UD 7 - Apache Kafka Connect¶
Kafka Connect es un componente de Apache Kafka® que se utiliza para realizar la integración de transmisión(streaming integration) entre Kafka y otros sistemas, como bases de datos, servicios en la nube, índices de búsqueda, sistemas de archivos y almacenes de valores-clave.
Kafka Connect facilita la transmisión de datos desde numerosas fuentes a Kafka y la transmisión de datos desde Kafka a numerosos destinos. La siguiente figura enseña una pequeña muestra de estas fuentes (sources) y sumideros (sinks) objetivo. Hay literalmente cientos de conectores diferentes disponibles para Kafka Connect. Algunos de los más populares incluyen:
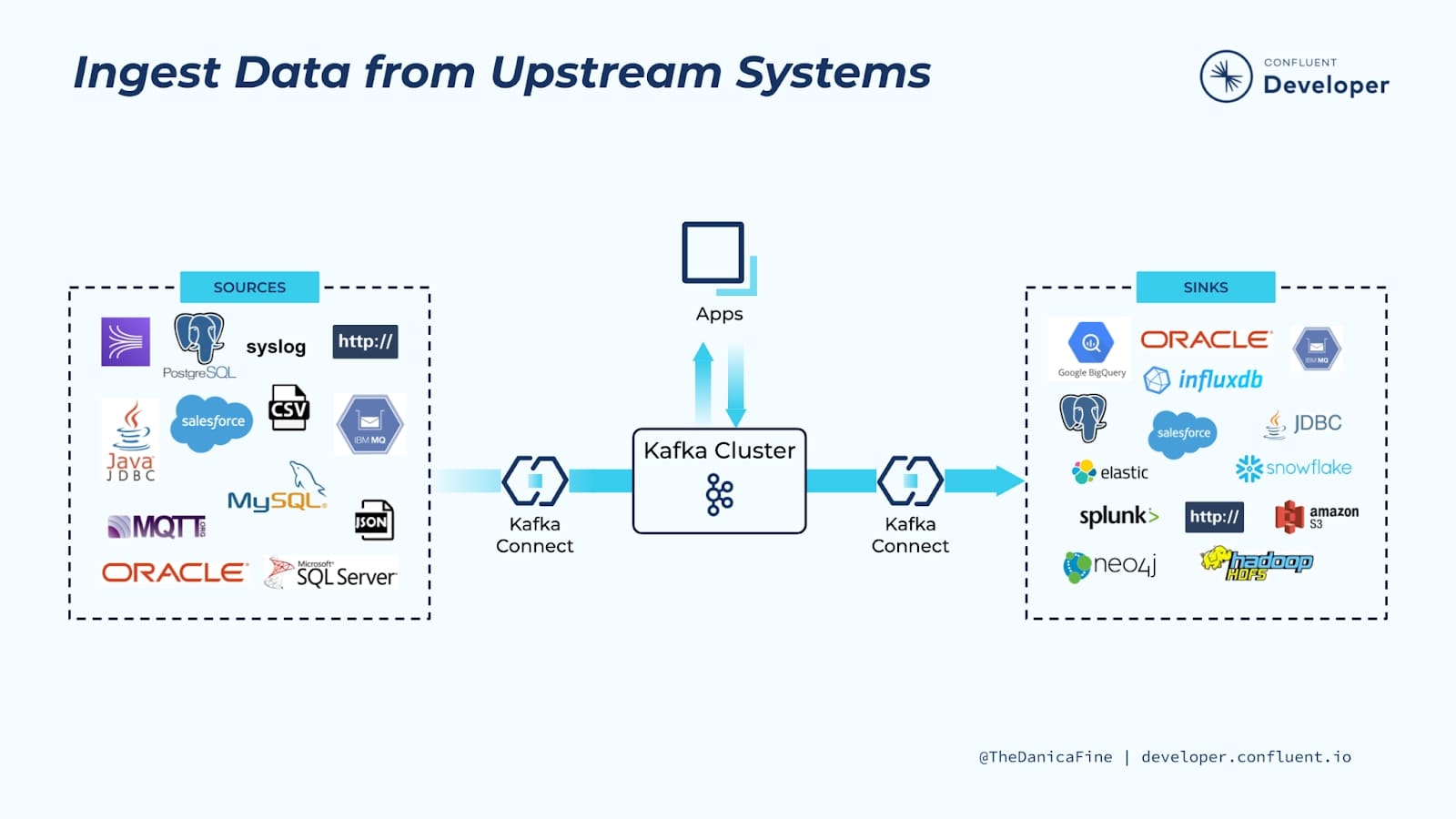
- RDBMS (Oracle, SQL Server, Db2, Postgres, MySQL)
- Cloud object stores (Amazon S3, Azure Blob Storage, Google Cloud Storage)
- Message queues (ActiveMQ, IBM MQ, RabbitMQ)
- NoSQL and document stores (Elasticsearch, MongoDB, Cassandra)
- Cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift)
1. Cómo funciona Kafka Connect¶
Kafka Connect se ejecuta en su propio proceso, independiente de los brokers y controllers de un cluster Kafka. Es distribuido, escalable y tolerante a fallos.
Pero la mejor parte de Kafka Connect es que su uso no requiere programación. Está completamente basado en configuración, lo que lo pone a disposición de una amplia gama de usuarios, no solo de desarrolladores. Además de la ingesta y salida de datos, Kafka Connect también puede realizar transformaciones ligeras en los datos a medida que pasan.
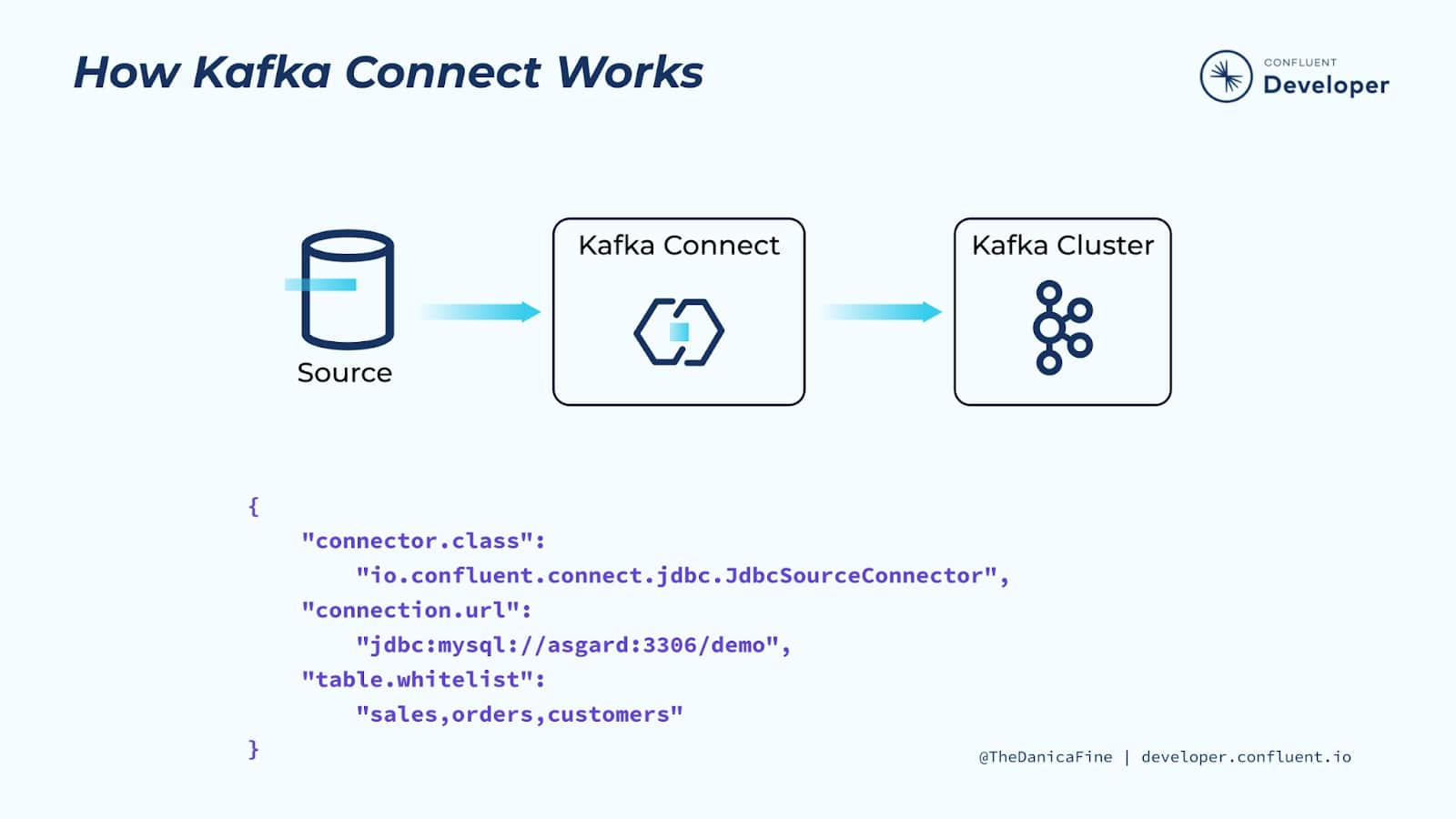
Siempre que desee transmitir datos a Kafka desde otro sistema, o transmitir datos desde Kafka a otro lugar, Kafka Connect debería ser lo primero que nos venga a la mente. Vamos a estudiar algunos de los casos de uso más común donde se utiliza Kafka Connect.
1.1 Streaming Pipelines¶
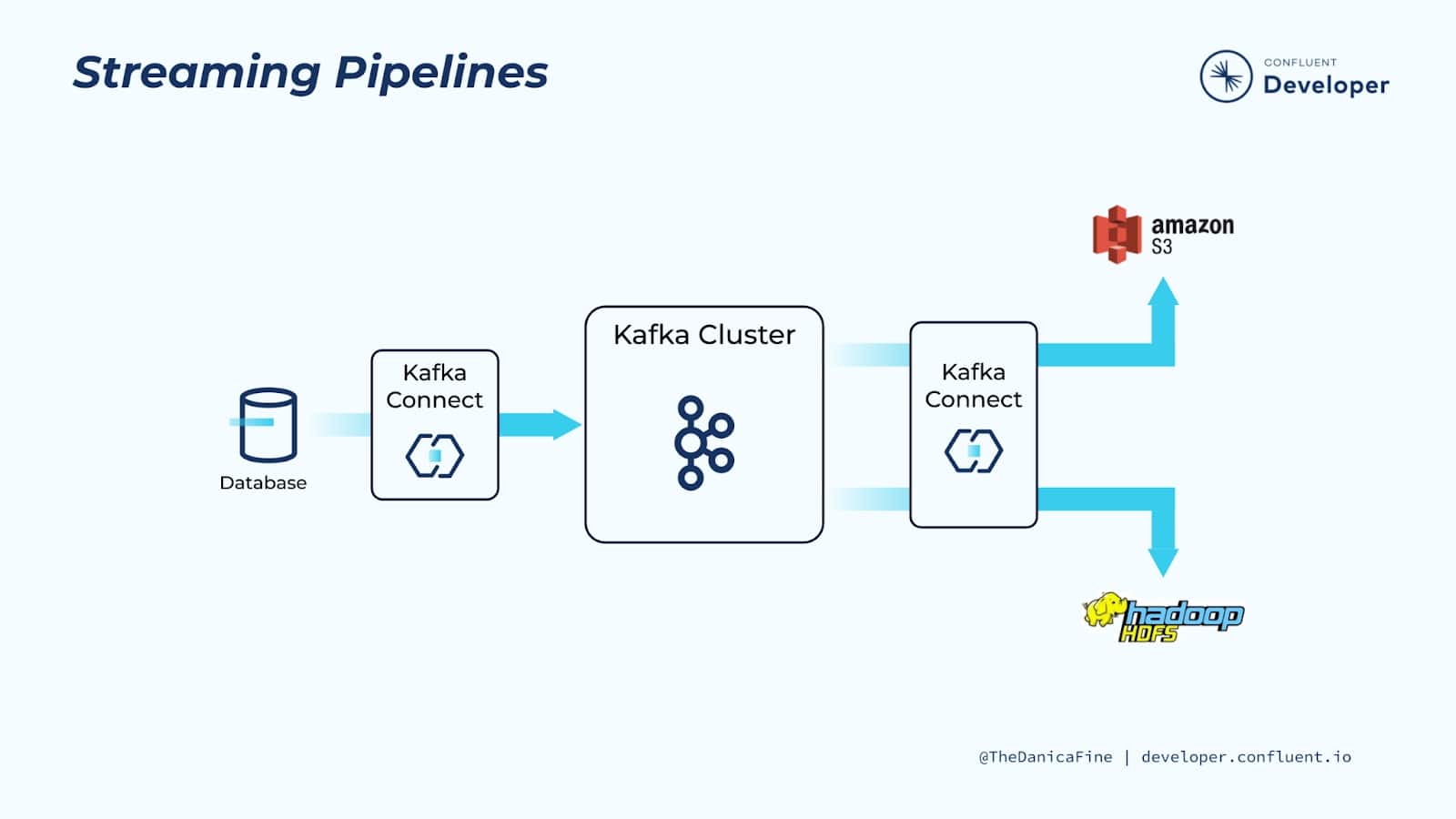
Kafka Connect se puede utilizar para la ingesta de flujos de eventos en tiempo real desde una fuente de datos y transmitirlos a un sistema de destino para su análisis. En este ejemplo particular, nuestra fuente de datos es una base de datos transaccional.
Tenemos un conector Kafka que sondea la base de datos en busca de actualizaciones y traduce la información en eventos en tiempo real que produce en Kafka.
Tener a Kafka entre los sistemas de origen y de destino significa que estamos construyendo un sistema débilmente acoplado. En otras palabras, es relativamente fácil para nosotros cambiar la fuente o el destino sin afectar al otro.
Debido a que Kafka almacena datos hasta un intervalo de tiempo configurable por entidad de datos (topic), es posible transmitir los mismos datos originales a múltiples objetivos posteriores. Esto significa que solo necesita mover datos a Kafka una vez y, al mismo tiempo, permitir que sean consumidos por una serie de tecnologías posteriores diferentes para una variedad de requisitos comerciales o incluso para que los mismos datos estén disponibles para diferentes áreas de un negocio.
