", True) \
.option("path", "dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream") \
.schema(schema) \
.load()
df_result = df_init.groupBy(col("Index"), year(col("Date")).alias("Year")) \
.agg(max("High").alias("Max"))
df_init.printSchema()
# Registramos el DataFrame como una vista temporal
#df_init.createOrReplaceTempView("stockView")
# Ejecutar la consulta SQL
#query = """
#SELECT year(Date) AS Year, Index, max(High) AS Max
#FROM stockView
#GROUP BY Index, Year
#"""
#df_result = spark.sql(query)
#df_result = df_init \
# .withColumn("result", col("value") + lit(1))
# Intenta update y complete mode para entender la diferencia
df_result \
.writeStream \
.outputMode("update") \
.option("truncate", False) \
.option("numRows", 3) \
.format("console") \
.start() \
.awaitTermination()
# .option("numRows", 3) => Indica el número de filas que muestra por consola
-
Una vez ejecutado el programa se queda esperando la entrada de ficheros en el directorio indicado.
-
Realizar el ejercicio en Databricks lleva asociado algunas acciones añadidas:
- Al no tener acceso a Databricks CLI desde web terminal no podemos mover los archivos desde la terminal con
databricks fs cp dbfs:/<ruta_local> dbfs:/<ruta_destino> - Por tanto, tendremos que hacerlo desde el notebook. Para ello usaremos
dbutils.fs - Como el notebook del ejercicio, una vez que lo lancemos, va a estar escuchando, no podemos ejecutar otro código en el mismo notebook. Por tanto, crearemos otro donde ejecutaremos el código para preparar el entorno e ir copiando los ficheros del directorio
dataastreaam - Para ello iremos ejecutando el siguiente código a medida que lo vayamos necesitando. Es importante el orden, ya que no debemos lanzar la aplicación sin limpiar antes de ficheros el directorio
stream
- Al no tener acceso a Databricks CLI desde web terminal no podemos mover los archivos desde la terminal con
#Creamos el directorio stream, si no lo estuviera. SOLO LA PRIMERA VEZ
dbutils.fs.mkdirs("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream")
# Cada vez que queramos probarlo, realizamos:
# Limpiamos el directorio stream ANTES DE LANZAR EL EJEMPLO
dbutils.fs.rm("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part1.csv")
dbutils.fs.rm("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part2.csv")
dbutils.fs.rm("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part3.csv")
dbutils.fs.rm("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part4.csv")
#UNA VEZ LANZADO EL EJEMPLO, vamos copiando uno a uno mientras observamos la salida en la consola en drivers_logs de Databrick
# Primera parte del dataset
dbutils.fs.cp("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/data/indexData_part1.csv","dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part1.csv")
# Segunda parte del dataset
dbutils.fs.cp("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/data/indexData_part2.csv","dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part2.csv")
# Tercera parte del dataset
dbutils.fs.cp("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/data/indexData_part3.csv","dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part3.csv")
# Cuarta parte del dataset
dbutils.fs.cp("dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/data/indexData_part4.csv","dbfs:/FileStore/shared_uploads/jaimerabasco@iesgrancapitan.org/spark_streaming_ejemplo3/stream/indexData_part4.csv")
- Seguidos los pasos obtenemos la siguiente salida
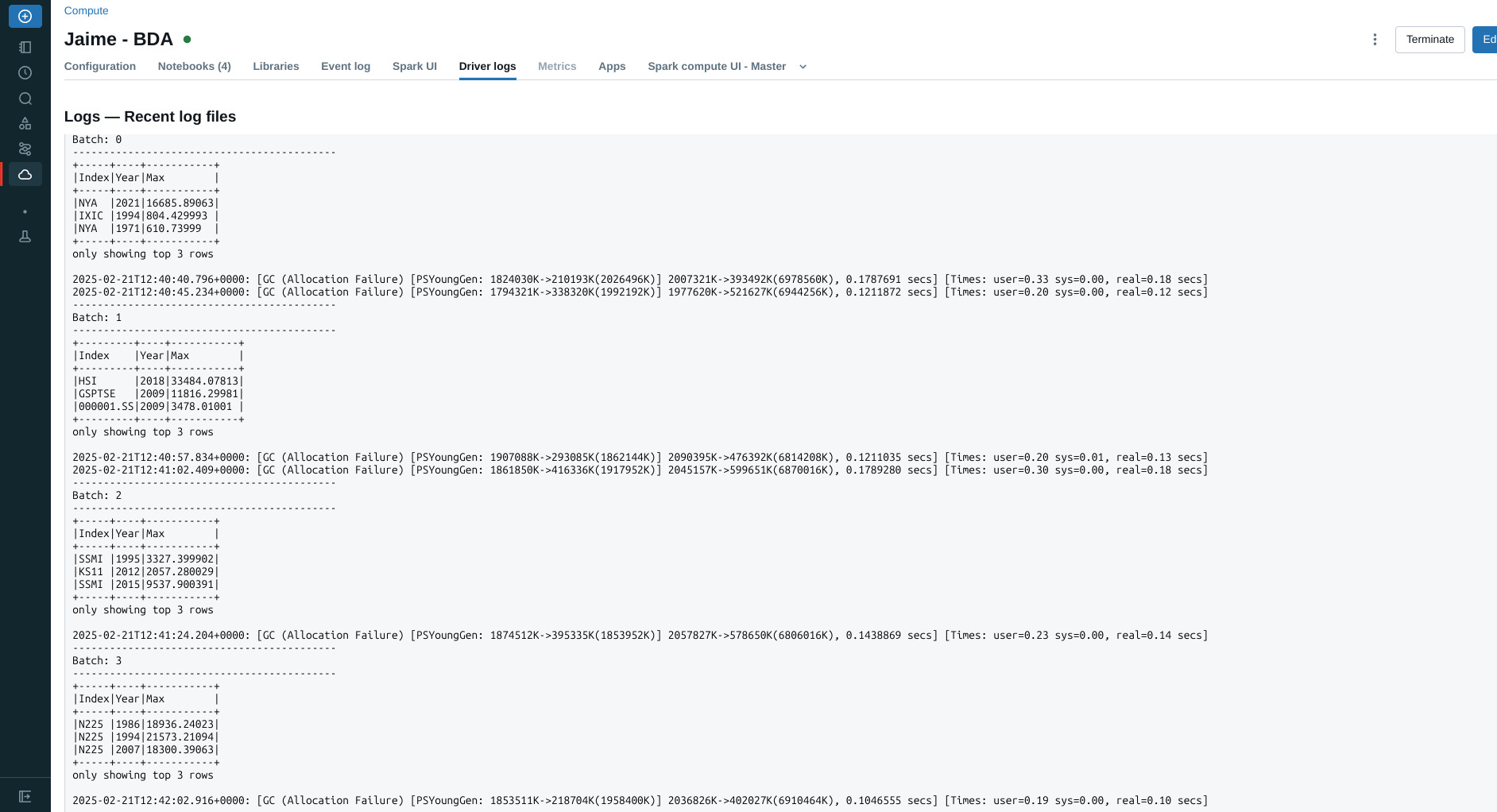
6.2 Cluster propio¶
- Debemos tener en cuenta que tenemos que indicar correctamente el directorio de lectura de ficheros en el código fuente. Para ello, y siguiendo la documentación, hay que indicar si es del sistemas de ficheros, hdfs, S3
file://,hdfs:,s3:,... - Esto lleva asociado una serie de consideraciones importantes. Todos los workers deben tener acceso al directorio de lectura de ficheros. Si optamos por la opción del sistema de ficheros, sólo podremos ejecutarlo en el nodo donde se encuentre el directorio, ya que los workers que estén en otro nodo no tendrán acceso al directorio local donde lancemos la app de Spark.
- Si por el contrario, usamos una fuente distinta (
hdfs:,s3:,...), no tendremos ese problema siempre y cuando todos los workers tengan acceso al directorio, como sería en este caso - Vamos a ver, a modo de ejemplo, los 2 casos.
Sistema de ficheros local¶
- Código del programa. Para nuestro cluster, vamos a suponer que lo realizamos desde el nodo
master
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = SparkSession \
.builder \
.appName("Spark_Streaming_Ejemplo3_BDA") \
.getOrCreate()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
schema = StructType([
StructField("Index", StringType(), True),
StructField("Date", DateType(), True),
StructField("Open", DoubleType(), True),
StructField("High", DoubleType(), True),
StructField("Low", DoubleType(), True),
StructField("Close", DoubleType(), True),
StructField("Adj Close", DoubleType(), True),
StructField("Volume", LongType(), True)
])
# option("maxFilesPerTrigger",2) => This will read maximum of 2 files per mini batch. However, it can read less than 2 files.
df_init = spark \
.readStream \
.format("csv") \
.option("maxFilesPerTrigger",2) \
.option("header", True) \
.option("path", "file:///opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3/stream/") \
.schema(schema) \
.load()
df_result = df_init.groupBy(col("Index"), year(col("Date")).alias("Year")) \
.agg(max("High").alias("Max"))
df_init.printSchema()
# Registramos el DataFrame como una vista temporal
#df_init.createOrReplaceTempView("stockView")
# Ejecutar la consulta SQL
#query = """
#SELECT year(Date) AS Year, Index, max(High) AS Max
#FROM stockView
#GROUP BY Index, Year
#"""
#df_result = spark.sql(query)
#df_result = df_init \
# .withColumn("result", col("value") + lit(1))
# Intenta update y complete mode para entender la diferencia
df_result \
.writeStream \
.outputMode("update") \
.option("truncate", False) \
.option("numRows", 3) \
.format("console") \
.start() \
.awaitTermination()
- Lanzamos spark master y un worker en el nodo
master(Recuerda que estamos realizando el input desde el sistema de ficherosmaster, por eso lanzamos unworkerenmaster, ya que si lo ejecutamos usando todos los nodos del cluster,nodo1, nodo2 y nodo3no tienen acceso al sistema de ficheros demaster. Más adelante tenemos el ejemplo para hacerlo con HDFS)
hadoop@master:/opt/hadoop-3.4.1/spark-3.5.4$ ./sbin/start-master.sh
hadoop@master:/opt/hadoop-3.4.1/spark-3.5.4$ ./sbin/start-worker.sh spark://192.168.11.10:7077
- Lanzamos el programa. Recuerda antes borrar todos los ficheros del directorio
stream
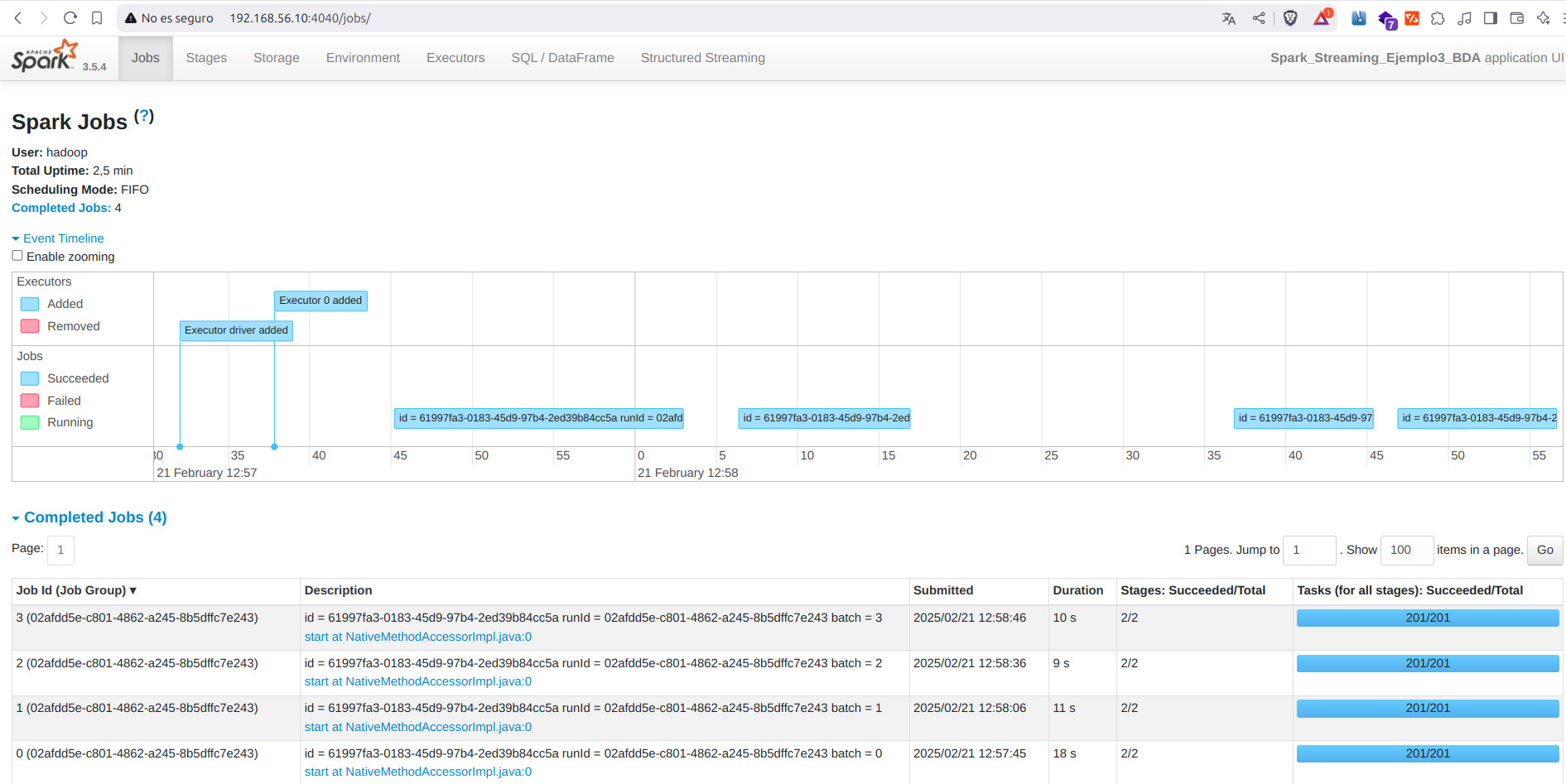
spark-submit --master spark://192.168.11.10:7077 /opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3/ejemplo3_input_file.py
- Copia los input files en el directorio
streamuno a uno
hadoop@master:/opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3$ cp data/indexData_part1.csv stream/
hadoop@master:/opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3$ cp data/indexData_part2.csv stream/
hadoop@master:/opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3$ cp data/indexData_part3.csv stream/
hadoop@master:/opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3$ cp data/indexData_part4.csv stream/
- Salida en consola
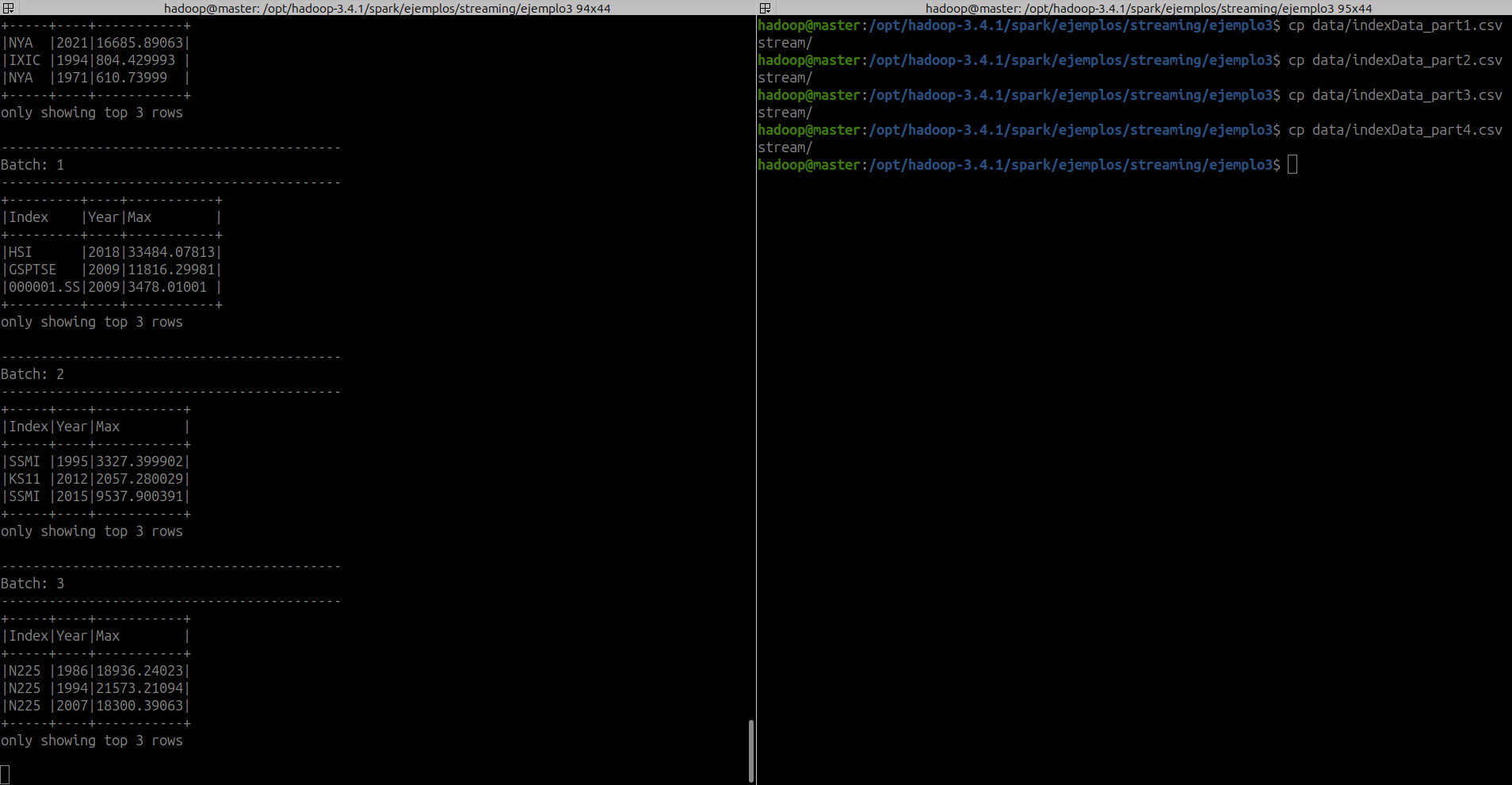
- Spark UI
HDFS¶
- Código del programa. Para nuestro cluster, vamos a suponer que lo realizamos desde el nodo
master
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = SparkSession \
.builder \
.appName("Spark_Streaming_Ejemplo3_BDA") \
.getOrCreate()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
schema = StructType([
StructField("Index", StringType(), True),
StructField("Date", DateType(), True),
StructField("Open", DoubleType(), True),
StructField("High", DoubleType(), True),
StructField("Low", DoubleType(), True),
StructField("Close", DoubleType(), True),
StructField("Adj Close", DoubleType(), True),
StructField("Volume", LongType(), True)
])
# option("maxFilesPerTrigger",2) => This will read maximum of 2 files per mini batch. However, it can read less than 2 files.