1.2 Escribir en Datastore desde Kafka¶
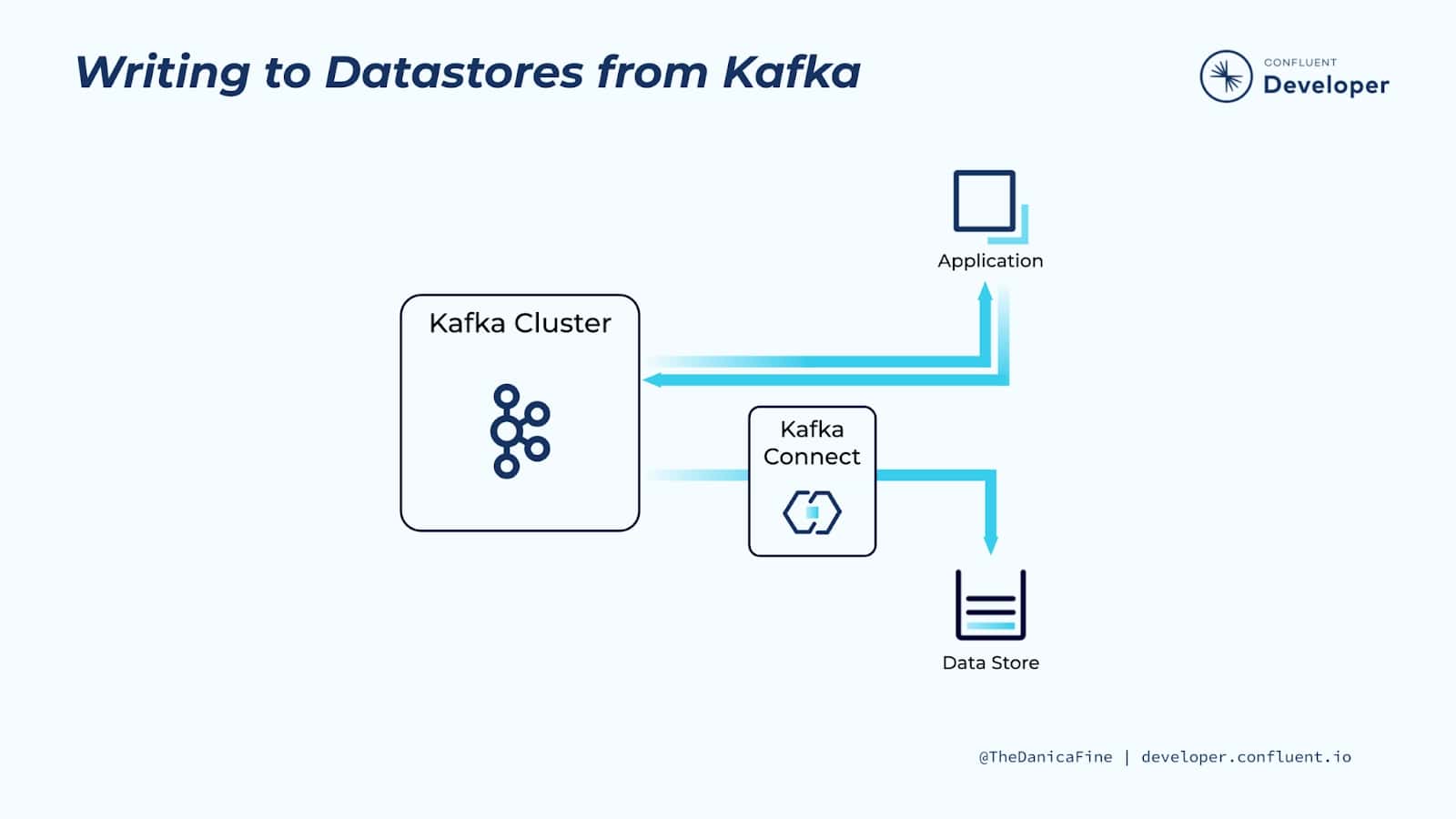
Como otro caso de uso, es posible que queramos escribir datos creados por una aplicación en un sistema de destino. Por supuesto, estos podrían ser varios casos de uso de aplicaciones diferentes, pero supongamos que tenemos una aplicación que produce una serie de eventos de registro y nos gustaría que esos eventos también se escriban en un almacén de documentos o persistan en una base de datos relacional.
En lugar de desarrollar la lógica necesaria a esta aplicación determinada y su mantenimiento, con el coste que ello conlleva, podemos producir los datos directamente en Kafka y permitir que Kafka Connect se encargue del resto. Como vimos en el último ejemplo, al mover los datos a Kafka, somos libres de configurar conectores Kafka para mover los datos a cualquier almacén de datos posterior que necesitemos, y está completamente desacoplado de la aplicación misma.
1.3 Evolucionar el procesamiento de sistemas antiguos a nuevos¶
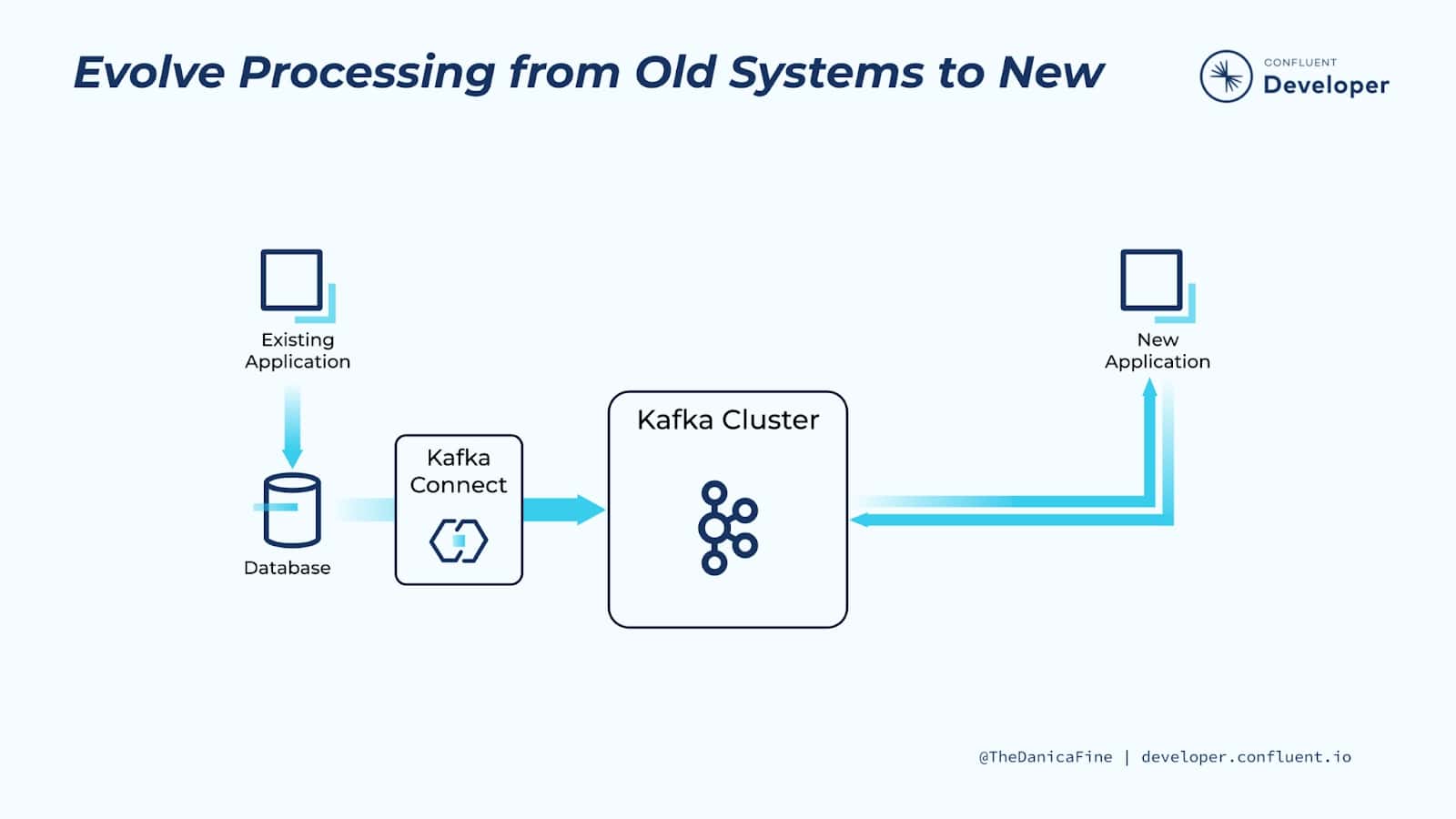
Antes de la llegada de tecnologías más recientes (como tiendas NoSQL, plataformas de transmisión de eventos y microservicios), las bases de datos relacionales (RDBMS) eran el lugar de facto en el que se escribían todos los datos de las aplicaciones.
Podemos usar Ingesta de datos desde Bases de Datos hacia Kafka con Kafka Connect usando Change Data Capture (CDC), el cual nos permite extraer cada INSERCIÓN, ACTUALIZACIÓN e incluso ELIMINACIÓN de una base de datos en un flujo de eventos en Kafka. Y podemos hacer esto casi en tiempo real
1.4 Sistemas en tiempo real¶
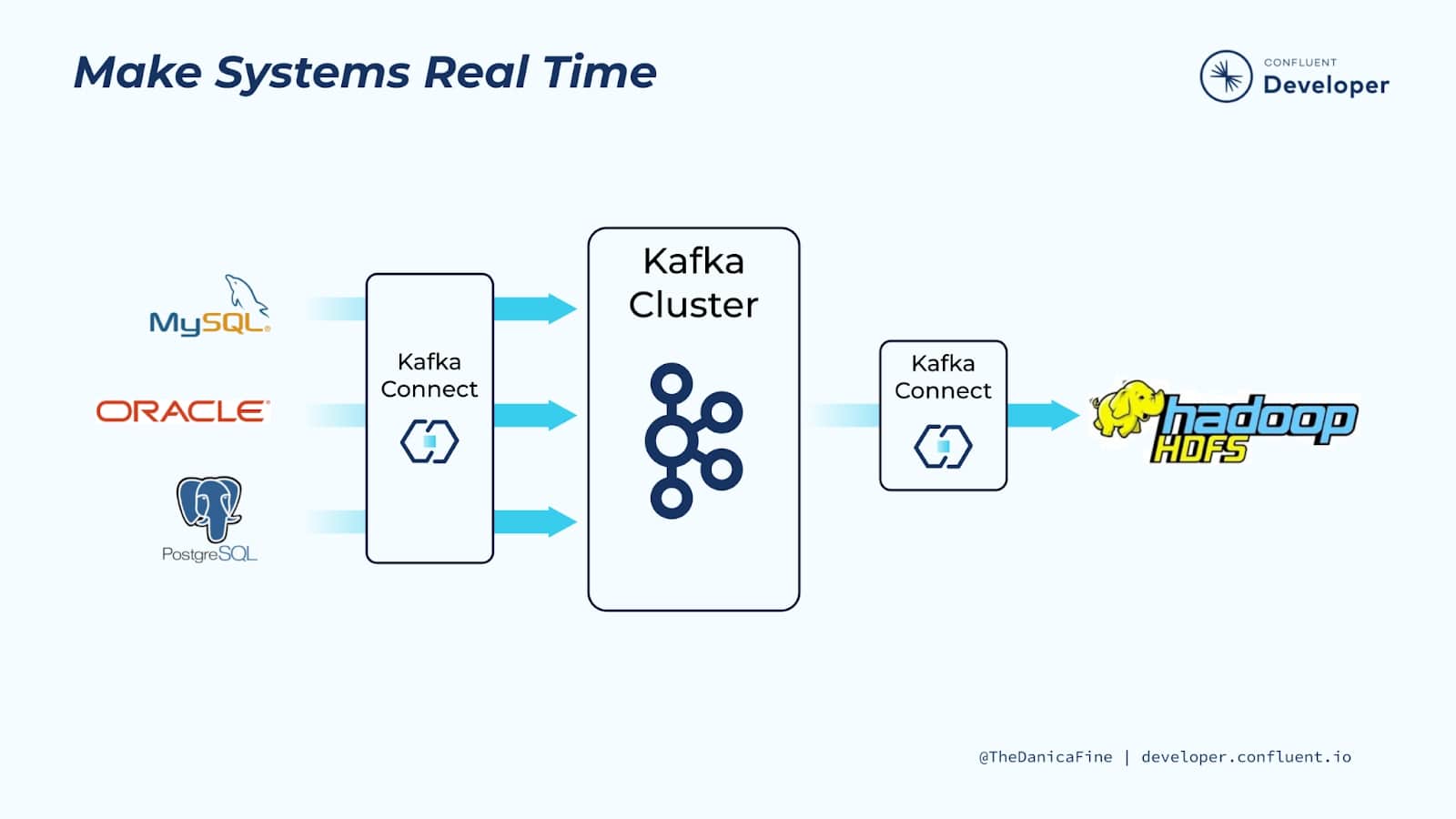
Hacer que los sistemas estén en tiempo real es increíblemente valioso porque muchas organizaciones tienen datos en reposo en bases de datos y seguirán haciéndolo.
Pero el valor real de los datos radica en nuestra capacidad de acceder a ellos lo más cerca posible del momento en que se generan. Al utilizar Kafka Connect para capturar datos poco después de escribirlos en una base de datos y traducirlos en un flujo de eventos, puede crear mucho más valor. Al hacerlo, se desbloquean los datos para que pueda moverlos a otra parte, por ejemplo, agregándolos a un índice de búsqueda o a un grupo de análisis. Alternativamente, el flujo de eventos se puede utilizar para activar aplicaciones a medida que cambian los datos en la base de datos, por ejemplo, para recalcular el saldo de una cuenta o hacer una recomendación.
2. Conceptos de Kafka Connect¶
En esta sección describiremos los siguientes conceptos de Kafka Connect:
- Connectors: la abstracción de alto nivel que coordina la transmisión de datos mediante la gestión de tareas.
- Tasks: La implementación de cómo se copian los datos hacia o desde Kafka.
- Workers: los procesos en ejecución que ejecutan conectores y tareas.
- Converters: el código utilizado para traducir datos entre Connect y el sistema que envía o recibe datos.
- Transforms: Lógica simple para alterar cada mensaje producido o enviado a un conector.
- Dead Letter Queue (Cola de mensajes fallidos): cómo Connect maneja los errores del conector
2.1 Connectors¶
Kafka Connect incluye dos tipos de conectores:
-
Source connector: Source connectors ingestan bases de datos completas y transmiten actualizaciones de tablas a topics de Kafka. También pueden recopilar métricas de todos sus servidores de aplicaciones y almacenar los datos en topics de Kafka, lo que hace que los datos estén disponibles para el procesamiento de transmisiones con baja latencia.
-
Sink connector: Sink connectors entregan datos de topics de Kafka a índices secundarios, como Elasticsearch, o sistemas por lotes como Hadoop para análisis offline.
2.2 Tasks¶
Las tareas son el actor principal en el modelo de datos de Connect. Cada instancia de conector coordina un conjunto de tareas que copian datos. Al permitir que el conector divida un único trabajo en muchas tareas, Kafka Connect proporciona soporte integrado para paralelismo y copia de datos escalable con una configuración mínima. Las tareas se pueden iniciar, detener o reiniciar en cualquier momento para proporcionar una canalización de datos resistente y escalable.

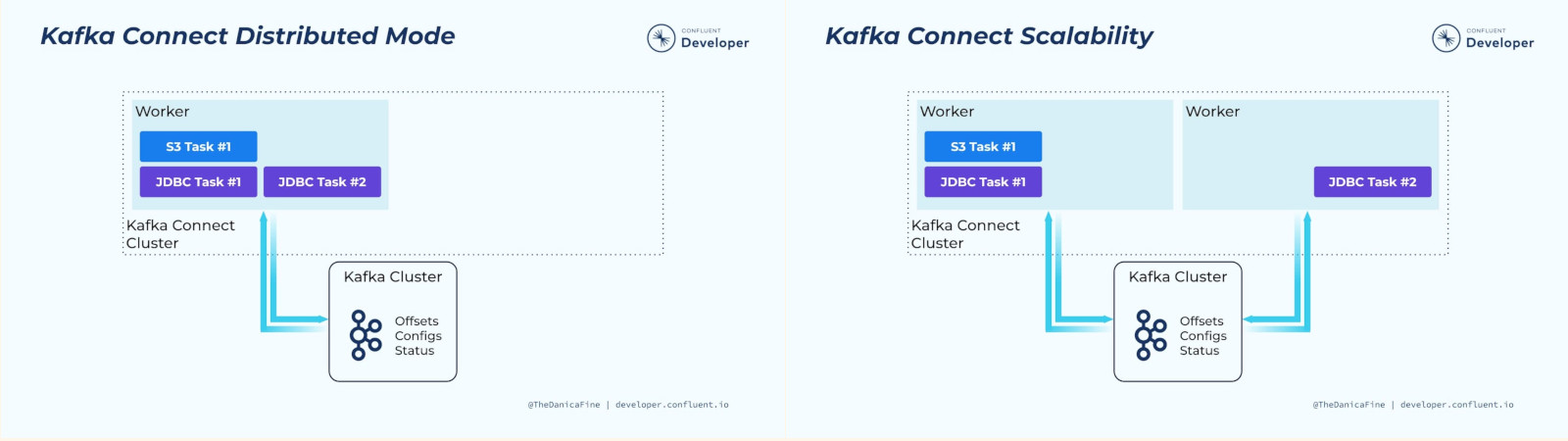
Task rebalancing¶
Cuando un conector se envía por primera vez al clúster, los workers reequilibran el conjunto completo de conectores en el clúster y sus tareas para que cada worker tenga aproximadamente la misma cantidad de trabajo. Este procedimiento de reequilibrio también se utiliza cuando los conectores aumentan o disminuyen la cantidad de tareas que requieren, o cuando se cambia la configuración de un conector. Cuando un worker falla, las tareas se reequilibran entre los workers activos. Cuando una tarea falla, no se activa ningún reequilibrio, ya que la falla de una tarea se considera un caso excepcional.

2.3 Workers¶
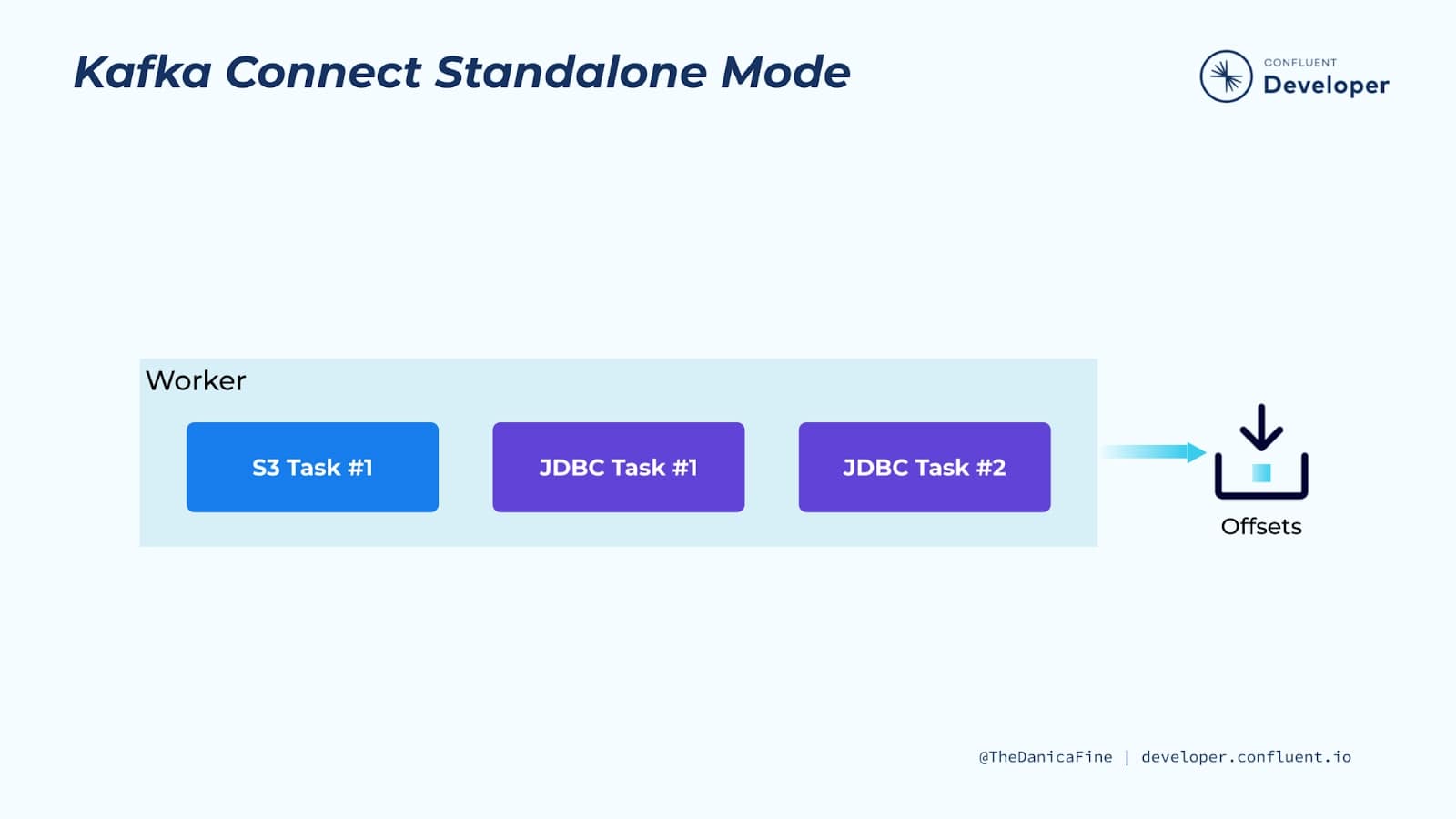
Connectors y tasks son unidades lógicas de trabajo y deben programarse para ejecutarse en un proceso. Kafka Connect llama a estos procesos workers y tiene dos tipos de workers: standalone (independientes) y distributed (distribuidos).
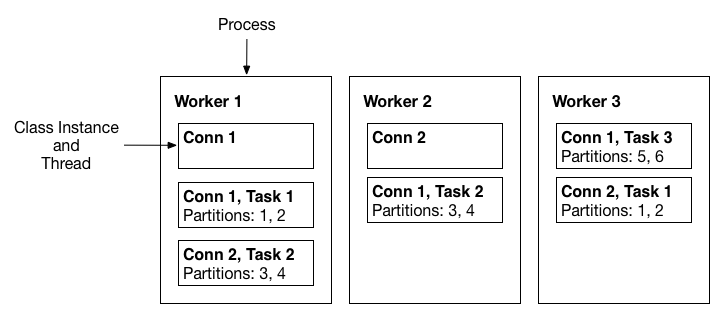
- Standalone workers: Standalone workers es el modo más simple, donde un único proceso es responsable de ejecutar todos los conectores y tareas. Dado que es un proceso único, requiere una configuración mínima. Standalone workers es conveniente para comenzar, durante el desarrollo y en determinadas situaciones en las que solo un proceso tiene sentido, como la recopilación de registros de un host. Sin embargo, debido a que solo hay un proceso, también tiene una funcionalidad más limitada: la escalabilidad se limita al proceso único y no hay tolerancia a fallos más allá de cualquier monitoreo que agregue al proceso único.
- Distributed workers
Distributed workers proporciona escalabilidad y tolerancia automática a fallos para Kafka Connect. En el modo distribuido, inicia muchos procesos de trabajo utilizando el mismo
group.idy se coordinan para programar la ejecución de conectores y tareas entre todos los workers disponibles. Si agrega un worker, lo cierra o un worker falla inesperadamente, el resto de los workers lo reconocen y se coordinan para redistribuir conectores y tareas entre el conjunto actualizado de workers disponibles. Tenga en cuenta la similitud con el reequilibrio del grupo de consumidores. Internamente, los workers conectados utilizan grupos de consumidores para coordinarse y reequilibrarse.
Hay que tener en cuenta que todos los workers con el mismo group.id estarán en el mismo connect cluster. Por ejemplo, si el worker A tiene group.id=connect-cluster-a y el worker B tiene el mismo group.id, el worker A y el worker B formarán un clúster llamado connect-cluster-a.
2.4 Converters¶
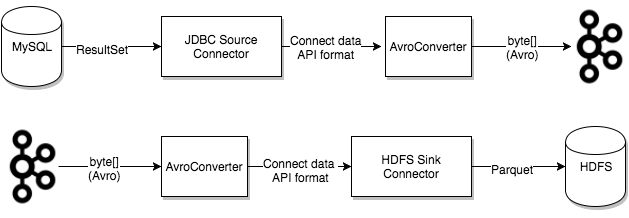
Converters deben tener una implementación de Kafka Connect que admita un formato de datos particular al escribir o leer desde Kafka. Las tareas utilizan convertidores para cambiar el formato de los datos de bytes a un formato de datos interno de Connect y viceversa.
Converters están desacoplados de los propios conectores para permitir la reutilización de convertidores entre conectores. Por ejemplo (Observa la imagen), utilizando el mismo convertidor Avro, el conector de origen JDBC puede escribir datos de Avro en Kafka y el conector de receptor HDFS puede leer datos de Avro desde Kafka. Esto significa que se puede utilizar el mismo convertidor aunque, por ejemplo, la fuente JDBC devuelva un ResultSet que finalmente se escribe en HDFS como un archivo parquet.
2.5 Transforms¶
Connectors se pueden configurar con transformaciones para realizar modificaciones simples y ligeras en mensajes individuales. Esto puede resultar conveniente para ajustes menores de datos y enrutamiento de eventos, y muchas transformaciones se pueden encadenar en la configuración del conector. Sin embargo, para transformaciones y operaciones más complejas que se aplican a muchos mensajes se implementan mejor con ksqlDB y Kafka Streams.
Una transformación es una función simple que acepta un registro como entrada y genera un registro modificado. Todas las transformaciones proporcionadas por Kafka Connect realizan modificaciones simples pero comúnmente útiles.
Transforms también se pueden utilizar con sink connectors. Para más información, consulta la página oficial Transformation
2.6 Error Reporting in Connect¶
Kafka Connect proporciona informes de errores para manejar los errores encontrados en varias etapas del procesamiento. De forma predeterminada, cualquier error encontrado durante la conversión o dentro de las transformaciones hará que el conector falle. Cada configuración de conector también puede permitir tolerar dichos errores emitiéndolos, escribiendo opcionalmente cada error y los detalles de la operación fallida y el registro problemático (con varios niveles de detalle) en el registro de la aplicación Connect. Estos mecanismos también capturan errores cuando un conector receptor procesa los mensajes consumidos de sus topics Kafka, y todos los errores se pueden escribir en un topic Kafka "dead letter queue" (DLQ) "cola de mensajes no entregados" configurable.
3. Running Kafka Connect¶
Kafka Connect admite dos modos de ejecución: standalone (single process) and distributed.
-
Standalone mode: En este modo, todo el trabajo se realiza en un único proceso. Esta configuración es más sencilla de configurar y poner en marcha, y puede resultar útil en situaciones en las que sólo tiene sentido un worker (por ejemplo, para recopilar archivos de log), pero no se beneficia de algunas de las características de Kafka Connect, como la tolerancia a fallos. Útil para desarrollar y probar Kafka Connect en una máquina local.
-
Distributed mode: Gestiona el equilibrio automático del trabajo, permite escalar hacia arriba (o hacia abajo) de forma dinámica y ofrece tolerancia a fallos tanto en las tareas activas como en los datos de configuración y de confirmación de offset
Se recomienda para entornos de producción debido a las ventajas de escalabilidad, alta disponibilidad y gestión. Ejecuta los workers de Connect en varias máquinas (nodos), que forman un clúster de Connect. Kafka Connect distribuye los conectores en ejecución por todo su clúster. Puede añadir o eliminar nodos a medida que evolucionen sus necesidades.
3.1 Standalone mode¶
Podemos iniciar Kafka Connect en Standalone mode con el siguiente comando:
bin/connect-standalone.sh config/connect-standalone.properties [connector1.properties connector2.json …]
El primer parámetro worker.properties es la configuración para el worker. Puedes usar la configuración por defecto proporcionada por Kafka en config/connect-standalone.properties. Esta incluye ajustes como los parámetros de conexión de Kafka, el formato de serialización y la frecuencia con la que se comprometen los offset. La configuración de config/connect-standalone.properties debería funcionar bien con un cluster local ejecutándose con la configuración por defecto proporcionada por config/server.properties (Recuerda el rol: process.roles=broker,controller)
Será necesario modificarlo para utilizarlo con una configuración diferente o un despliegue en producción. Todos los workers (tanto autónomos -standalone- como distribuidos -distributed-) requieren algunas configuraciones:
-
bootstrap.servers: Lista de servidores Kafka utilizados para arrancar conexiones a Kafka. -
key.converter: Clase Converter utilizada para convertir entre el formato Kafka Connect y la forma serializada que se escribe en Kafka. Ejemplos de formatos comunes incluyen JSON y Avro. -
value.converter: Clase Converter utilizada para convertir entre el formato de Kafka Connect y el formato serializado que se escribe en Kafka. Ejemplos de formatos comunes incluyen JSON y Avro. -
plugin.path(vacío por defecto) - una lista de rutas que contienen plugins de Connect (conectores, convertidores, transformaciones).
Las opciones de configuración importantes específicas del standalone mode son:
offset.storage.file.filename: Archivo para almacenar los offsets de los conectores de origen.
El segundo parámetro (y sucesivos, si los hubiera) connector1.properties es el archivo de propiedades de configuración del conector. Todos los conectores tienen propiedades de configuración que se cargan con el worker.