df_init = spark \
.readStream \
.format("csv") \
.option("maxFilesPerTrigger",2) \
.option("header", True) \
.option("path", "hdfs:///bda/spark/ejemplos/streaming/ejemplo3/stream") \
.schema(schema) \
.load()
df_result = df_init.groupBy(col("Index"), year(col("Date")).alias("Year")) \
.agg(max("High").alias("Max"))
df_init.printSchema()
# Registramos el DataFrame como una vista temporal
#df_init.createOrReplaceTempView("stockView")
# Ejecutar la consulta SQL
#query = """
#SELECT year(Date) AS Year, Index, max(High) AS Max
#FROM stockView
#GROUP BY Index, Year
#"""
#df_result = spark.sql(query)
#df_result = df_init \
# .withColumn("result", col("value") + lit(1))
# Intenta update y complete mode para entender la diferencia
df_result \
.writeStream \
.outputMode("update") \
.option("truncate", False) \
.option("numRows", 3) \
.format("console") \
.start() \
.awaitTermination()
- Lanzamos spark master y los workers del cluster. Recuerda tener levantado HDFS y los directorios y ficheros ya creados
hadoop@master:/opt/hadoop-3.4.1/spark-3.5.4$ ./sbin/start-master.sh
hadoop@master:/opt/hadoop-3.4.1/spark-3.5.4$ ./sbin/start-workers.sh
- Lanzamos el programa. Recuerda antes borrar todos los ficheros del directorio
stream
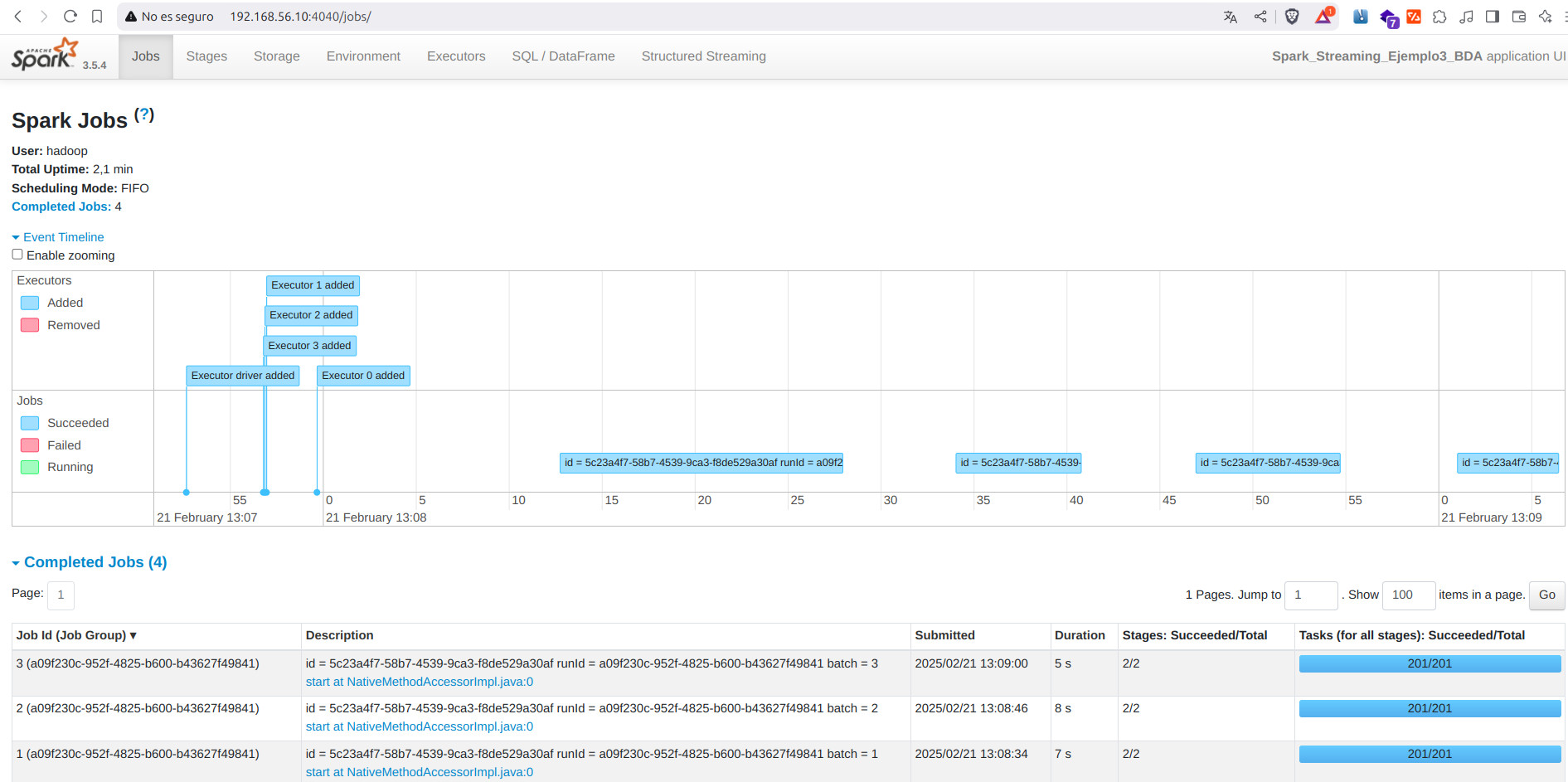
spark-submit --master spark://192.168.11.10:7077 /opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo3/ejemplo3_input_hdfs.py
- Copia los input files en el directorio
streamuno a uno
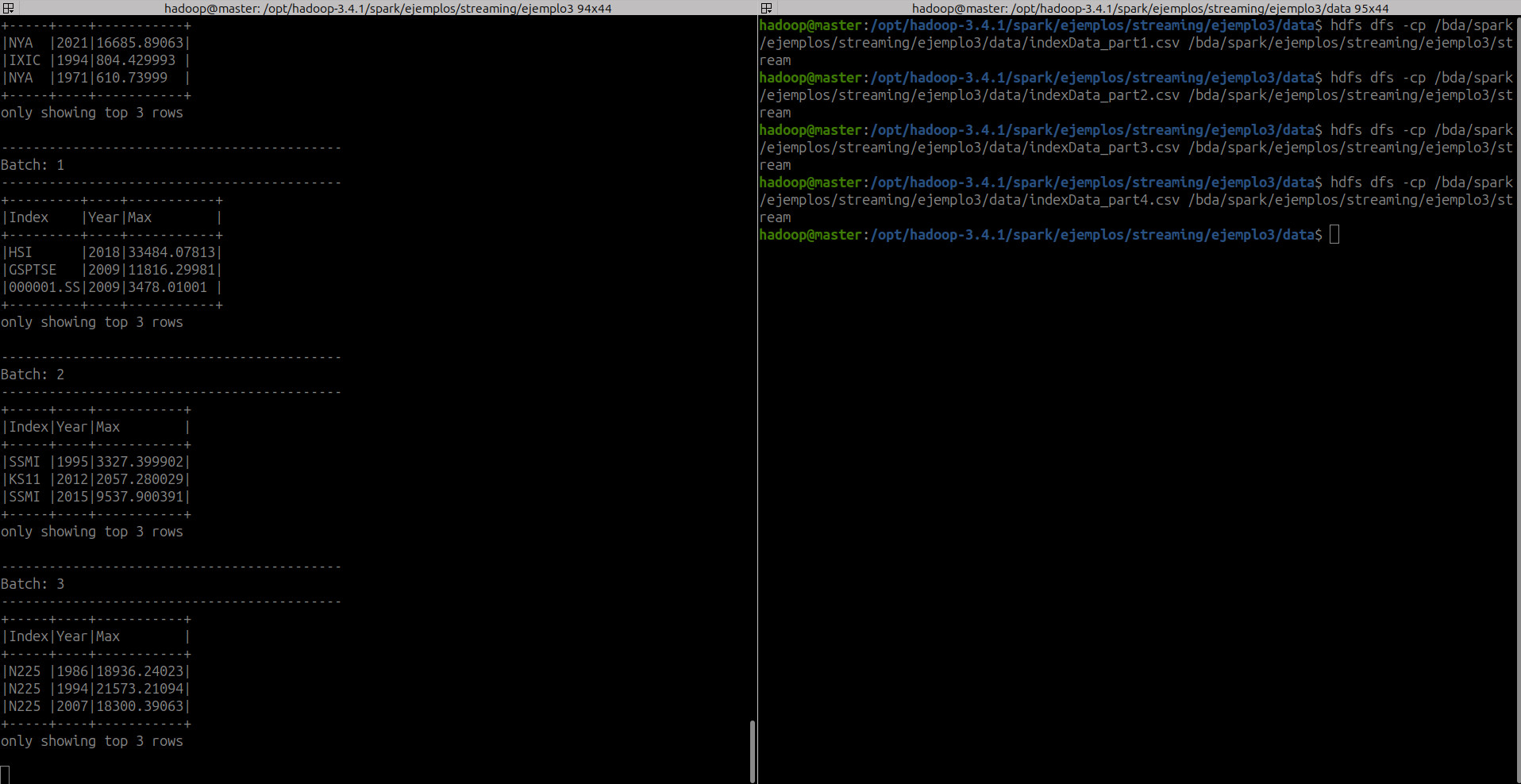
hdfs dfs -cp /bda/spark/ejemplos/streaming/ejemplo3/data/indexData_part1.csv /bda/spark/ejemplos/streaming/ejemplo3/stream
hdfs dfs -cp /bda/spark/ejemplos/streaming/ejemplo3/data/indexData_part2.csv /bda/spark/ejemplos/streaming/ejemplo3/stream
hdfs dfs -cp /bda/spark/ejemplos/streaming/ejemplo3/data/indexData_part3.csv /bda/spark/ejemplos/streaming/ejemplo3/stream
hdfs dfs -cp /bda/spark/ejemplos/streaming/ejemplo3/data/indexData_part4.csv /bda/spark/ejemplos/streaming/ejemplo3/stream
- Salida en consola
- Spark UI
Plataformas a usar
Como ya hemos visto todas las opciones de solución en las diferentes plataformas, y sabemos usarlas, para los siguientes ejemplos se usarán sólo una de estas soluciones.
7. Window Operations¶
Como hemos visto en el punto 2.3 en la sección "Handling Event-time and Late Data", las operaciones de ventana (window operations) en Spark Streaming permiten agrupar datos en ventanas de tiempo para realizar cálculos agregados. Estas operaciones son esenciales para el procesamiento de flujos de datos en tiempo real, especialmente cuando se necesita analizar datos en intervalos específicos.
Hay tres tipos principales de operaciones de ventana en Spark Streaming: Tumbling (fixed) Windows, Sliding Windows y Session Windows. Cada uno tiene un propósito y uso específico dependiendo del tipo de análisis temporal que necesites realizar.
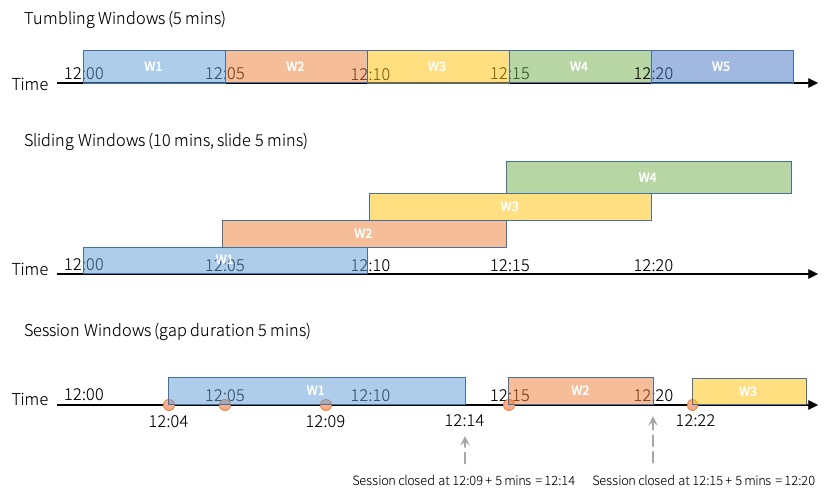
- Tamaño fijo (tumbling/fixed window): son ventanas de tiempo fijas y discretas que no se superponen entre sí. Cada elemento del stream solo puede pertenecer a una ventana. Estas ventanas avanzan en el tiempo de forma secuencial sin solaparse. Son útiles para casos de uso donde quieres realizar cálculos agregados en intervalos de tiempo regulares y no necesitas solapamientos entre los intervalos.