3.2 Distributed mode¶
Podemos iniciar Kafka Connect en Distributed mode con el siguiente comando:
bin/connect-distributed.sh config/connect-distributed.properties
bin/connect-distributed.sh worker.properties
El parámetro worker.properties es la configuración para el worker. Puedes usar la configuración por defecto proporcionada por Kafka en config/connect-distributed.properties.
En el modo distribuido, Kafka Connect almacena los offsets, las configuraciones y los estados de las tareas en topics de Kafka. Se recomienda crear manualmente los topics para las offsets, las configuraciones y los estados, con el fin de alcanzar el número deseado de particiones y factores de replica. Si los topics aún no se han creado al iniciar Kafka Connect, se crearán automáticamente con el número de particiones y el factor de replicación predeterminados, que pueden no ser los más adecuados para su uso.
En particular, los siguientes parámetros de configuración, además de los ajustes comunes mencionados anteriormente, son fundamentales para establecer antes de iniciar el clúster:
group.id(por defectoconnect-cluster): Nombre único para el clúster, utilizado para formar el grupo de clústeres de Connect. Debemos tener en cuenta que no debe entrar en conflicto con los ID de los grupos de consumidores.config.storage.topic(por defectoconnect-configs): Topic que se utilizará para almacenar las configuraciones de conectores y tareas. Debemos tener en cuenta que debe ser un topic de partición única, altamente replicado y compactado. Es posible que tengamos que crear manualmente el topic para garantizar la configuración correcta, ya que los topics creados automáticamente pueden tener varias particiones o estar configurados automáticamente para la eliminación en lugar de la compactación.offset.storage.topic(por defectoconnect-offsets): Topic a utilizar para almacenar offsets. Este topic debe tener muchas particiones, estar replicado y configurado para la compactación.status.storage.topic(por defectoconnect-status): Topic a utilizar para almacenar estados. Este topic puede tener múltiples particiones, y debe estar replicado y configurado para la compactación.
Connectors on distributed mode
Hay que tener en cuenta que en el modo distribuido las configuraciones de los conectores no se pasan por la línea de comandos. En su lugar, se utiliza la API REST (que se describe a continuación) para crear, modificar y destruir conectores.
3.3 Configuring Connectors¶
Las configuraciones de conectores son simples asignaciones clave-valor. Tanto en modo standalone como distributed, se incluyen en la carga JSON de la solicitud REST que crea (o modifica) el conector. En modo standalone (como hemos visto anteriormente), también pueden definirse en un archivo de propiedades y pasarse al proceso Connect en la línea de comandos.
La mayoría de las configuraciones dependen del conector, por lo que no se pueden describir aquí. Sin embargo, hay algunas opciones comunes:
name- Nombre único para el conector. Si se intenta registrar de nuevo con el mismo nombre, se producirá un error.connector.class- La clase Java para el conectortasks.max- El número máximo de tareas que deben crearse para este conector. El conector puede crear menos tareas si no puede alcanzar este nivel de paralelismo.key.converter- (opcional) Anula el convertidor de clave predeterminado establecido por el worker.value.converter- (opcional) Sustituye al convertidor de valor predeterminado establecido por el worker.
Los conectores de sink también tienen algunas opciones adicionales para controlar su entrada. Cada conector de sink debe establecer una de las siguientes opciones:
topics- Una lista separada por comas de topics a utilizar como entrada para este conectortopics.regex- Una expresión regular de Java de los topics a utilizar como entrada para este conector
4. Ejemplo 4. QuickStart Kafka Connect¶
Para una primera toma de contacto práctico con Kafka Connect vamos a usar 2 conectores sencillos: uno que importa datos de un archivo (source) a un topic y otro que exporte datos (sink) de un topic a un archivo. Todo ello en standalone mode.
Por supuesto, no debemos olvidar que Kafka Connect debe estar conectado con un cluster de Kafka. Para este ejemplo, usaremos la misma configuración que el ejemplo 1 de quickstart de Kafka, con un único nodo que hace de controller y broker al mismo tiempo. Por tanto usaremos la configuración por defecto.
- Iniciamos el cluster Kafka
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/server.properties
bin/kafka-server-start.sh config/server.properties
- Para ello usaremos un plugin de conexión de ficheros llamado
connect-file-4.0.0.jar. Recuerda que en los ejemplos siempre estamos trabajando desde el directorio de instalación de kafka, en nuestro caso/opt/kafka_2.13-4.0.0. También creamos los directorios necesarios para nuestro ejemplo:
- Por tanto, en primer lugar, nos tenemos que asegurar de añadir
connect-file-4.0.0.jara la propiedadplugin.pathen la configuración del Connect worker.
Rutas relativas y absolutas
Para los despliegues de producción es siempre preferible utilizar rutas absolutas. Consulta la documentación oficial de plugin.path para más detalle de cómo establecer esta configuración.
-
Indicamos la ruta relativa del conector, que este caso es
libs/connect-file-4.0.0.jar -
Hacemos 1 copia del fichero de configuración para el worker
- Hacemos 1 copia del plugin a usar
- Editamos la configuración del worker para que añada el correspondiente plugin para Kafka Connect
- Hacemos una copia de la configuración de los conectores: file-source y file-sink
cp config/connect-file-source.properties /opt/kafka/ejemplo4/config/connect-file-source.properties
cp config/connect-file-sink.properties /opt/kafka/ejemplo4/config/connect-file-sink.properties
- Creamos algunos datos de test en el directorio de nuestro ejemplo
opt/kafka/ejemplo4
echo -e "Hola\nmundo.\nProbando Kafka\nen el modulo Big Data Aplicado\nen el IES Gran Capitán" > test.txt
- Iniciamos proporcionando tres archivos de configuración como parámetros.
- El primero es siempre la configuración para el proceso Kafka Connect, que contiene la configuración común, como los workers de Kafka para conectarse y el formato de serialización de datos.
- Los archivos de configuración restantes especifican cada uno de los conectores. Estos archivos incluyen un nombre de conector único, la clase de conector a instanciar (
connector.class) y cualquier otra configuración requerida por el conector. - Observa el contenido de los archivos de configuración para conocer más y familiarizarte con ellos.
- Como el source file lo tenemos en
/opt/kafka/ejemplo4/, iniciamos esta configuración de Kafka Connect en dicho directorio
/opt/kafka_2.13-4.0.0/bin/connect-standalone.sh /opt/kafka/ejemplo4/config/worker1.properties /opt/kafka/ejemplo4/config/connect-file-source.properties /opt/kafka/ejemplo4/config/connect-file-sink.properties
-
Ahora tenemos dos conectores: el primero es un conector de origen que lee líneas de un archivo de entrada y produce cada una de ellas en un topic de Kafka y el segundo es un conector de destino que lee mensajes de un topic de Kafka y produce cada uno de ellos como una línea en un archivo de salida.
-