- Deslizantes (sliding window): permiten que las ventanas de tiempo se solapen. Estas ventanas tienen dos parámetros principales: el tamaño de la ventana (window length) y el deslizamiento de la ventana (slide interval). El tamaño de la ventana determina cuánto tiempo abarca cada ventana, mientras que el deslizamiento de la ventana especifica con qué frecuencia se inicia una nueva ventana. Esto significa que los elementos pueden pertenecer a múltiples ventanas, lo que es útil para análisis más finos y detallados que requieren superposiciones
- De sesión (session windows): son dinámicas y se adaptan al comportamiento de los datos, agrupándolos en ventanas según la actividad del usuario o eventos específicos. Estas ventanas no tienen un tamaño fijo; en cambio, se definen por períodos de inactividad o gaps. Si no ocurren eventos nuevos dentro de un período de tiempo especificado (el gap de inactividad), la ventana se cierra, y cualquier evento nuevo iniciará una nueva ventana.
Para entender como funciona, vamos a basarnos en el ejemplo 1.
Modificaremos este programa para entender windowing. En lugar de realizar recuentos de palabras, queremos contar palabras en períodos de 10 minutos y actualizarlas cada 5 minutos. Es decir, contamos las palabras recibidas entre ventanas de 10 minutos, 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20, etc. Ten en cuenta que 12:00 - 12:10 significa datos que llegaron después de las 12:00 pero antes de las 12:10.

Ahora, usando sliding window con intervalos cada 5 minutos, podemos considerar que una palabra que se recibió a las 12:07 incrementará los conteos correspondientes a dos ventanas: 12:00 - 12:10 y 12:05 - 12:15. Por lo tanto, los recuentos serán indexados tanto por la clave de agrupación (es decir, la palabra) como por la ventana (se puede calcular a partir de la hora del evento).
A continuación, haremos 2 modificaciones en el ejemplo 1 para entender las diferencias entre fixed y sliding window
8. Ejemplo 4. Custom wordcount windowing¶
8.1 Fixed window¶
- Vamos a modificar el código para agrupar datos en una ventana fija de 1 minuto. Cuando leamos los datos, queremos obtener el timestamp de cada dato.
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.functions import window
spark = SparkSession \
.builder \
.appName("CustomWordCount_BDA_fixed_window") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.option("includeTimestamp", True)\
.load()
- Obtenemos el texto escrito en el campo
valuey sutimestamp:
lines.printSchema()
# root
# |-- value: string (nullable = true)
# |-- timestamp: timestamp (nullable = true)
- Preparamos el Dataframe para recoger el texto escrito y us timestamp
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")).alias("word"),
lines.timestamp
)
window
# Generate running word count
wordCounts = words.groupBy("word").count()
windowedCounts = words.groupBy(
window(words.timestamp, "1 minute"),
words.word
).count().orderBy("window")
- Configuramos la salida de los datos por consola
# Start running the query that prints the running counts to the console
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.option('truncate', 'false')\
.format("console") \
.start()\
.awaitTermination()
- La aplicación completa sería:
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.functions import window
spark = SparkSession \
.builder \
.appName("CustomWordCount_BDA_fixed_window") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.option("includeTimestamp", True)\
.load()
spark.sparkContext.setLogLevel("ERROR")
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")).alias("word"),
lines.timestamp
)
# Generate running word count
wordCounts = words.groupBy("word").count()
windowedCounts = words.groupBy(
window(words.timestamp, "1 minute"),
words.word
).count().orderBy("window")
# Start running the query that prints the running counts to the console
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.option('truncate', 'false')\
.format("console") \
.start()\
.awaitTermination()
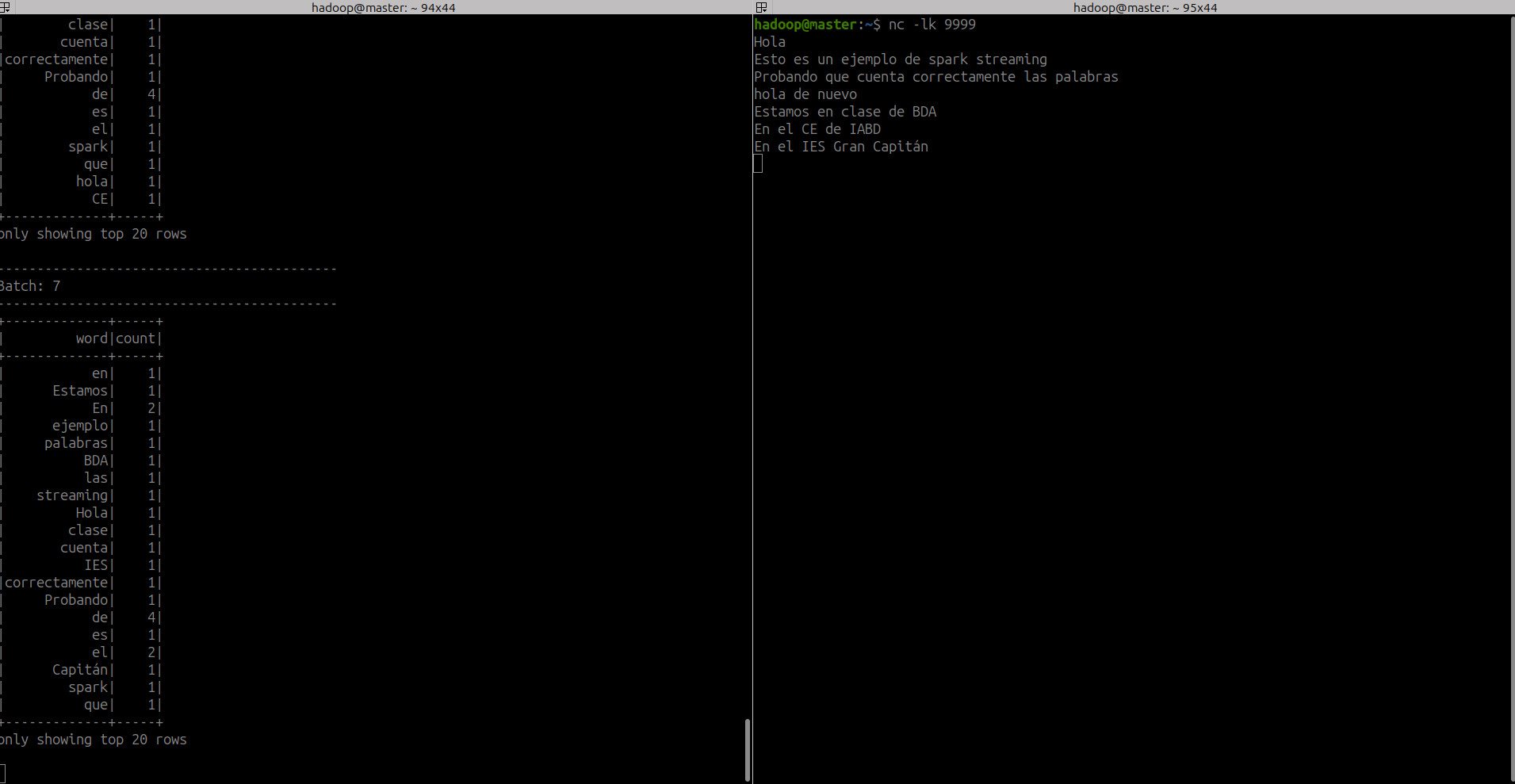
- Ejecutamos el comando NetCat en el puerto 9999 que es donde nuestra app estará escuchando
-
Ejecutamos nuestra app de Spark Streaming
-
Añadimos al socket lo siguiente en el minuto
18:58:00-18:59:00
- Y tenemos
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Hola|1 |
+------------------------------------------+----+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+-------+-----+
|window |word |count|
+------------------------------------------+-------+-----+
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Capitán|1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Gran |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Estamos|1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Hola |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|IES |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|el |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|en |1 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 3
-------------------------------------------
+------------------------------------------+--------+-----+
|window |word |count|
+------------------------------------------+--------+-----+
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|ventana |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Probando|1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|BDA |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Capitán |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Gran |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Estamos |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Hola |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|IES |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|el |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Módulo |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|en |1 |
+------------------------------------------+--------+-----+
- En el siguiente minuto añadimos
Probando ventanay obtenemos:
-------------------------------------------
Batch: 4
-------------------------------------------
+------------------------------------------+--------+-----+
|window |word |count|
+------------------------------------------+--------+-----+
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|ventana |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Probando|1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|BDA |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Capitán |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Gran |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Estamos |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Hola |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|IES |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|el |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|Módulo |1 |
|{2025-02-24 18:58:00, 2025-02-24 18:59:00}|en |1 |
|{2025-02-24 18:59:00, 2025-02-24 19:00:00}|ventana |1 |
|{2025-02-24 18:59:00, 2025-02-24 19:00:00}|Probando|1 |
+------------------------------------------+--------+-----+
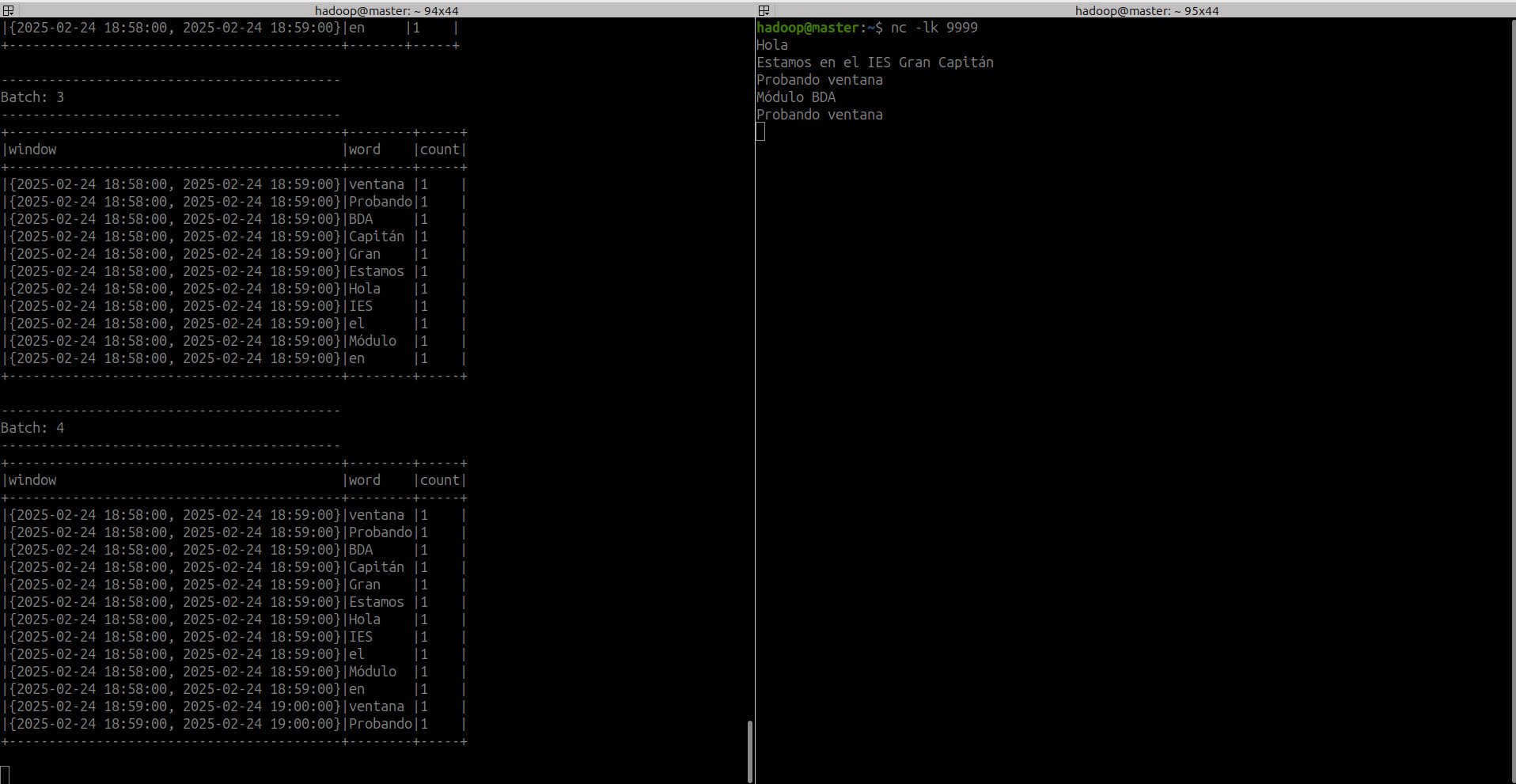
8.2 Sliding window¶
- Cambiamos la siguiente parte del código para que mantenga la ventana de 1 minuto pero ahora tenga un deslizamiento de 30 segundos.
# Generate running word count
wordCounts = words.groupBy("word").count()
windowedCounts = words.groupBy(
window(words.timestamp, "1 minute", "30 seconds"),
words.word
).count().orderBy("window")
- La aplicación completa sería:
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.functions import window
spark = SparkSession \
.builder \
.appName("CustomWordCount_BDA_sliding_window") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.option("includeTimestamp", True)\
.load()
spark.sparkContext.setLogLevel("ERROR")
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")).alias("word"),
lines.timestamp
)
# Generate running word count
wordCounts = words.groupBy("word").count()
windowedCounts = words.groupBy(
window(words.timestamp, "1 minute", "30 seconds"),
words.word
).count().orderBy("window")
# Start running the query that prints the running counts to the console
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.option('truncate', 'false')\
.format("console") \
.start()\
.awaitTermination()
- Ejecutamos el comando NetCat en el puerto 9999 que es donde nuestra app estará escuchando
-
Ejecutamos nuestra app de Spark Streaming
-
Añadimos al socket
Hola IES Gran Capitánen el timestamp19:07:10. Esto hace que introduzca las 3 palabras en las 2 ventanas existentes
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+-------+-----+
|window |word |count|
+------------------------------------------+-------+-----+
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Hola |1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Gran |1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Capitán|1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|IES |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Gran |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Hola |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Capitán|1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|IES |1 |
+------------------------------------------+-------+-----+
- Si añadimos
Hola mundo, el siguiente microbatch lo añade en las ventanas correspondientes. Observa que hola en la ventana19:07:30-19:08:30aparece 2 veces.
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+-------+-----+
|window |word |count|
+------------------------------------------+-------+-----+
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Hola |1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Gran |1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|Capitán|1 |
|{2025-02-24 19:06:30, 2025-02-24 19:07:30}|IES |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Big |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Data |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Gran |1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Hola |2 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|Capitán|1 |
|{2025-02-24 19:07:00, 2025-02-24 19:08:00}|IES |1 |
|{2025-02-24 19:07:30, 2025-02-24 19:08:30}|Hola |1 |
|{2025-02-24 19:07:30, 2025-02-24 19:08:30}|Data |1 |
|{2025-02-24 19:07:30, 2025-02-24 19:08:30}|Big |1 |
+------------------------------------------+-------+-----+
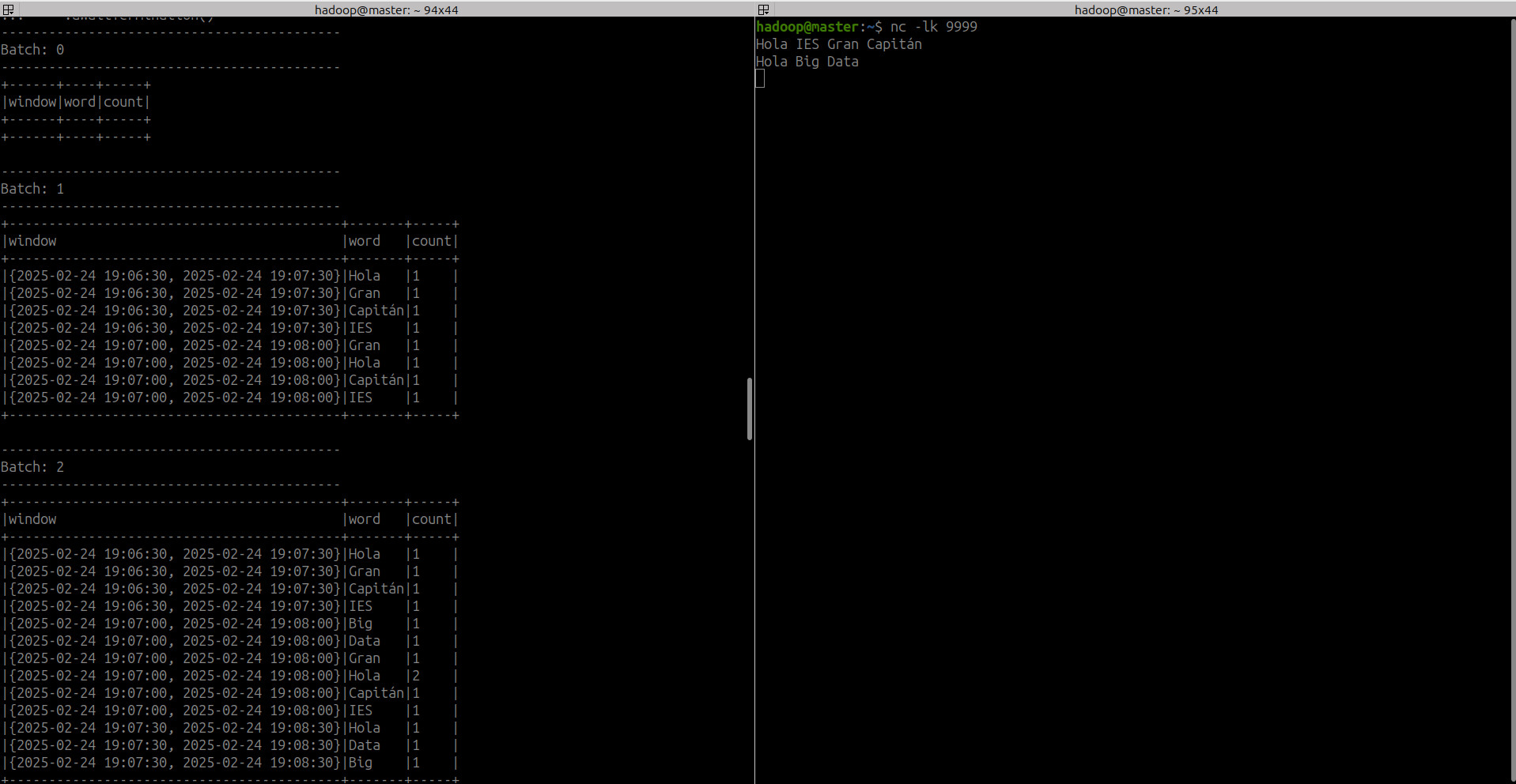
9. Watermarking¶
En términos generales, cuando se trabaja con datos en streaming, habrá retrasos entre el tiempo del evento y el tiempo de procesamiento debido a cómo se ingieren los datos y si la aplicación en general experimenta problemas como tiempo de inactividad. Debido a estos posibles retrasos variables, el motor que utiliza para procesar estos datos debe tener algún mecanismo para decidir cuándo cerrar las ventanas agregadas y producir el resultado agregado.