Desde el inicio vemos una serie de mensajes de registro, incluyendo algunos que indican que los conectores se están instanciando. Una vez que el proceso de Kafka Connect se ha iniciado, el conector de origen debería empezar a leer líneas de
test.txty producirlas en el topicconnect-test, y el conector sink debería empezar a leer mensajes del topicconnect-testy escribirlos en el archivotest.sink.txt. Podemos verificar que los datos han sido entregados a través de todo el pipeline examinando el contenido del archivo de salida.
tail -f test.sink.txt
Hola
mundo.
Probando Kafka
en el modulo Big Data Aplicado
en el IES Gran Capitán
- Los conectores siguen procesando datos, por lo que podemos añadir datos al archivo y ver cómo se mueven por el pipeline:
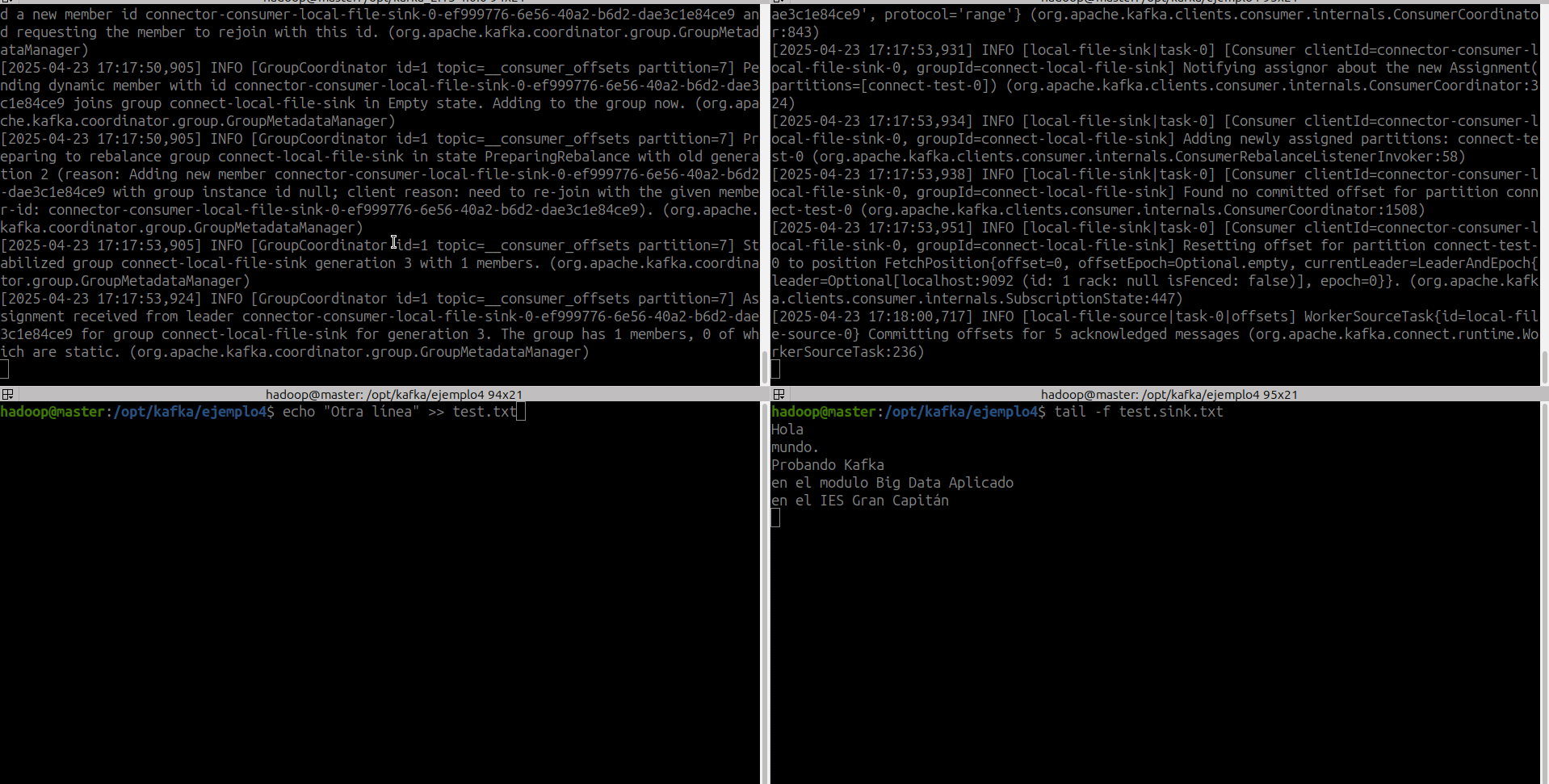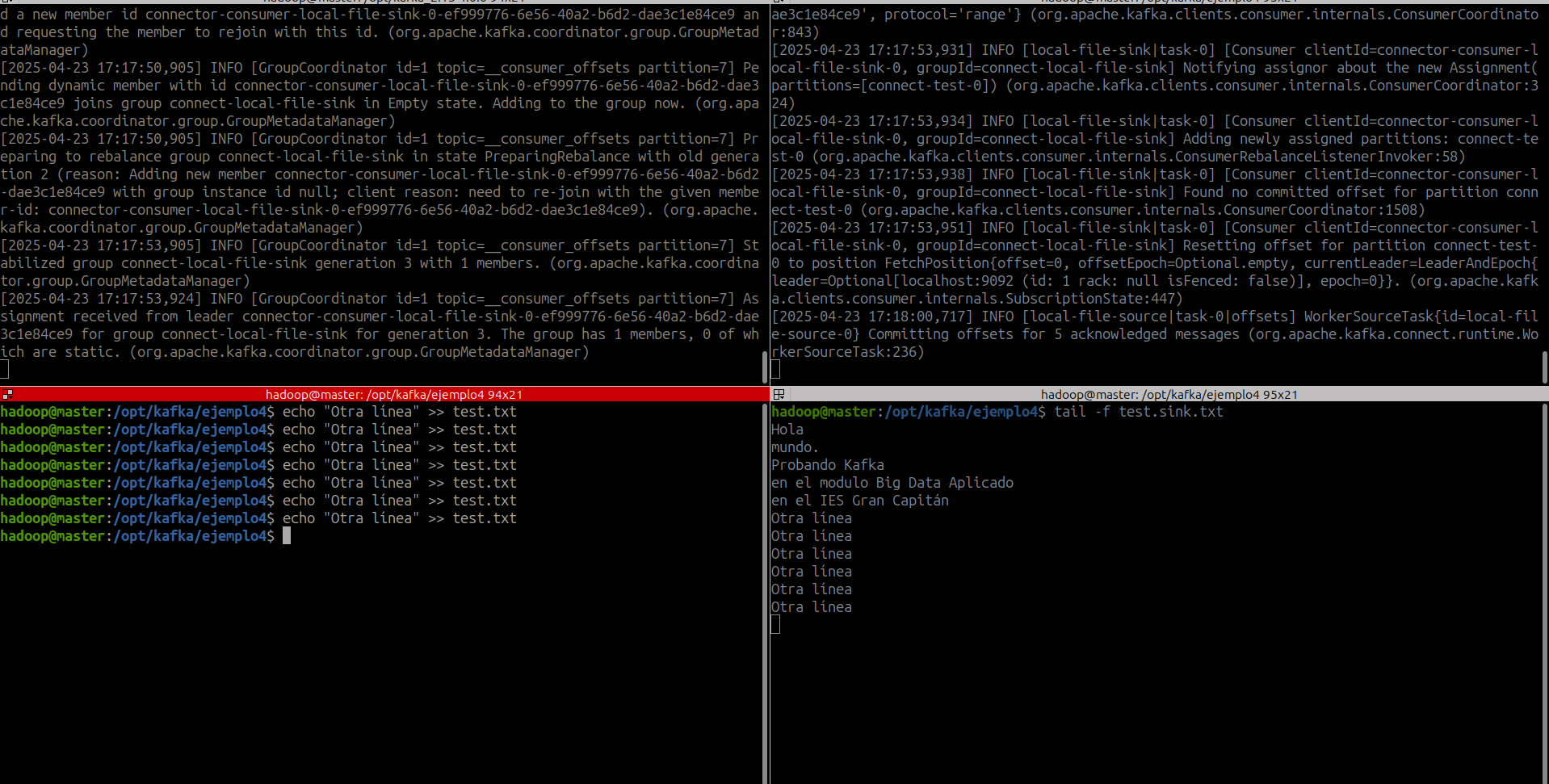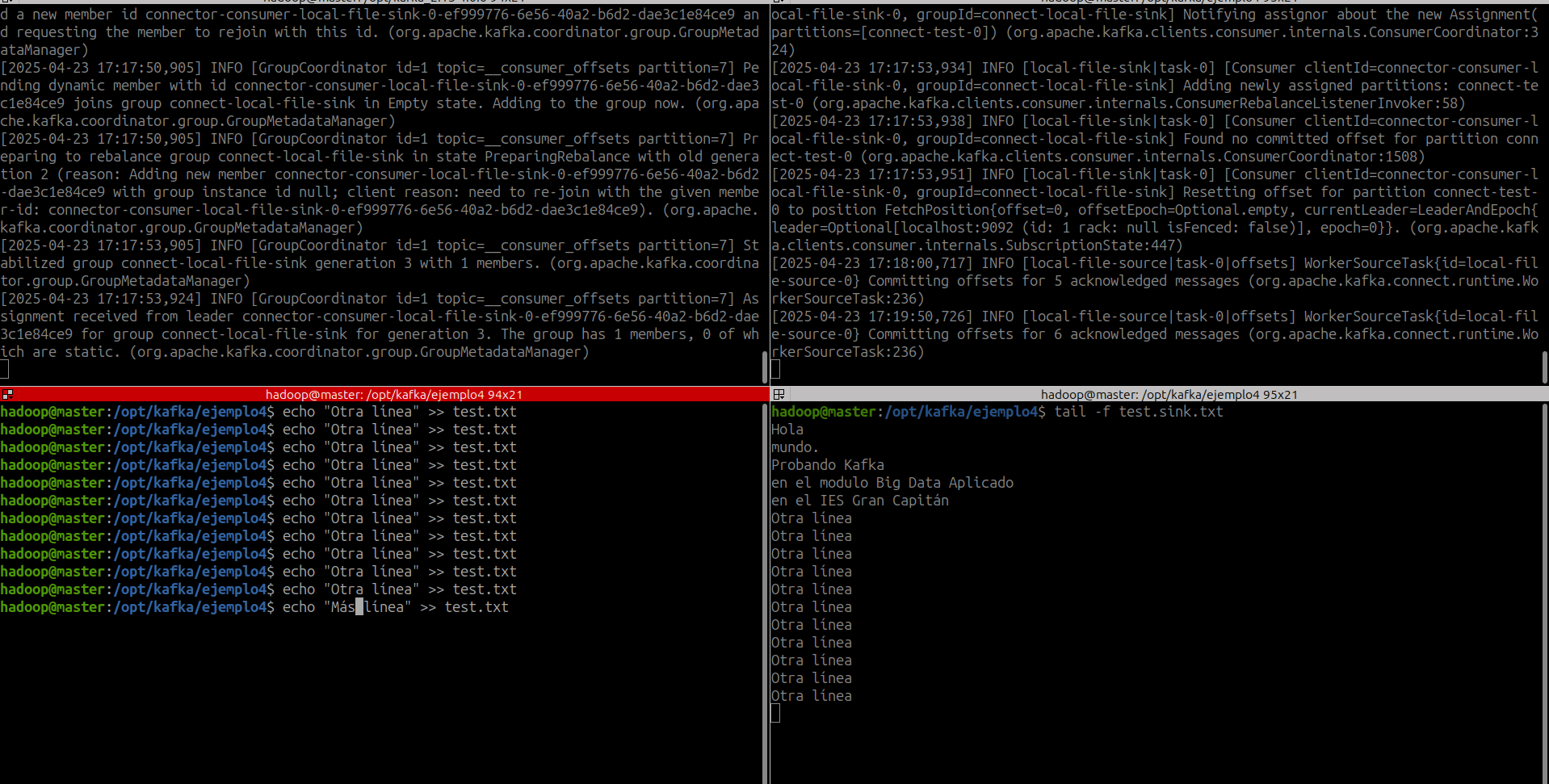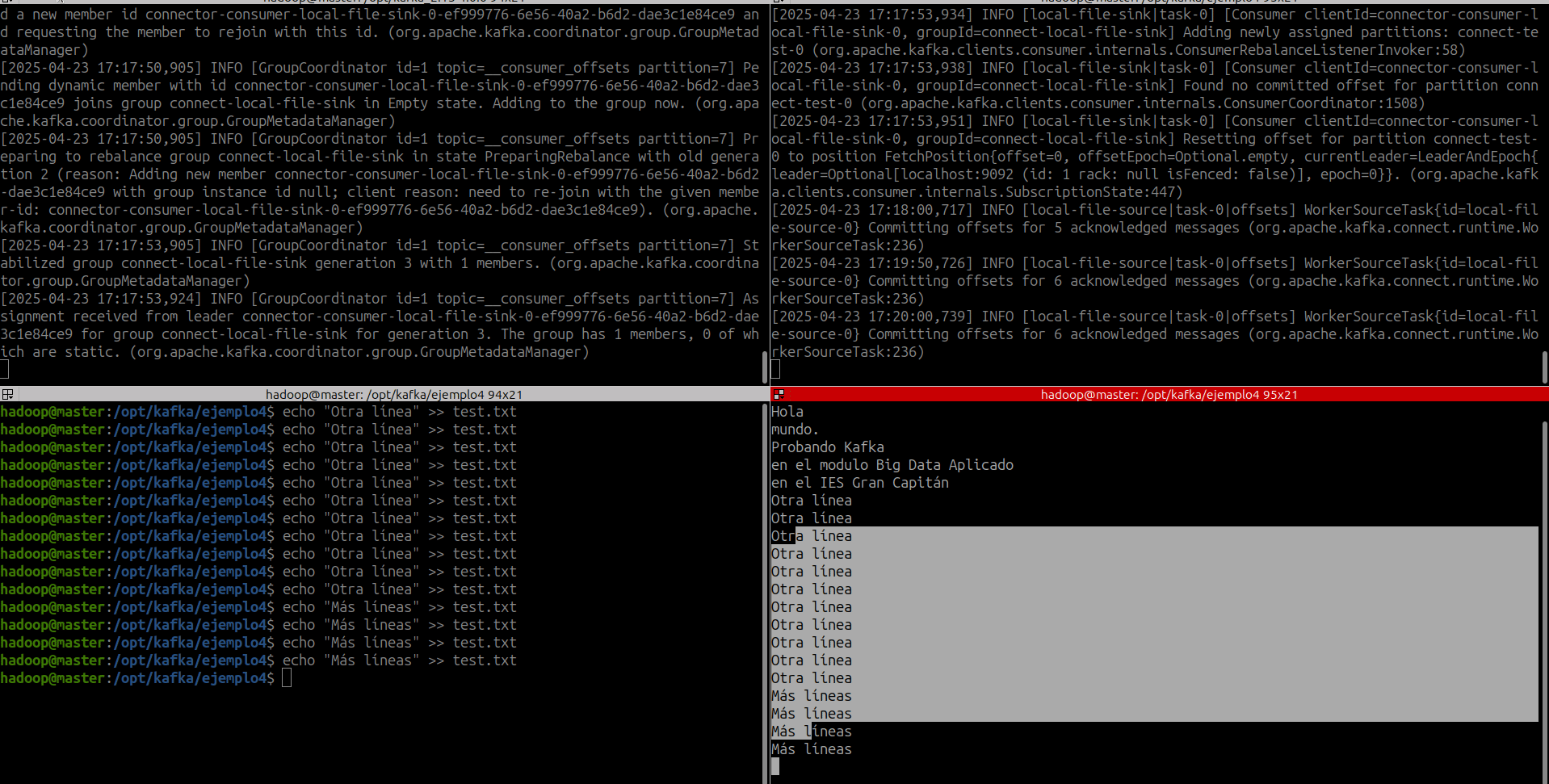
- Debemos tener en cuenta que los datos se almacenan en el topic de Kafka
connect-test, por lo que también podemos ejecutar un consumidor de consola para ver los datos en el topic (o utilizar código de consumidor personalizado para procesarlos):
/opt/kafka_2.13-4.0.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"Hola"}
{"schema":{"type":"string","optional":false},"payload":"mundo."}
{"schema":{"type":"string","optional":false},"payload":"Probando Kafka"}
{"schema":{"type":"string","optional":false},"payload":"en el modulo Big Data Aplicado"}
{"schema":{"type":"string","optional":false},"payload":"en el IES Gran Capitán"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Más líneas"}
Por supuesto, no debemos olvidar que Kafka Connect debe estar conectado con un cluster de Kafka. Para una primera toma de contacto práctico con Kafka Connect, vamos a usar 2 conectores sencillos: uno que importa datos de un archivo de texto (Source) a un topic, y otro que exporta datos (Sink) de un topic a un archivo de texto.
Todo esto lo ejecutaremos en modo Standalone (un solo proceso que ejecuta todo), ideal para pruebas rápidas.
El Nodo Cliente y Kafka Connect quickstart
Para no sobrecargar los contenedores de nuestros Brokers en este ejemplo de toma de contacto con Kafka Connect, ejecutaremos Kafka Connect dentro de nuestro contenedor kafka-client (el nodo frontera que configuramos en apartados anteriores).
En Docker, es más sencillo crear los archivos de configuración en nuestro ordenador (Host) y luego copiarlos al contenedor.
- Levantamos nuestro cluster de Kafka con Docker Compose, asegurándonos de que el nodo cliente esté activo:
- Creamos un directorio de ejemplos para kafka-connect (dentro de nuestro directorio de trabajo anteriormente creado
kafka-ejemplos), y dentro de este directorio, otro para este ejemplo4:
- Nos traemos una copia de los archivos de configuración necesarios para el worker y los conectores, y los editamos para que apunten a las rutas correctas dentro del contenedor:
docker cp kafka-client:/opt/kafka/config/connect-standalone.properties .
docker cp kafka-client:/opt/kafka/config/connect-file-source.properties .
docker cp kafka-client:/opt/kafka/config/connect-file-sink.properties .
Observa el contenido de los archivos de configuración para conocer más y familiarizarte con ellos.
- Configuración del Worker (
worker.properties): Editamosconnect-standalone.propertiespara que apunte al plugin de conexión de archivos. En este caso, el plugin se encuentra en/opt/kafka/libs/connect-file-4.2.0.jardentro del contenedor, por lo que la configuración quedaría así como ves debajo. Puedes modificarconnect-standalone.propertiesy renombrarlo o crear directamente el archivoworker.propertiescon este contenido:
bootstrap.servers=kafka-broker-1:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=/opt/kafka/libs/connect-file-4.2.0.jar
- Configuración del Source (
connect-file-source.properties). Leerá del archivo/tmp/test.txty lo envía al topicconnect-test. Modifica la configuración para que apunte a la ruta correcta del archivo dentro del contenedor:
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=/tmp/test.txt
topic=connect-test
- Configuración del Sink (
connect-file-sink.properties). Leerá del topicconnect-testy lo escribirá en el archivo/tmp/test.sink.txt. Modifica la configuración para que apunte a la ruta correcta del archivo dentro del contenedor:
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/tmp/test.sink.txt
topics=connect-test
- Copiamos los archivos de configuración al contenedor
kafka-client:
docker exec kafka-client mkdir -p /tmp/ejemplo4/config
docker cp worker.properties kafka-client:/tmp/ejemplo4/config/
docker cp connect-file-source.properties kafka-client:/tmp/ejemplo4/config/
docker cp connect-file-sink.properties kafka-client:/tmp/ejemplo4/config/
- Creamos los datos de prueba iniciales: Generamos el archivo
test.txtdirectamente dentro de la carpeta temporal del contenedorkafka-client.
# Linux
docker exec kafka-client bash -c 'echo -e "Hola\nmundo.\nProbando Kafka\nen el modulo Big Data Aplicado\nen el IES Gran Capitán" > /tmp/test.txt'
# Windows
docker exec kafka-client bash -c "echo -e 'Hola\nmundo.\nProbando Kafka\nen el modulo Big Data Aplicado\nen el IES Gran Capitán' > /tmp/test.txt"
- Iniciamos Kafka Connect proporcionando los tres archivos de configuración como parámetros..
- El primero es siempre la configuración para el proceso Kafka Connect, que contiene la configuración común, como los workers de Kafka para conectarse y el formato de serialización de datos.
- Los archivos de configuración restantes especifican cada uno de los conectores. Estos archivos incluyen un nombre de conector único, la clase de conector a instanciar (
connector.class) y cualquier otra configuración requerida por el conector. - Como el source file lo tenemos en
/tmp/, iniciamos esta configuración de Kafka Connect en dicho directorio
Terminal Bloqueada
Este comando mantendrá la terminal ocupada mostrando los logs del proceso de Connect. Déjala abierta y usa una nueva ventana de terminal para los siguientes pasos.
# Linux
docker exec -it kafka-client /opt/kafka/bin/connect-standalone.sh \
/tmp/ejemplo4/config/worker.properties \
/tmp/ejemplo4/config/connect-file-source.properties \
/tmp/ejemplo4/config/connect-file-sink.properties
# Windows
docker exec -it kafka-client /opt/kafka/bin/connect-standalone.sh /tmp/ejemplo4/config/worker.properties /tmp/ejemplo4/config/connect-file-source.properties /tmp/ejemplo4/config/connect-file-sink.properties
-
Ahora tenemos dos conectores: el primero es un conector de origen que lee líneas de un archivo de entrada y produce cada una de ellas en un topic de Kafka y el segundo es un conector de destino que lee mensajes de un topic de Kafka y produce cada uno de ellos como una línea en un archivo de salida.
-
Desde el inicio vemos una serie de mensajes de registro, incluyendo algunos que indican que los conectores se están instanciando. Una vez que el proceso de Kafka Connect se ha iniciado, el conector de origen debería empezar a leer líneas de
test.txty producirlas en el topicconnect-test, y el conector sink debería empezar a leer mensajes del topicconnect-testy escribirlos en el archivotest.sink.txt. Podemos verificar que los datos han sido entregados a través de todo el pipeline examinando el contenido del archivo de salida. -
Abre una nueva terminal. Verifica el archivo de salida (Sink): El conector Sink debería leeros mensajes del topic y haberlos volcado en
test.sink.txt.
- Los conectores siguen procesando datos, por lo que podemos añadir datos al archivo y ver cómo se mueven por el pipeline:
- Verificación de los Datos Internos (Consumidor). Debemos tener en cuenta que los datos se almacenan en el topic de Kafka connect-test, por lo que también podemos ejecutar un consumidor de consola para ver los datos en el topic (o utilizar código de consumidor personalizado para procesarlos):
# Linux
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-broker-1:9092 \
--topic connect-test \
--from-beginning
# Windows
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka-broker-1:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"Hola"}
{"schema":{"type":"string","optional":false},"payload":"mundo."}
{"schema":{"type":"string","optional":false},"payload":"Probando Kafka"}
{"schema":{"type":"string","optional":false},"payload":"en el modulo Big Data Aplicado"}
{"schema":{"type":"string","optional":false},"payload":"en el IES Gran Capitán"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Otra línea"}
{"schema":{"type":"string","optional":false},"payload":"Más líneas"}
{"schema":{"type":"string","optional":false},"payload":"Más líneas"}
5. Plugins y como conectarlos¶
Kafka Connect está diseñado para ser extensible, de modo que los desarrolladores puedan crear conectores, transformaciones y convertidores personalizados, y los usuarios puedan instalarlos y ejecutarlos
Un plugin de Kafka Connect es un complemento de un conjunto de archivos JAR que contienen la implementación de uno o varios conectores, transformaciones o convertidores. Connect aísla cada plugin entre sí, de modo que las bibliotecas de un plugin no se ven afectadas por las bibliotecas de ningún otro plugin. Esto es muy importante cuando se mezclan y combinan conectores de múltiples proveedores.
Warning
Es habitual tener muchos plugins instalados en un entorno en producción de Kafka Connect. Debemos asegurarnos que sólo tenemos instalada una versión de cada plugin.
Un plugin de Kafka Connect puede ser cualquiera de los siguientes:
- Un directorio en el sistema de archivos que contiene todos los archivos JAR necesarios y las dependencias de terceros para el plugin. Esto es lo más habitual y lo preferible.
- Un único JAR que contenga todos los archivos de clase para un plugin y sus dependencias de terceros.
- Directorios que contengan inmediatamente la estructura de directorios de paquetes de clases de plugins y sus dependencias. Nota: se seguirán enlaces simbólicos para descubrir dependencias o plugins.
Ejemplos:
plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors
Un plugin de Kafka Connect nunca debe contener bibliotecas proporcionadas por el tiempo de ejecución de Kafka Connect.
5.1 Configuración de plugins¶
Kafka Connect encuentra los plugins utilizando una ruta definida como una lista separada por comas de rutas de directorio en la propiedad de configuración de worker plugin.path. Por ejemplo:
Para instalar un plugin, como ya hemos visto, debe colocar el directorio del plugin o el conjunto de archivos JAR (o un enlace simbólico que resuelva a uno de ellos) en un directorio que ya figure en la ruta del plugin (plugin.path). O bien, puede actualizar la ruta del plugin añadiendo la ruta absoluta del directorio que contiene el plugin.
Cuando se inician los workers de Connect, cada uno de ellos descubre todos los conectores, transformadores y convertidores que se encuentran en los directorios de la ruta de plugins (plugin.path). Cuando se utiliza un conector, una transformación o un convertidor, el worker de Connect carga primero las clases del plugin correspondiente, seguidas del tiempo de ejecución de Kafka Connect y las bibliotecas Java. Connect evita explícitamente todas las bibliotecas de otros plugins. Esto evita conflictos y hace que sea muy fácil añadir y utilizar conectores y transformaciones desarrollados por distintos proveedores.
5.2 Fuentes de plugins¶
Podemos encontrar plugins para Kafka Connect en varias fuentes confiables, cada una ofreciendo una variedad de conectores diseñados para facilitar la integración de sistemas de almacenamiento de datos, aplicaciones, y APIs con nuestro clúster de Kafka. A continuación listamos las principales:
-
Confluent Hub: Confluent Hub es probablemente la fuente más popular y ampliamente utilizada para encontrar conectores de Kafka Connect. Es una biblioteca digital mantenida por Confluent (la compañía liderada por los co-creadores de Kafka) que ofrece una gran variedad de conectores desarrollados por Confluent y por la comunidad. Aquí encontrarás conectores para bases de datos, sistemas de archivos, servicios en la nube, y muchas otras fuentes de datos y sumideros.
-
Apache Kafka: El propio proyecto Apache Kafka incluye algunos conectores básicos como parte de su distribución (carpeta
config). Estos incluyen conectores para archivos de sistemas (source y sink) y para replicar topics entre clústeres de Kafka (MirrorMaker).- connect-console-sink.properties
- connect-file-source.properties
- connect-console-source.properties
- connect-log4j.properties
- connect-distributed.properties
- connect-mirror-maker.properties
- connect-file-sink.properties
- connect-standalone.properties
-
GitHub: Muchos desarrolladores y empresas publican sus conectores personalizados en GitHub. Puedes buscar repositorios que contengan conectores de Kafka Connect usando términos de búsqueda como "Kafka Connect Connector". Esto puede ser especialmente útil si estás buscando conectores para sistemas menos comunes o para nuevas tecnologías que aún no han sido adoptadas por grandes plataformas como Confluent Hub.
-
Proveedores de Software y Servicios: Algunos proveedores de bases de datos y plataformas de software ofrecen sus propios conectores de Kafka Connect diseñados para trabajar de manera óptima con sus sistemas. Por ejemplo, compañías como MongoDB, Snowflake, Databricks y elastic ofrecen conectores específicos para sus plataformas que están optimizados para el rendimiento y la funcionalidad.
-
Consideraciones al elegir un conector/plugin. Al seleccionar un conector de Kafka Connect, considera lo siguiente:
- Compatibilidad y Requisitos: Asegúrate de que el conector/plugin sea compatible con nuestra versión de Kafka y cumpla con tus requisitos específicos de rendimiento y seguridad.
- Mantenimiento y Soporte: Elegir conectores/plugins que se mantengan activamente y tengan buen soporte.
- Licencia y Coste: Verifica la licencia bajo la cual se distribuye el conector y si hay costes asociados con su uso en producción.
Utilizar la fuente correcta y seleccionar el conector adecuado puede marcar una gran diferencia en la facilidad de integración y la estabilidad de tus flujos de datos en Kafka Connect.
5.3 Instalación y uso¶
Para aprender a instalar un plugin en Kafka Connect, vamos a usar como ejemplo la instalación del Conector JDBC de Confluent para Kafka Connect, que es ampliamente utilizado para integrar bases de datos relacionales con Kafka. Este conector permite a Kafka Connect leer desde y escribir hacia bases de datos usando JDBC.
- Preparación del sistema:
Antes de instalar el conector, asegúrate de que Kafka y Kafka Connect estén instalados y configurados correctamente en tu sistema. Debes tener acceso a las configuraciones por defecto de Kafka Connect, normalmente encontradas en config/connect-distributed.properties o config/connect-standalone.properties, dependiendo de si estás ejecutando Kafka Connect en modo distribuido o standalone.
- Herramienta Confluent CLI (Recomendada si usas cloud de confluent)
Podemos descargarlos de Confluent desde consola usando su herramienta confluent-hub. Deberás instalarla en cada máquina. Siguiendo la documentación oficial:
Para más detalle y uso de otros sistemas sigue los pasos que te indican en su documentación oficial
- Descarga del conector:
Puedes descargarlo de 2 formas diferentes:
- Usando
confluent-hub. Este comando descarga e instala la última versión del conector en el directorio de plugins de Kafka Connect. Durante la instalación, se te preguntará si deseas instalar las dependencias del conector y si quieres actualizar el archivo de configuración de Connect automáticamente.
./bin/confluent connect plugin install confluentinc/kafka-connect-jdbc:latest --plugin-directory /opt/kafka/ejemplo4/libs --worker-configurations /opt/kafka/ejemplo4/config/workers.properties
donde --plugin-directory es el directorio donde vas a guardar el conector y --worker-configurations es el fichero de configuración worker y añade automáticamente la configuración de ruta donde se se ha guardado el conector /opt/kafka/ejemplo4/libs al final de la lista plugin.path
- Descargando el fichero correspondiente y alojarlo en el directorio de configuración
plugin.pathexplicado anteriormente. Accede a la página del conector y descargarlo
- Configuración del conector:
Una vez instalado el conector, debes crear un archivo de configuración para el mismo. Crea un archivo llamado jdbc-source.properties con el siguiente contenido:
name=jdbc-source-connector
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydatabase
connection.user=myuser
connection.password=mypassword
table.whitelist=mytable
mode=timestamp
timestamp.column.name=timestamp_column
topic.prefix=jdbc-
Este archivo configura un conector de fuente JDBC que extrae datos de una tabla específica en una base de datos MySQL. Tendríamos que asegurarnos de ajustar los parámetros de conexión y otros detalles según nuestro entorno específico.
- Inicio de Kafka Connect con el conector:
- En standalone mode:
- En distributed mode:
API REST
En distributed mode, la interacción de los conectores se realiza obligatoriamente a través de la API REST de Kafka Connect, que explicaremos en el siguiente punto. Por este motivo, al iniciarlo en este modo no se le pasa ningún parámetro de configuración de conectores. En standalone mode, como no es en un entorno en producción, podemos usar ambos, tanto pasar por parámetro la configuración del conector como la API REST.
Registramos el conector utilizando la API REST de Kafka Connect:
curl -X POST -H "Content-Type: application/json" --data @jdbc-source.properties http://localhost:8083/connectors
- Verificación
Verificamos que el conector esté funcionando correctamente revisando los logs de Kafka Connect y/o utilizando la API REST para consultar el estado del conector:
Este paso te asegura que el conector esté extrayendo datos de la base de datos y los esté publicando en los topics de Kafka especificados.
6. API REST¶
Kafka Connect está pensado para ser ejecutado como un servicio, y también proporciona una API REST para gestionar conectores. Esta interfaz nos permite interactuar con un servidor Kafka Connect para administrar conectores y sus configuraciones. Proporciona una forma estándar y eficiente para configurar, gestionar y monitorear conectores en un clúster de Kafka Connect, ya sea en modo distribuido o standalone.
Kafka Connect está diseñado para ser operado de manera remota a través de esta API REST, lo que significa que todas las tareas administrativas pueden realizarse sin interactuar directamente con los servidores en sí mismos. Esto incluye:
- Crear, modificar y eliminar conectores: La API permite cargar nuevas configuraciones de conectores, modificar configuraciones existentes y eliminar conectores no deseados.
- Consultar el estado y la configuración de los conectores: Puedes obtener información sobre el estado actual de cualquier conector en el sistema, incluyendo si están corriendo, fallando, o detenidos, y ver detalles específicos de configuración y operación.
- Reiniciar y pausar conectores: La API también ofrece controles para pausar y reiniciar conectores, lo cual es útil para mantenimiento o para recuperarse de errores.
La API REST de Kafka Connect es accesible mediante solicitudes HTTP estándar. Por defecto, el servidor REST se ejecuta en el puerto 8083
API REST on HTTPS
También puede realizarse a través de HTTPS, pero entonces la configuración debe incluir la configuración SSL. Por defecto, se utilizará la configuración ssl.*. Para más detalle consulta la documentación oficial de REST API.
6.1 Endpoints¶
A continuación indicamos una lista de los endpoints actualmente admitidos en la API REST (para más detalle y consultar todos los endpoints, consulta la documentación oficial de REST API):
GET /connectors: Devuelve una lista de conectores activos.POST /connectors: Crea un nuevo conector. El cuerpo de la solicitud debe ser un objeto JSON que contenga un campo stringnamey un campo objetoconfigcon los parámetros de configuración del conector. El objeto JSON también puede contener opcionalmente un campo stringinitial_stateque puede tomar los siguientes valores:STOPPED,PAUSEDoRUNNING(el valor por defecto).GET /connectors/{name}: Obtiene información sobre un conector específico.GET /connectors/{name}/config: Obtiene los parámetros de configuración de un conector específicoPUT /connectors/{name}/config: Actualiza los parámetros de configuración de un conector específicoGET /connectors/{name}/status: Obtiene el estado actual del conector, incluyendo si se está ejecutando, ha fallado, está en pausa, etc., a qué worker está asignado, información de error si ha fallado, y el estado de todas sus tareas.GET /connectors/{name}/tasks: Obtiene una lista de tareas actualmente en ejecución para un conector junto con sus configuraciones.GET /connectors/{name}/tasks/{taskid}/status: Obtiene el estado actual de la tarea, incluyendo si se está ejecutando, ha fallado, está en pausa, etc., a qué worker está asignada, e información de error si ha fallado.PUT /connectors/{name}/pause: Pausa el conector y sus tareas, lo que detiene el procesamiento de mensajes hasta que se reanude el conector. Los recursos reclamados por sus tareas se dejan asignados, lo que permite al conector comenzar a procesar datos rápidamente una vez que se reanuda.PUT /connectors/{name}/stop: Detiene el conector y cierra sus tareas, desasignando cualquier recurso reclamado por sus tareas. Esto es más eficiente desde el punto de vista del uso de recursos que pausar el conector, pero puede hacer que tarde más en empezar a procesar datos una vez reanudado.PUT /connectors/{name}/resume: Reanuda un conector en pausa o detenido (o no hace nada si el conector no está en pausa o detenido)POST /connectors/{name}/restart?includeTasks=<true|false>&onlyFailed=<true|false>: Reinicia un conector y sus instancias de tareas.GET /connector-plugins: Devuelve la lista de plugins disponibles que tienen los workers (no activos)DELETE /connectors/{name}: Eliminar un conector.
6.2 Uso API REST¶
Aquí están algunos ejemplos comunes de cómo puedes interactuar con Kafka Connect utilizando esta API:
- Listar todos los conectores disponibles
Este comando devuelve una lista de todos los conectores configurados en el sistema.
- Obtener la configuración de un conector específico
Reemplaza connector-name por el nombre de tu conector. Este comando devuelve la configuración actual del conector especificado.
- Crear un nuevo conector
Para crear un nuevo conector, puedes enviar una solicitud POST con la configuración del conector en formato JSON:
curl -X POST -H "Content-Type: application/json" --data '{
"name": "connector-name",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max": "1",
"file": "/var/log/myfile.log",
"topic": "my-topic"
}
}' http://localhost:8083/connectors
Este comando configura y lanza un nuevo conector que lee registros de un archivo de log y publica los datos en un topic de Kafka.
- Modificar la configuración de un conector
Para modificar un conector existente, puedes utilizar una solicitud PUT:
curl -X PUT -H "Content-Type: application/json" --data '{
"connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max": "2",
"file": "/var/log/newfile.log",
"topic": "new-topic"
}' http://localhost:8083/connectors/connector-name/config
- Eliminar un conector
Si necesitas eliminar un conector, puedes hacerlo con una solicitud DELETE:
- Consultar el estado de un conector
Para verificar el estado operativo de un conector, usa:
Este comando te dará detalles sobre si el conector está en ejecución, detenido o ha encontrado errores.