Para explicar esto visualmente, vamos a usar 2 escenarios:
9.1 Escenario 1. Temperatura y presión¶
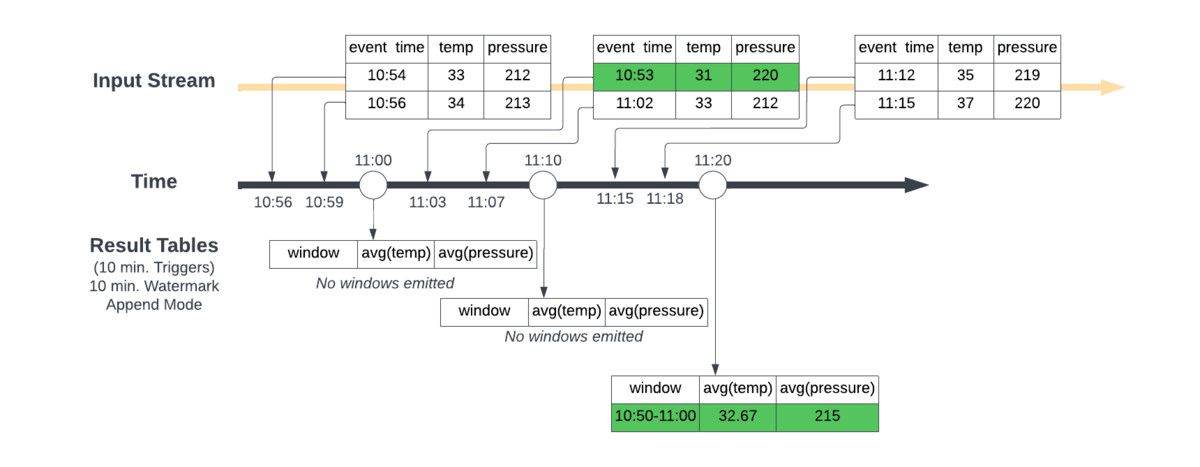
Vamos a tomar un escenario en el que recibimos datos en varios momentos, aproximadamente entre las 10:50 AM y las 11:20 AM. Estamos creando ventanas deslizantes de 10 minutos que calculan el promedio de las lecturas de temperatura y presión que llegaron durante el periodo de ventana.
En esta primera imagen, tenemos fixed window a las 11:00 AM, 11:10 AM y 11:20 AM, lo que lleva a las tablas de resultados que se muestran en los horarios respectivos. Cuando el segundo lote de datos llega alrededor de las 11:10 AM con datos que tienen una hora de evento de 10:53 AM, esto se incorpora a los promedios de temperatura y presión calculados para la ventana de 11:00 AM → 11:10 AM que se cierra a las 11:10 AM, lo que no da el resultado correcto.
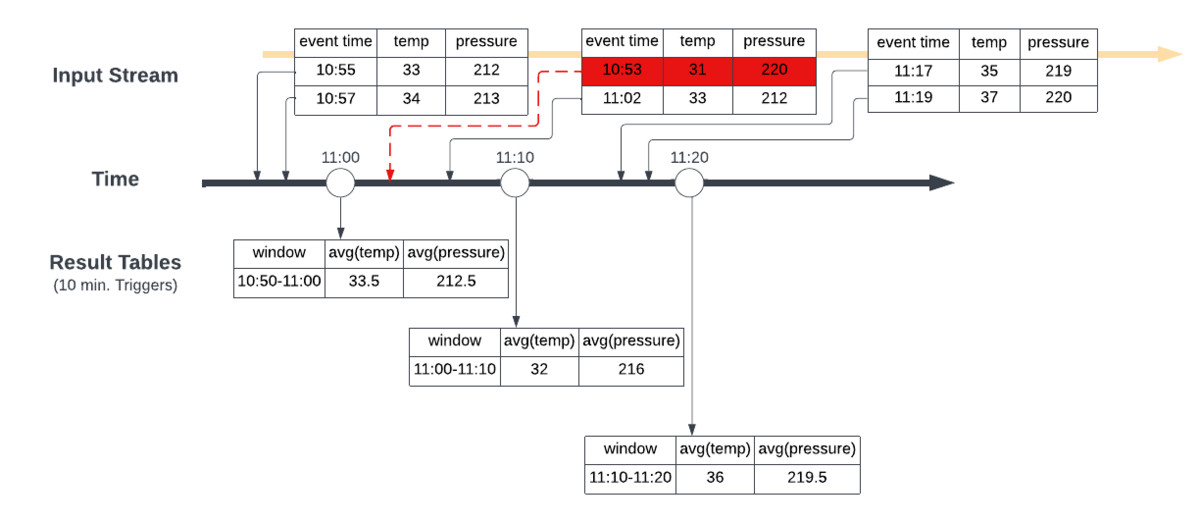
Para asegurarnos obtener los resultados correctos para los agregados que queremos producir, debemos definir un watermarking(marca de agua) que le permitirá a Spark saber cuándo cerrar la ventana de agregados y producir el resultado agregado correcto.
En las aplicaciones de Structured Streaming, en el sentido más básico, al definir un watermarking, Spark Structured Streaming sabe cuándo ha ingerido todos los datos hasta cierto tiempo, T, (según una expectativa de retraso establecida) para que pueda cerrar y producir agregados en ventanas hasta la marca de tiempo T.
Esta segunda imagen muestra el efecto de implementar un watermarking de 10 minutos, un triggers de 10 minutos y usar el append mode en Spark Structured Streaming.
A diferencia del primer escenario, Spark ahora espera para cerrar y generar windowed aggregation una vez que el tiempo máximo del evento visto menos el watermarking especificado sea mayor que el límite superior de la ventana.
En otras palabras, Spark necesitaba esperar hasta ver puntos de datos en los que la última hora del evento vista menos 10 minutos fuera mayor que las 11:00 AM para emitir la ventana agregada de 10:50 AM → 11:00 AM A las 11:00 AM, no ve esto, por lo que solo inicializa el cálculo agregado en el almacén de estado interno de Spark. A las 11:10 AM, esta condición aún no se cumple, pero tenemos un nuevo punto de datos para las 10:53 AM, por lo que el estado interno se actualiza, pero no se emite. Luego, finalmente, a las 11:20 AM, Spark vio un punto de datos con una hora de evento de 11:15 AM y desde las 11:15 AM menos 10 minutos son las 11:05 AM, que es más tarde del 11:00 AM del windowing 10:50 AM → 11:00 AM, por tanto se puede emitir una ventana de las 11:00 AM a la tabla de resultados.
Esto produce el resultado correcto al incorporar adecuadamente los datos en función del retraso esperado definido por la marca de agua. Una vez que se emiten los resultados, el estado correspondiente se elimina del almacén de estados.
9.2 Escenario 2. Word Count¶
Vamos a tomar como escenario 2, usaremos de nuevo como ejemplo la aplicación word count.
Por ejemplo, la aplicación podría recibir una palabra generada a las 12:04 (es decir, la hora del evento) a las 12:11. La aplicación debe usar la hora 12:04 en lugar de 12:11 para actualizar los recuentos anteriores para la ventana de 12:00 a 12:10. Esto ocurre naturalmente en nuestra window-based grouping: Structured Streaming puede mantener el estado intermedio para agregados parciales durante un largo período de tiempo, de modo que los datos tardíos puedan actualizar correctamente los agregados de ventanas antiguas, como se ilustra a continuación.
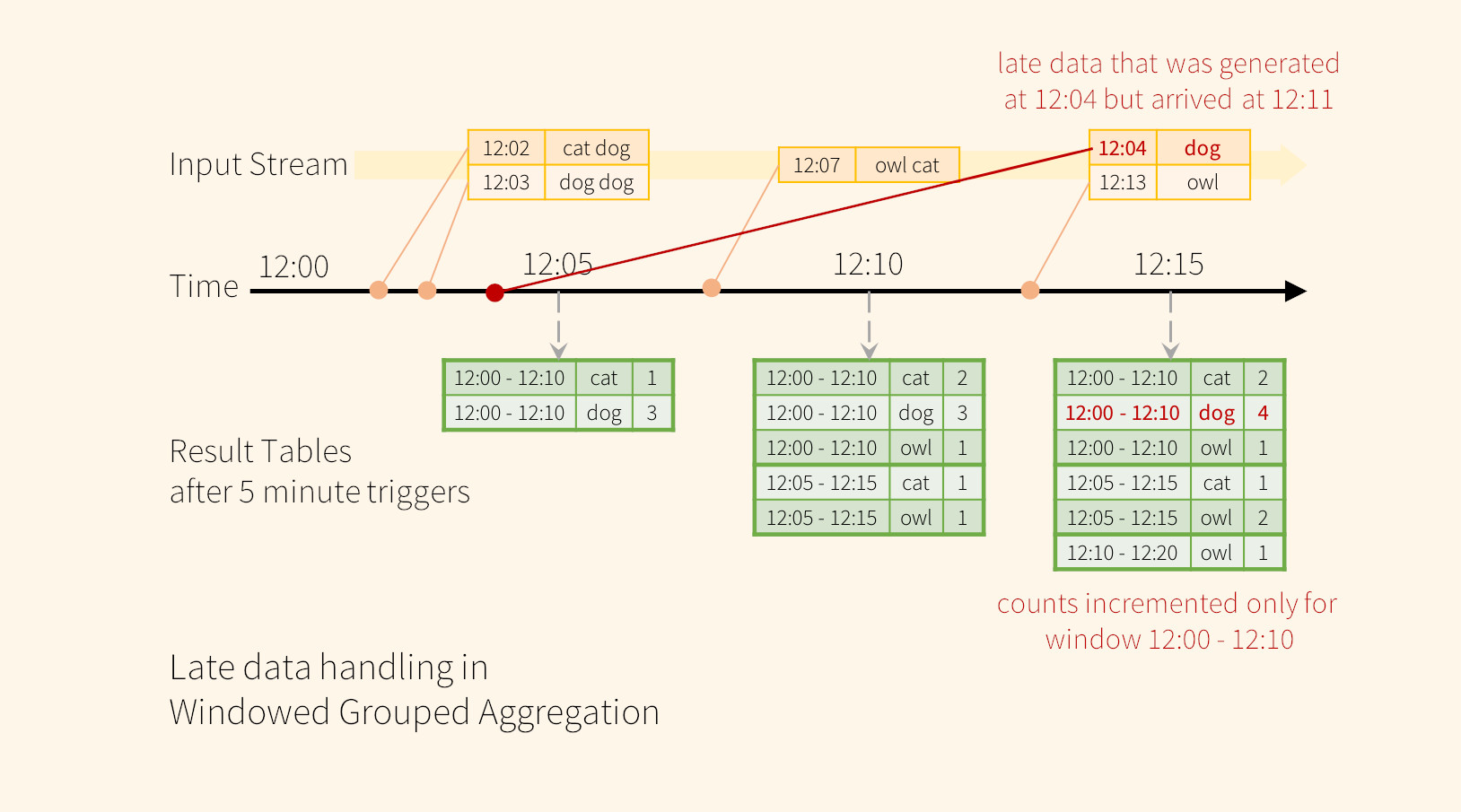
Sin embargo, como ya hemos visto, para ejecutar esta consulta durante días, es necesario que el sistema limite la cantidad de estado intermedio en memoria que acumula. Esto significa que el sistema necesita saber cuándo se puede eliminar un agregado antiguo del estado en memoria porque la aplicación ya no recibirá datos tardíos para ese agregado. Watermarking permite que el motor rastree automáticamente la hora del evento actual en los datos e intente limpiar el estado anterior en consecuencia. Vamos a usar el ejemplo para entenderlo
Podemos definir fácilmente las marcas de agua en el ejemplo anterior usando withWatermark() como se muestra a continuación.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()
Update Mode¶
En este ejemplo, definimos la watermark de la consulta en el valor de la columna "timestamp" y también definimos "10 minutos" como el umbral de qué tan tarde se permite que lleguen los datos. Si esta consulta se ejecuta en el update mode de salida el motor seguirá actualizando los recuentos de una window en la tabla de resultados hasta que la ventana sea más antigua que la watermark, que va por detrás del tiempo del evento actual en la columna " timestamp” por 10 minutos.