Conclusión¶
La API REST de Kafka Connect es una herramienta poderosa para la gestión automatizada y remota de conectores en un clúster de Kafka Connect. Facilita una amplia gama de operaciones administrativas y de monitoreo, lo que la hace indispensable para operar Kafka Connect a escala y en producción. La habilidad para interactuar con Kafka Connect a través de esta API simplifica la integración con herramientas y sistemas de gestión, y permite a los desarrolladores y administradores mantener sus sistemas de manera más eficiente y efectiva.
Para una información más detallada consulta la documentación oficial de REST API.
7. Despliegue de Kafka Connect Distribuido (Docker Compose)¶
En los ejemplos anteriores hemos utilizado Kafka Connect en modo Standalone para pruebas rápidas. Sin embargo, en un entorno de producción real, Kafka Connect siempre se despliega en Modo Distribuido (Distributed Mode).
El modo distribuido ofrece:
- Alta Disponibilidad: Si un worker (nodo de Connect) cae, otro asume sus tareas automáticamente.
- Escalabilidad Dinámica: Puedes añadir más workers al clúster en caliente para procesar más datos.
- Gestión Centralizada: Toda la configuración se guarda en topics internos de Kafka, no en archivos locales. Se gestiona 100% a través de la API REST.
7.1 Ampliando nuestra Arquitectura Docker¶
Vamos a añadir un nuevo servicio a nuestro docker-compose.yml existente.
A diferencia del modo Standalone donde pasábamos un archivo de propiedades, el script connect-distributed.sh requiere ciertas configuraciones clave para conectarse al clúster y definir sus topics de almacenamiento interno.
La Estrategia con la Imagen Oficial
Dado que usamos la imagen pura apache/kafka:4.2.0, esta no procesa automáticamente variables de entorno para Connect (como sí hace Confluent). Para solucionarlo elegantemente, usaremos el bloque environment para definir nuestras variables y un command personalizado que construirá el archivo de propiedades en tiempo de ejecución antes de lanzar el Worker.
7.2 Preparando el Volumen de Plugins¶
En una arquitectura Docker, la mejor práctica es gestionar los plugins mediante volúmenes. Esto mantiene nuestras imágenes de contenedores puras ("Vanilla") e inmutables, y nos permite añadir o actualizar plugins sin necesidad de reconstruir la imagen de Kafka Connect.
Ventaja de este modelo
Al usar volúmenes (:ro, de solo lectura), puedes añadir nuevos conectores (ej. MongoDB, S3) simplemente descargando sus .zip en la carpeta kafka_connect_plugins de tu PC y reiniciando el contenedor de Connect, sin necesidad de construir imágenes Docker personalizadas con Dockerfile.
En la misma carpeta donde tienes tu docker-compose.yml, crearemos una estructura de directorios para alojar nuestros plugins de forma organizada.
# Creamos la carpeta raíz para todos los plugins
mkdir -p kafka_connect_plugins
# Accedemos a la carpeta
cd kafka_connect_plugins
7.2 Configuración del docker-compose.yml¶
Añade este bloque a la sección services de tu fichero, justo debajo de los brokers y Kafka UI.
# -------------------------------------------
# KAFKA CONNECT (INTEGRATION LAYER)
# Arquitectura: Distributed Mode Worker
# -------------------------------------------
kafka-connect:
image: apache/kafka:4.2.0
container_name: kafka-connect
networks:
- bda-network
ports:
- "8083:8083" # Puerto vital para la API REST
environment:
# 1. Variables personalizadas que usaremos en el script de arranque
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
CONNECT_GROUP_ID: bda-connect-cluster
# Formato de datos (JSON con o sin esquemas)
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
# Directorio de plugins (donde Docker montará los .jar externos)
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
# Montamos la carpeta local de plugins (debe existir en el Host)
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
labels:
# Integración opcional con Traefik para acceder a la API REST cómodamente
- "traefik.enable=true"
- "traefik.http.routers.kafkaconnect.rule=Host(`connect.localhost`)"
- "traefik.http.services.kafkaconnect.loadbalancer.server.port=8083"
- "traefik.http.routers.kafkaconnect.entrypoints=web"
# --- COMANDO DE INICIALIZACIÓN ---
# 1. Crea un archivo properties con nuestras variables
# 2. Inicia el worker distribuido usando ese archivo
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
No lo añadas todavía a tu docker compose, lo haremos en el siguiente punto usando YAML Anchors para evitar repetir código.
7.3 Anatomía de la Configuración Distribuida¶
Es importante entender qué acabamos de inyectar en el archivo connect-distributed.properties:
group.id: Identifica al clúster de Connect. Si lanzas otro contenedor con el mismogroup.id, se unirán y trabajarán juntos repartiéndose la carga.- Topics Internos (
offset.storage.topic,config...,status...): En modo distribuido, Connect no usa archivos locales. Guarda las configuraciones de tus conectores y el progreso de lectura (offsets) en estos topics especiales dentro de Kafka. Le hemos asignado un factor de replicación de 3 para asegurar alta disponibilidad. plugin.path: Apunta a la carpeta/opt/kafka/pluginsdonde hemos montado nuestro volumen local./kafka_connect_plugins. Aquí es donde depositaremos los archivos.jarde los nuevos conectores.
7.4 Escalabilidad¶
Para tener Alta Disponibilidad (HA) y balanceo de carga real, necesitamos 3 workers. Si uno de los contenedores muere, los otros dos se repartirán automáticamente las tareas de los conectores que estuvieran corriendo en el nodo caído.
¿Cómo saben 3 contenedores distintos que forman parte del mismo equipo de Kafka Connect?
Por la variable CONNECT_GROUP_ID (que mapeamos a group.id).
Mientras los tres contenedores apunten a los mismos brokers y tengan el mismo group.id (en nuestro caso, bda-connect-cluster), se descubrirán automáticamente a través de Kafka y formarán un clúster. No tenemos que configurarles las IPs de los otros workers.
Uso de YAML Anchors¶
Podríamos copiar y pegar el bloque gigante de kafka-connect tres veces, cambiando solo los nombres y los puertos (8083, 8084, 8085). Pero como Arquitectos, odiamos repetir código (Principio DRY - Don't Repeat Yourself).
Vamos a usar una característica avanzada de Docker Compose llamada YAML Anchors (& y *) para definir la plantilla base una vez, y reutilizarla en los 3 workers.
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)
(Hemos quitado los labels de Traefik aquí para mantenerlo sencillo, ya que al tener 3 workers interactuaremos con la API REST directamente apuntando a cualquiera de sus puertos: 8083, 8084 u 8085. Al ser un clúster, si le envías la orden de crear un conector al worker 2 (puerto 8084), este lo compartirá con el resto).
7.5 Kafka Connect en kafka UI¶
Para facilitar la gestión de nuestro clúster de Kafka Connect, vamos a integrar la UI de Kafbat que ya tenemos desplegada. Esta UI se conecta a los brokers de Kafka para descubrir los topics internos que Connect utiliza para almacenar su configuración y estado, y nos permite gestionar nuestros conectores de forma visual.
Para ello, debemos configurar las siguientes variables de entorno en el servicio de Kafbat UI en nuestro docker-compose.yml:
kafbat-ui:
image: ghcr.io/strimzi/kafbat-ui:latest
container_name: kafbat-ui
networks:
- bda-network
environment:
# Todas las variables de entorno que ya tenemos configuradas
# Añadimos la configuración para conectar con Kafka Connect
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
#Resto de configuración de Kafbat UI...
Con esta configuración, la UI de Kafbat se conectará automáticamente a la API REST de Kafka Connect a través del worker 1 (puerto 8083) y descubrirá los topics internos (connect-configs, connect-offsets, connect-status) que Connect utiliza para almacenar su configuración y estado. Esto nos permitirá gestionar nuestros conectores de forma visual desde la UI.
7.6 Verificación del Servicio¶
- Recuerda Asegúrate de que la carpeta de plugins existe en tu ordenador antes de levantar el contenedor:
Levanta el nuevo servicio:
- Una vez que el contenedor arranque y se conecte a los brokers, la API REST estará disponible. Podemos verificarlo consultando la raíz de la API (desde tu máquina Host):
Respuesta esperada: Verás un JSON devolviendo la versión de Kafka Connect instalada y el ID de confirmación del clúster (confirmando que está listo para recibir peticiones POST para crear conectores).
-
Abre Kafbat UI en tu navegador (
http://kafka.localhost). -
Si la UI está bien conectada y los workers han arrancado (tardan unos 10-15 segundos en sincronizarse), Kafka creará automáticamente tres nuevos topics internos:
connect-configsconnect-offsetsconnect-status
En el siguiente ejemplo práctico veremos cómo utilizar esta API REST para inyectar conectores Source y Sink en nuestro clúster recién configurado.
- Puedes preguntar a cualquiera de los tres nodos si están vivos:
# Terminal
curl http://localhost:8083/
curl http://localhost:8084/
curl http://localhost:8085/
# Browser
http://localhost:8083/
http://localhost:8084/
http://localhost:8085/
- Consulta los logs de docker para verificar que los workers se han unido al clúster correctamente:
- Comprueba también que puedes ver Kafka Connect en la UI de Kafbat, y que los topics internos de Connect están siendo reconocidos.
7.7 Docker Compose del cluster completo¶
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
# Le inyectamos el worker directamente. La UI lo auto-descubrirá.
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)
8. Ejemplo 5. Usando Kafka Connect¶
Supongamos que tenemos el siguiente escenario
- Tenemos un cluster de Kafka de 3 nodos con 2 brokers y un controller (mismo que el ejemplo 2)
- Configuraremos un cluster kafka Connect con varios workers utilizando 2 conectores(1 source y un sink)
- Source: obtendremos datos de una Base de Datos Mysql consumiendo por CDC (Change Data Capture)
- Sink: Guardaremos los datos en HDFS
- Este ejemplo estará orientado a un entorno de producción, asegurando alta disponibilidad y escalabilidad
- Aunque no olvidemos que estamos realizando una prueba de concepto. Realizaremos la configuración en un sola máquina. En un entorno real nuestros servidores deberían estar en máquinas diferentes.
- En un entorno en producción, habría que establecer correctamente las particiones, réplicas, offset, storage, ... más convenientes dependiendo de tu entorno real. Para el ejemplo, configuraremos algunas de ellas sin entrar en más detalle.
- Vamos a aprovechar nuestro cluster de Hadoop para la realización de este ejemplo
8.1 Preparación del entorno¶
-
Voy a usar como máquina donde ejecutaremos Kafka y Kafka Connect la misma que en el ejemplo 2, donde ya tenemos todas las configuraciones preparadas para ejecutar el cluster de Kafka.
-
Todos los conectores los voy a descargar en la carpeta
/opt/kafka/plugins. De aquí los ire copiando a la carpeta correspondiente según el ejemplo/ejercicio en cuestión. -
Descargamos el source connector. Como hemos visto en el apartado anterior, tenemos 2 formas de descargar el conector, con la herramienta confluent-cli o descargando el conector directamente. Nosotros optaremos por la segunda.
wget https://hub-downloads.confluent.io/api/plugins/confluentinc/kafka-connect-jdbc/versions/10.8.3/confluentinc-kafka-connect-jdbc-10.8.3.zip
- Descomprimimos
- Observa la documentación oficial del conector. Allí se indica que también necesitamos el conector especifico del SGBD. Seguimos los pasos y descargamos el conector de Mysql(Observa siempre la documentación oficial de cada conector, que te indicará toda la información necesaria para su configuración.)
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-9.3.0.tar.gz
tar -xzf mysql-connector-j-9.3.0.tar.gz
- Descargamos el sink connector para guardar los datos en nuestro HDFS.
wget https://hub-downloads.confluent.io/api/plugins/confluentinc/kafka-connect-hdfs3/versions/1.2.6/confluentinc-kafka-connect-hdfs3-1.2.6.zip
- Descomprimimos
-
Observa la documentación oficial del conector. Observa también la configuración del conector, para ver los diferentes parámetros de configuración.
-
Creamos los directorios necesarios para todo el ejemplo
mkdir -p /opt/kafka/ejemplo5/libs
mkdir -p /opt/kafka/ejemplo5/config
mkdir -p /opt/kafka/ejemplo5/logs
- Copiaremos los directorios completos y el fichero
jardemysql-connecten nuestro directoriolibsdel ejemplo4:
cp -r confluentinc-kafka-connect-jdbc-10.8.3/ /opt/kafka/ejemplo5/libs/
cp mysql-connector-j-9.3.0/mysql-connector-j-9.3.0.jar /opt/kafka/ejemplo5/libs/confluentinc-kafka-connect-jdbc-10.8.3/lib
cp -r confluentinc-kafka-connect-hdfs3-1.2.6/ /opt/kafka/ejemplo5/libs/
- Para mysql usaremos la imagen de docker mysql. Lanzaremos la instancia en nuestro host
Docker context
Si estas usando docker desktop, no podrás ejecutar docker y VirtualBox simultáneamente, ya que ambos usan el mismo hipervisor para virtualizar. Por tanto, tendrás que cambiar el contexto de docker a default, para usar directamente el demonio docker desde la consola. No olvides volver a cambiarlo cuando termines si quieres usar tu configuración original de Docker Desktop
$ docker context ls
NAME TYPE DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
default * moby Current DOCKER_HOST based configuration unix:///var/run/docker.sock
desktop-linux moby Docker Desktop unix:///home/jaime/.docker/desktop/docker.sock
$ docker context use desktop-linux
desktop-linux
Current context is now "desktop-linux"
$ docker context ls
NAME TYPE DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
default moby Current DOCKER_HOST based configuration unix:///var/run/docker.sock
desktop-linux * moby Docker Desktop unix:///home/jaime/.docker/desktop/docker.sock
$ docker context use default
default
Current context is now "default"
$ docker context ls
NAME TYPE DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
default * moby Current DOCKER_HOST based configuration unix:///var/run/docker.sock
desktop-linux moby Docker Desktop unix:///home/jaime/.docker/desktop/docker.sock
docker run -d \
--rm \
--name mysql-kafka \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=pass \
-v mysql_data:/var/lib/mysql \
mysql:latest
- Usaremos también la imagen de docker phpmyadmin para mayor comodidad.
docker run -d \
--rm \
--name phpmyadmin-kafka \
--link mysql-kafka \
-e PMA_HOST=mysql-kafka \
-p 8080:80 \
phpmyadmin
Podemos entrar con las credenciales root/pass
8.2 Cluster Kafka¶
Recuerda que usaremos la misma configuración y máquina que en el ejemplo 2
- Hacemos 2 y 1 copia de los ficheros correspondientes de configuración
cp config/controller.properties /opt/kafka/ejemplo5/config/controller1.properties
cp config/broker.properties /opt/kafka/ejemplo5/config/broker1.properties
cp config/broker.properties /opt/kafka/ejemplo5/config/broker2.properties
- Asignamos la configuración al controller
# Server Basics
process.roles=controller
node.id=1
controller.quorum.bootstrap.servers=localhost:9093
# Socket Server Settings
listeners=CONTROLLER://:9093
advertised.listeners=CONTROLLER://localhost:9093
controller.listener.names=CONTROLLER
# Log Basics
log.dirs=/opt/kafka/ejemplo5/logs/controller1
- Asignamos la siguiente configuración para cada broker
- Iniciamos Kafka
#Genera un cluster UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
echo $KAFKA_CLUSTER_ID
#Formateamos los directorios de log
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID --standalone -c /opt/kafka/ejemplo5/config/controller1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo5/config/broker1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo5/config/broker2.properties
- Iniciamos los server(1 controller y 2 brokers) cada uno en una terminal
#Ejecuta el servidor Kafka
bin/kafka-server-start.sh /opt/kafka/ejemplo5/config/controller1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo5/config/broker1.properties
bin/kafka-server-start.sh /opt/kafka/ejemplo5/config/broker2.properties
8.3 Creamos el topic¶
- Creamos el topic con factor de replica 2 y 2 particiones. El topic debe conectarse a un broker.
bin/kafka-topics.sh --create --topic empleados-employees --bootstrap-server localhost:9094 --replication-factor 2 --partitions 2
- Podemos ver la descripción del topic creado
Topic: empleados-employees TopicId: Wb5iAoULQ2q9SaezabSv2w PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: empleados-employees Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2 Elr: LastKnownElr:
Topic: empleados-employees Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Elr: LastKnownElr:
- Incluso podemos ver los topics existentes
Los topics __consumer_offsets, connect-configs, connect-offsets y connect-status serán creados por el propio Kafka Connect cuando iniciemos los workers
- Aprovecharemos la Consumer API para ver como Kafka Connect está consumiendo los datos correctamente
bin/kafka-console-consumer.sh --topic empleados-employees --from-beginning --bootstrap-server localhost:9094
8.4 Cluster Kafka Connect¶
Siguiendo nuestro escenario, vamos a levantar 3 workers, para cumplir una correcta Alta disponibilidad, Balanceo de carga y Escalabilidad.