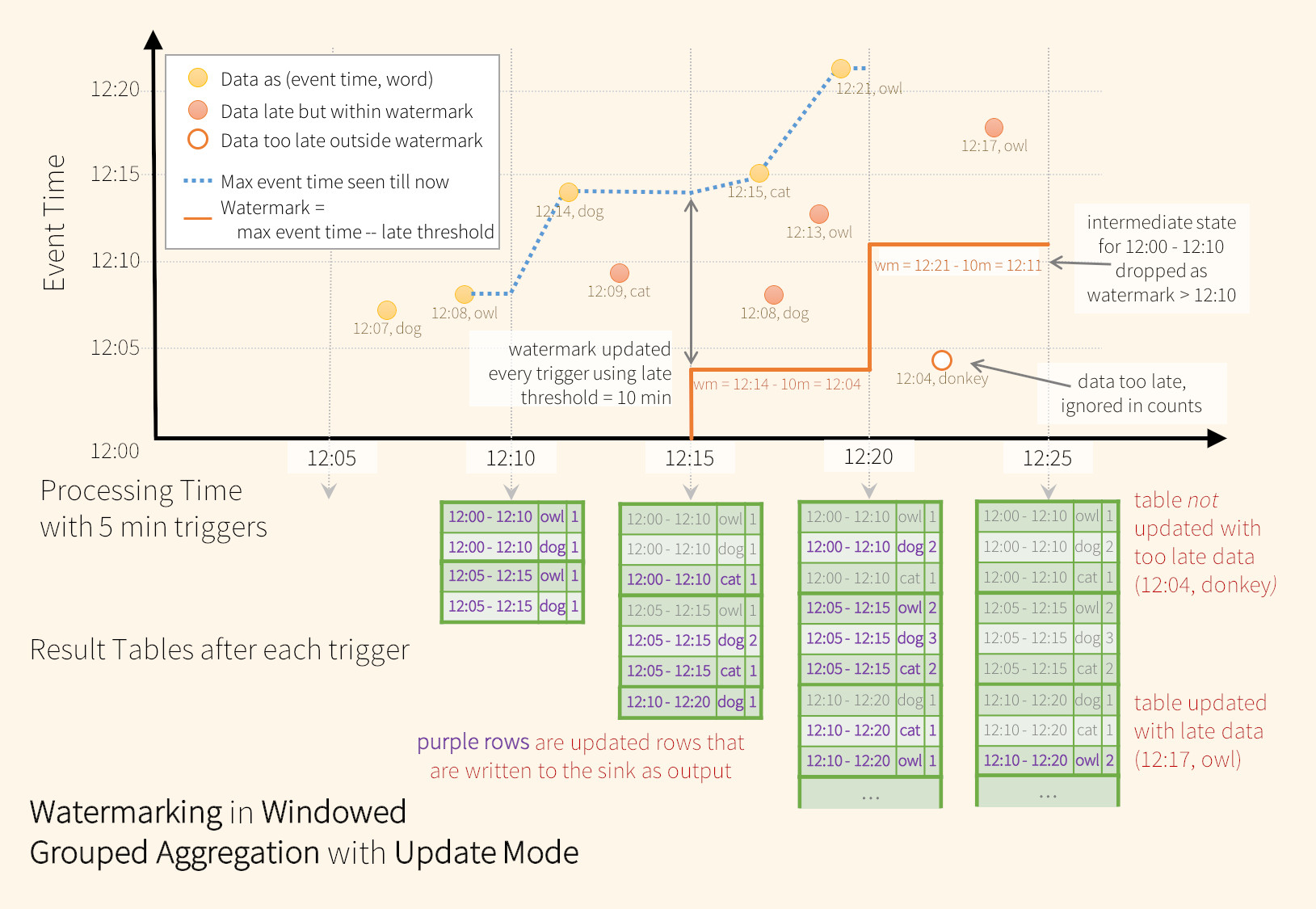
Como se muestra en la figura, el tiempo máximo del evento rastreado por el motor es la línea discontinua azul y la watermark establecida (max event time - '10 mins) al comienzo de cada trigger es la línea roja.
Append Mode¶
Por ejemplo, cuando el motor observa los datos (12:14, dog), establece la watermark para el siguiente trigger en 12:04. Esta marca de agua permite que el motor mantenga un estado intermedio durante 10 minutos adicionales para permitir que se cuenten los datos tardíos. Por ejemplo, los datos (12:09, cat) están desordenados y retrasados, y caen en las ventanas 12:00 - 12:10 y 12:05 - 12:15. Dado que todavía está por delante de la marca de agua 12:04 en el trigger, el motor aún mantiene los recuentos intermedios como estado y actualiza correctamente los recuentos de las ventanas relacionadas. Sin embargo, cuando la marca de agua se actualiza a las 12:11, el estado intermedio de la ventana (12:00 - 12:10) se borra y todos los datos posteriores (por ejemplo, (12:04, donkey)) se consideran "demasiado tarde (too late)" y por lo tanto ignorado. Tengamos en cuenta que después de cada trigger, los recuentos actualizados (es decir, filas moradas) se escriben para el sink de salida configurado, según lo dicta el update mode.
Es posible que algunos receptores(sink) (por ejemplo, files) no admitan las actualizaciones detalladas que requiere el update mode. Para trabajar con ellos, también admitimos append mode, donde solo se escriben los recuentos finales para sink de salida. Lo vemos en la siguiente figura.
Agregaciones append mode
Con Spark no podíamos utilizar el modo append con la agregaciones, ya que Spark necesita saber que los registros no se actualizarán o modificarán en el futuro. En cambio, al definir una marca de agua, ahora sí que podremos hacerlo. Para ello, sólo emitirá el resultado una vez ha finalizado una ventana y no pueda aceptar nuevos eventos tardíos.
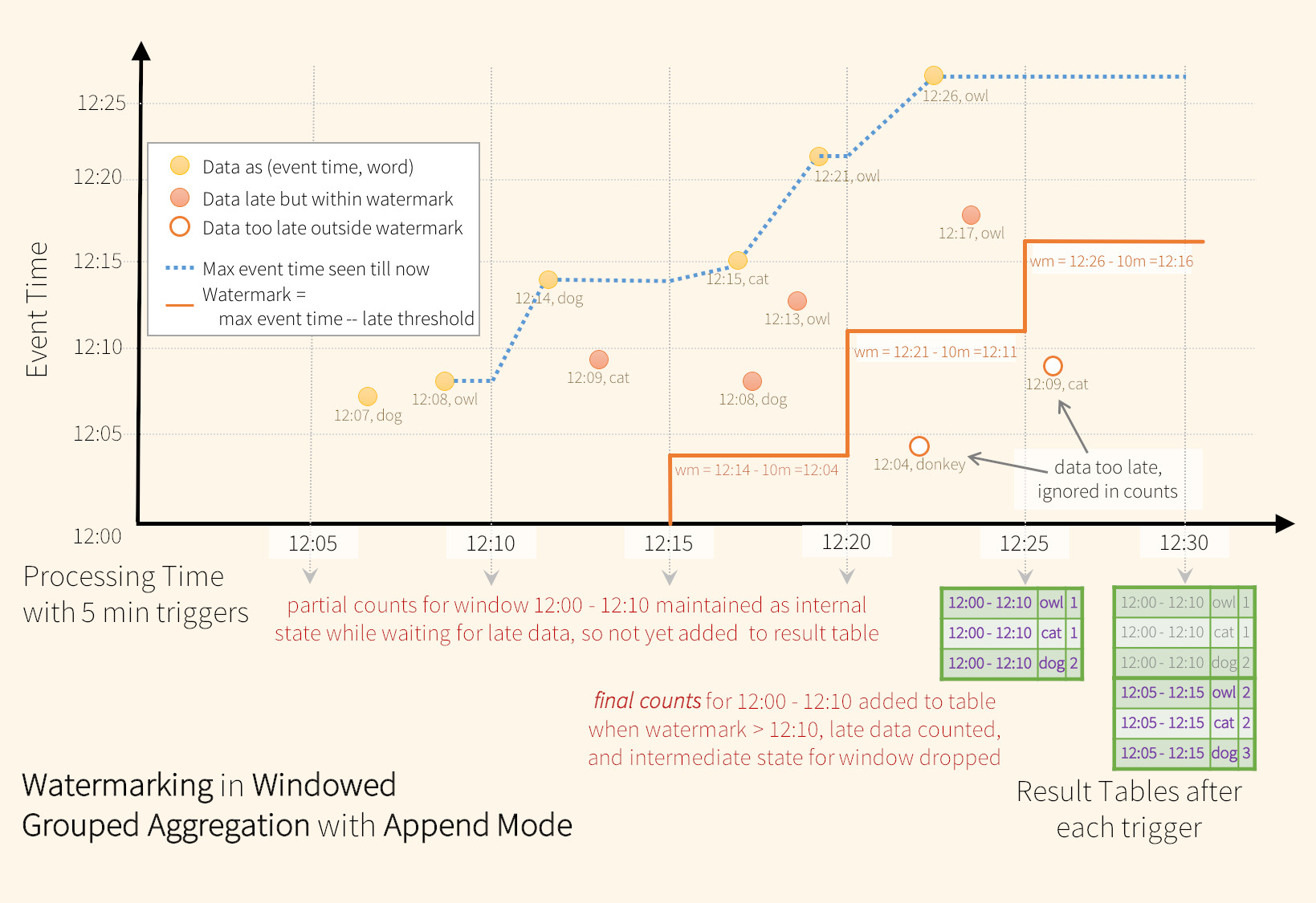
Tengamos en cuenta que el uso de withWatermark en un non-streaming Dataset no es operativo. Como la watermark no debería afectar a ninguna consulta por lotes de ninguna manera, se ignorará directamente.
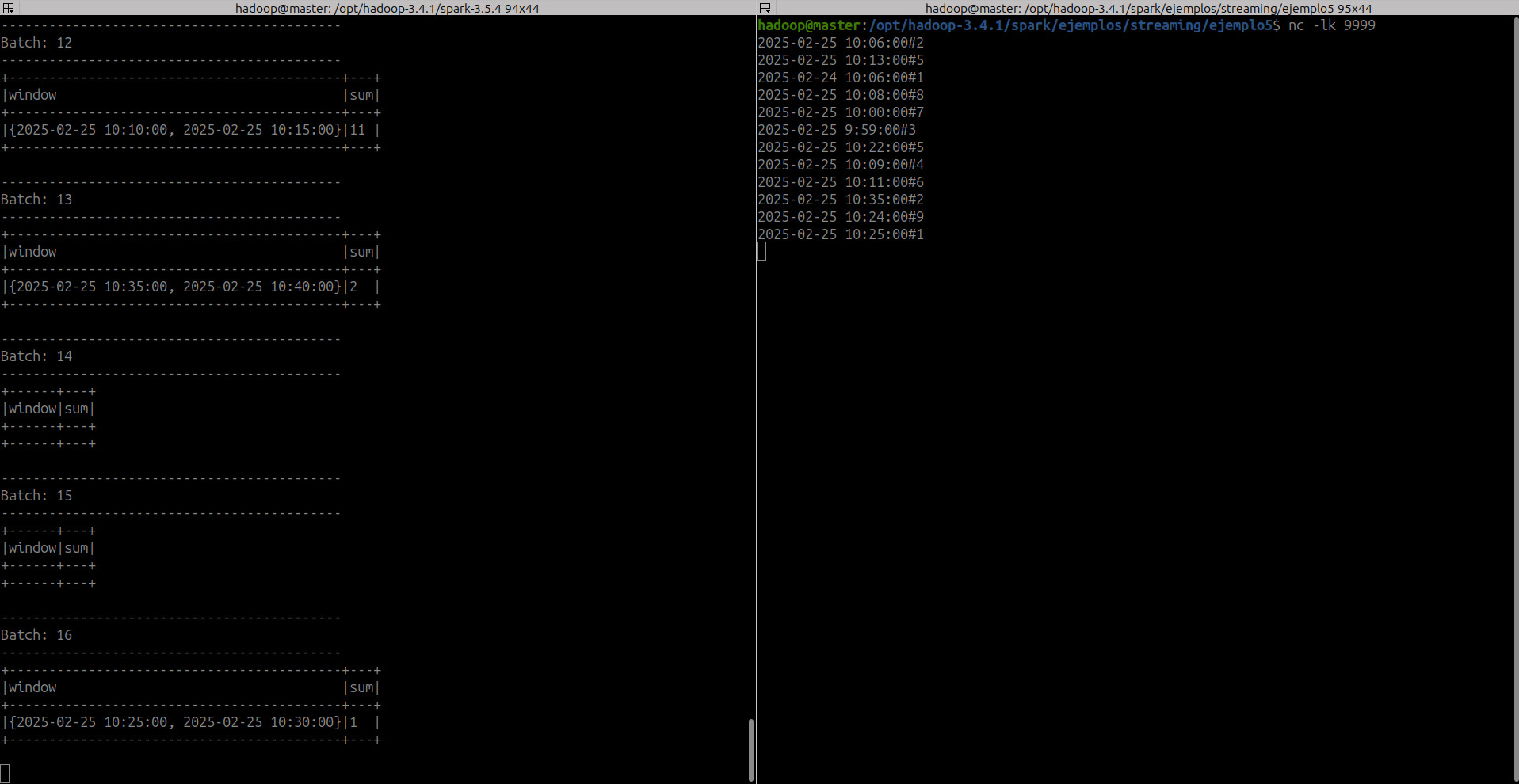
10. Ejemplo 5. Window y Watermark¶
Vamos a realizar un ejercicio para entender el funcionamiento de watermark
Para ello usaremos el siguiente código, donde leemos a través de un socket en el puerto 9999 un registro que contiene un event_time(timestamp) con una # y un número que nos servirá de sumatorio para ir controlando a que ventana se procesan los datos. El registro tendrá el siguiente contenido 2025-02-25 10:06:00#2
- Código de la aplicación
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("Ejemplo5_watermark") \
.getOrCreate()
df_init = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Set Spark logging level to ERROR to avoid various other logs on console.
spark.sparkContext.setLogLevel("ERROR")
df_event = df_init.select(split(col("value"), "#").alias("data")) \
.withColumn("event_timestamp", element_at(col("data"), 1).cast("timestamp")) \
.withColumn("val", element_at(col("data"), 2).cast("integer")) \
.drop("data")
df_result = df_event \
.withWatermark("event_timestamp", "10 minutes") \
.groupBy(window(col("event_timestamp"), "5 minutes")) \
.agg(sum("val").alias("sum"))
query = df_result \
.writeStream \
.outputMode("update") \
.option('truncate', 'false')\
.format("console") \
.start()\
.awaitTermination()
- Ejecutamos el comando NetCat en el puerto 9999 que es donde nuestra app estará escuchando
- Ejecutamos nuestra app de Spark Streaming
spark-submit --master spark://192.168.11.10:7077 /opt/hadoop-3.4.1/spark/ejemplos/streaming/ejemplo5/ejemplo5_watermark.py
- Primer registro:
2025-02-25 10:06:00#2. El registro se procesa dentro de suwindowcorrespondiente de 5 minutos
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+---+
|window |sum|
+------------------------------------------+---+
|{2025-02-25 10:05:00, 2025-02-25 10:10:00}|2 |
+------------------------------------------+---+
- Segundo registro:
2025-02-25 10:13:00#5.- Hasta ahora sólo hemos procesado un registro, lo que significa
max event time = 2025-02-25 10:06:00(es decir, el último timestamp más reciente, recuerda el punto 2). Por lo tanto, la marca de aguamax event time - delayThreshold = 2025-02-25 09:56:00. Para una ventana de tamaño 5 minutos, la ventana de la marca de agua será{09:55:00, 10:00:00}. - Por tanto, cualquier dato anterior al inicio de la ventana de la marca de agua
{09:55:00, 10:00:00}serían descartados. - Sin embargo, el tiempo del evento
{2025-02-25 10:13:00}para el segundo registro es mayor que la hora de inicio de la ventana de la marca de agua, por lo que se procesará.
- Hasta ahora sólo hemos procesado un registro, lo que significa
-------------------------------------------
Batch: 3
-------------------------------------------
+------------------------------------------+---+
|window |sum|
+------------------------------------------+---+
|{2025-02-25 10:10:00, 2025-02-25 10:15:00}|5 |
+------------------------------------------+---+
- Tercer registro:
2025-02-24 10:06:00#1. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:13:00} - watermark:
{2025-02-25 10:03:00} - window watermark:
{2025-02-25 10:00:00, 2025-02-25 10:05:00} - El tiempo es menor que el inicio de la ventana de la marca de agua, por lo tanto, se tratará como datos tardíos y se descartará. Obtendremos un minibatch vacío.
- Tiempo máximo del evento:
-------------------------------------------
Batch: 5
-------------------------------------------
+------+---+
|window|sum|
+------+---+
+------+---+
- Cuarto registro:
2025-02-25 10:08:00#8. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:13:00} - watermark:
{2025-02-25 10:03:00} - window watermark:
{2025-02-25 10:00:00, 2025-02-25 10:05:00} - Este tiempo de eventos es mayor que el inicio de la ventana de la marca de agua, por lo tanto, se procesará (con su suma correspondiente del valor del
group byde la ventana).
- Tiempo máximo del evento:
-------------------------------------------
Batch: 6
-------------------------------------------
+------------------------------------------+---+
|window |sum|
+------------------------------------------+---+
|{2025-02-25 10:05:00, 2025-02-25 10:10:00}|10 |
+------------------------------------------+---+
- Quinto registro:
2025-02-25 10:00:00#7. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:13:00} - watermark:
{2025-02-25 10:03:00} - window watermark:
{2025-02-25 10:00:00, 2025-02-25 10:05:00} - Este tiempo de evento es igual que el inicio de la ventana de la marca de agua, por lo tanto, se procesará.
- Tiempo máximo del evento:
-------------------------------------------
Batch: 7
-------------------------------------------
+------------------------------------------+---+
|window |sum|
+------------------------------------------+---+
|{2025-02-25 10:00:00, 2025-02-25 10:05:00}|7 |
+------------------------------------------+---+
- Sexto registro:
2025-02-25 9:59:00#3. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:13:00} - watermark:
{2025-02-25 10:03:00} - window watermark:
{2025-02-25 10:00:00, 2025-02-25 10:05:00} - Este tiempo de evento es menor que el inicio de la ventana de la marca de agua, por lo tanto, no se procesará.
- Tiempo máximo del evento:
-------------------------------------------
Batch: 8
-------------------------------------------
+------+---+
|window|sum|
+------+---+
+------+---+
- Séptimo registro:
2025-02-25 10:22:00#5. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:13:00} - watermark:
{2025-02-25 10:03:00} - window watermark:
{2025-02-25 10:00:00, 2025-02-25 10:05:00} - Este tiempo de eventos es mayor que el inicio de la ventana de la marca de agua, por lo tanto, se procesará
- Tiempo máximo del evento:
-------------------------------------------
Batch: 9
-------------------------------------------
+------------------------------------------+---+
|window |sum|
+------------------------------------------+---+
|{2025-02-25 10:20:00, 2025-02-25 10:25:00}|5 |
+------------------------------------------+---+
- Octavo registro:
2025-02-25 10:09:00#4. El estado actual del sistema es:- Tiempo máximo del evento:
{2025-02-25 10:22:00} - watermark:
{2025-02-25 10:12:00} - window watermark:
{2025-02-25 10:10:00, 2025-02-25 10:15:00} - Este tiempo de evento es menor que el inicio de la ventana de la marca de agua, por lo tanto, no se procesará.
- Tiempo máximo del evento:
-------------------------------------------
Batch: 11
-------------------------------------------
+------+---+
|window|sum|
+------+---+
+------+---+
- Y así sucesivamente con otros eventos
Dada la propia idiosincrasia de Spark streaming, se generan algunos microbatch vacíos sin introducción de registros