- Configuración de los workers. Estos apuntan a los brokers del cluster de Kafka(
bootstrap.servers)
bootstrap.servers=localhost:9094,localhost:9095
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=2
config.storage.topic=connect-configs
config.storage.replication.factor=2
status.storage.topic=connect-status
status.storage.replication.factor=2
plugin.path=/opt/kafka/ejemplo5/libs
listeners=http://localhost:8083
bootstrap.servers=localhost:9094,localhost:9095
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=2
config.storage.topic=connect-configs
config.storage.replication.factor=2
status.storage.topic=connect-status
status.storage.replication.factor=2
plugin.path=/opt/kafka/ejemplo5/libs
listeners=http://localhost:8084
bootstrap.servers=localhost:9094,localhost:9095
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=2
config.storage.topic=connect-configs
config.storage.replication.factor=2
status.storage.topic=connect-status
status.storage.replication.factor=2
plugin.path=/opt/kafka/ejemplo5/libs
listeners=http://localhost:8085
Entorno de producción real
Recuerda que estamos simulando un entorno real pero en una sola máquina. Debido a esto, hemos tenido que añadir en la configuración que la API REST de cada worker escuche en puertos diferentes con la propiedad listeners, que puedes consultar en la documentación oficial. En un entorno real, para asegurar la Alta Disponibilidad, Redundancia, Tolerancia a Fallos y Balanceo de Carga habría que desplegar los workers en diferentes nodos y/o zonas de disponibilidad. Y por tanto, no tendríamos que modificar este puerto. En ese caso, el fichero de configuración podría ser el mismo.
-
Guardamos en
/opt/kafka/ejemplo5/config -
Iniciamos los 3 workers de Kafka Connect (cada uno en una terminal)
bin/connect-distributed.sh /opt/kafka/ejemplo5/config/worker1.properties
bin/connect-distributed.sh /opt/kafka/ejemplo5/config/worker2.properties
bin/connect-distributed.sh /opt/kafka/ejemplo5/config/worker3.properties
- Puedes comprobar en el log que los workers están levantados (cada uno escuchando en su puerto correspondiente) y podemos hacer una consulta a través de la API REST, que evidentemente, devolverá que no hay conectores todavía:
curl http://localhost:8083/connectors
curl http://localhost:8084/connectors
curl http://localhost:8085/connectors
- Podemos ver también la lista de plugins y conectores que los workers tienen a su disposición
Si quieres mejorar el formato de salida
8.5 Preparación de Source y Sink¶
Preparación de nuestros datos en mysql¶
Para nuestra Base de Datos de prueba, vamos a usar una propia desarrollada por Mysql para entornos de pruebas, llamada "employee data". Mysql dispone de varias. Nuestra BD elegida tiene su propia documentación y propio repositorio en github, que vamos a usar.
- Descargamos los datos y los copiamos en el contenedor
- Entramos en el contenedor
- Creamos la Base de datos y el dataset. Este comando nos pedirá la contraseña de tu usuario MySQL y luego creará una nueva base de datos llamada employees con varias tablas llenas de datos.
- Comprobamos entrando
- Mostramos las bases de datos y elegimos
employees
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| employees |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use employees;
- Observamos la tabla
employees(SELECT * FROM employees;) o mediante phpmyadmin que los datos de la base de datos se han cargado correctamente
mysql> SELECT * FROM employees;
...
...
...
| 499998 | 1956-09-05 | Patricia | Breugel | M | 1993-10-13 |
| 499999 | 1958-05-01 | Sachin | Tsukuda | M | 1997-11-30 |
+--------+------------+----------------+------------------+--------+------------+
300024 rows in set (0.13 sec)
- También podemos mediante phpmyadmin (
http://localhost:8080/) que los datos de la base de datos se han cargado correctamente
Preparación de HDFS¶
-
Tener Hadoop levantado y que no esté en modo seguro.
-
Crear el directorio correspondiente en nuestro HDFS:
hdfs dfs -mkdir -p /bda/kafka/ejemplo5.
8.6 Conectores¶
- Source Conector (JDBC): Debemos tener en cuenta la configuración de nuestro mysql. Guárdalo en
/opt/kafka/ejemplo5/config
{
"name": "mysql-employees-source-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "3",
"connection.url": "jdbc:mysql://192.168.56.1:3306/employees",
"connection.user": "root",
"connection.password": "pass",
"table.whitelist": "employees",
"mode": "incrementing",
"incrementing.column.name": "emp_no",
"topic.prefix": "empleados-",
"logs.dir": "/opt/kafka/ejemplo5/logs/JdbcSource",
"poll.interval.ms": "5000"
}
}
Cuando este conector utiliza tablas de base de datos como fuente de datos, asigna a cada tabla un topic de Kafka con el formato <prefix><table_name>. Si el conector está configurado para utilizar una consulta personalizada, el nombre del tema es simplemente <prefix>. El prefijo es obligatorio mediante la propiedad topic.prefix. Puedes consultar esta información en la documentación del conector
Con la propiedad table.whitelist indicamos que queremos copiar toda la tabla y "mode": "incrementing" para que esa replica esté basada en una columna de incremento. Podríamos especificar una consulta determinada, para ellos eliminamos la propiedad table.whitelist y añadimos la query especifica, por ejemplo "query": "SELECT * FROM employees WHERE department_id = 5"
- Sink Conector (HDFS): Debemos tener en cuenta la configuración de nuestro HDFS. Guárdalo en
/opt/kafka/ejemplo5/config
{
"name": "hdfs3-employees-sink-connector",
"config": {
"connector.class": "io.confluent.connect.hdfs3.Hdfs3SinkConnector",
"tasks.max": "3",
"confluent.topic.bootstrap.servers": "localhost:9094",
"topics": "empleados-employees",
"store.url": "hdfs://cluster-bda:9000/bda/kafka/ejemplo5",
"logs.dir": "logs/hdfs3sink",
"format.class": "io.confluent.connect.hdfs3.avro.AvroFormat",
"path.format": "'year'=YYYY/'month'=MM/'day'=dd",
"flush.size": "1000",
"hadoop.conf.dir": "/opt/hadoop-3.4.1/etc/hadoop/",
"hadoop.home": "/opt/hadoop-3.4.1/"
}
}
No olvides crear el directorio correspondiente en nuestro HDFS: hdfs dfs -mkdir -p /bda/kafka/ejemplo5. Por supuesto, asegúrate de tener Hadoop levantado y no esté en modo seguro.
8.7 Iniciar conectores¶
Usando la API REST vamos a iniciar estos conectores
- Primero comprobamos los conectores activos, que no debería haber ninguno
-
Justo antes de iniciar los conectores, observa la ventana donde hemos usado Consumer API para observar como consume los datos de la Base de Datos.
-
Iniciamos los conectores. Recuerda que puedes pasar directamente la configuración en el endpoint
curl -X POST -H "Content-Type: application/json" --data @/opt/kafka/ejemplo5/config/mysql-employees-source-connector.json http://localhost:8083/connectors
curl -X POST -H "Content-Type: application/json" --data @/opt/kafka/ejemplo5/config/hdfs3-employees-sink-connector.json http://localhost:8083/connectors
- Comprobamos que están activos
curl http://localhost:8083/connectors
curl http://localhost:8083/connectors/mysql-employees-source-connector/status
curl http://localhost:8083/connectors/hdfs3-employees-sink-connector/status
- También puedes usar aplicaciones de terceros como POSTMAN
8.8 Ejecución¶
Observa el video de la ejecución de nuestro ejemplo:
-
Usamos Consumer API para observar como Kafka consume los registros de la Base de Datos.
-
Iniciamos el primer conector, que accede a la base de datos. En ese momento, Consumer API muestra como procesa los datos Kafka.
-
Iniciamos el segundo conector, que accede a HDFS, transforma los datos en formato Avro y los almacena en el directorio indicado.
-
Podemos ver como son almacenados los datos en HDFS

En este caso de uso práctico, diseñaremos un flujo de datos (Pipeline) End-to-End en nuestro entorno Docker.
El Escenario:
- Source: Extraeremos datos de una base de datos MySQL (simulando captura de cambios) utilizando el conector JDBC Source.
- Mensajería: Los datos viajarán a través de nuestro clúster de Kafka.
- Sink: Kafka Connect escribirá estos datos directamente en nuestro Hadoop HDFS.
8.1 Descarga y Montaje de Conectores/Plugins (Docker)¶
-
Debemos descargar los conectores y el driver de MySQL en nuestra carpeta compartida
kafka_connect_pluginsdel Host. -
Descargamos y descomprimimos el source connector. Como hemos visto en el apartado anterior.
# Conector Source (JDBC)
# Dentro de la carpeta kafka_connect_plugins
wget https://hub-downloads.confluent.io/api/plugins/confluentinc/kafka-connect-jdbc/versions/10.9.2/confluentinc-kafka-connect-jdbc-10.9.2.zip
unzip confluentinc-kafka-connect-jdbc-10.9.2.zip
Si en enlace no funciona, descárgalo manualmente y cópialo en tu sistema
- Observa la documentación oficial del conector. Allí se indica que también necesitamos el conector especifico del SGBD. Seguimos los pasos y descargamos el conector de Mysql(Observa siempre la documentación oficial de cada conector, que te indicará toda la información necesaria para su configuración.)
# Dentro de la carpeta kafka_connect_plugins
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-9.6.0.tar.gz
tar -xzf mysql-connector-j-9.6.0.tar.gz
- Movemos el driver: En nuestro host, sacamos el .jar de MySQL de la subcarpeta y lo ponemos directamente en kafka_connect_plugins y Kafka Connect lo vea y pueda compartirlo con otros plugins si fuera necesario
# Dentro de la carpeta kafka_connect_plugins
mkdir -p drivers
cp mysql-connector-j-9.6.0/mysql-connector-j-9.6.0.jar drivers/
Carga del driver MySQL
En nuestro docker-compose, debemos añadir la linea - ./drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro, para montar el driver de MySQL dentro de la carpeta raíz de plugins de Kafka Connect (/opt/kafka/libs). Así evitamos que lo cargue de forma independiente, lo que no funcionaría, porque el conector JDBC necesita ese driver para hacer la conexión a MySQL.
- Descargamos y descomprimimos el sink connector para guardar los datos en nuestro HDFS.
wget https://hub-downloads.confluent.io/api/plugins/confluentinc/kafka-connect-hdfs3/versions/3.0.6/confluentinc-kafka-connect-hdfs3-3.0.6.zip
unzip confluentinc-kafka-connect-hdfs3-3.0.6.zip
-
Observa la documentación oficial del conector. Observa también la configuración del conector, para ver los diferentes parámetros de configuración.
-
Esta deberá ser la estructura de tu carpeta
kafka_connect_pluginsen tu host.
kafka_connect_plugins/
├── confluentinc-kafka-connect-jdbc-10.9.2/
├── confluentinc-kafka-connect-hdfs3-3.0.6/
└── drivers/mysql-connector-j-9.6.0.jar <-- El driver suelto aquí
- Una vez descargados, levantamos nuestro docker compose.En el caso ya tener leventado el cluster con docker compose, reinicia el clúster de Kafka Workers para que los workers carguen los nuevos archivos
.jar.
# Levantamos el cluster con docker compose
docker compose up -d
# En caso de tenerlo ya levantado, reiniciamos los workers para que carguen los nuevos conectores y el driver de MySQL
docker compose up -d --force-recreate kafka-worker-1 kafka-worker-2 kafka-worker-3
- Verificamos la carga de los conectores usando la API REST (o entrando a Kafbat UI):
- Puedes consultar los logs de los workers para verificar que han cargado correctamente los conectores y no hay errores relacionados con las librerías.
8.2 Preparación de la Infraestructura (Docker)¶
Dado que usamos una arquitectura basada en contenedores, todo debe estar conectado a la misma red virtual (bda-network).
- Levantar Base de Datos (MySQL). Para mysql usaremos la imagen de docker mysql. Lanzaremos un contenedor efímero de MySQL en nuestra red de Big Data.
docker run -d \
--name mysql-kafka \
--network bda-network \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=pass \
-v mysql_data:/var/lib/mysql \
mysql:latest
- Levantar phpMyAdmin (Opcional). Para mayor comodidad, también podemos lanzar un contenedor de phpMyAdmin conectado a la misma red, para gestionar visualmente nuestra base de datos (Lo levantamos en el puerto 8079 en lugar del 8080 para no tener conflicto con el servicio Yarn).
docker run -d \
--name phpmyadmin-kafka \
--network bda-network \
-e PMA_HOST=mysql-kafka \
-p 8079:80 \
phpmyadmin
Podemos entrar con las credenciales root/pass
- Preparación de nuestros datos en mysql (Employees DB). Para nuestra Base de Datos de prueba, vamos a usar una propia desarrollada por Mysql para entornos de pruebas, llamada "employee data". Mysql dispone de varias. Nuestra BD elegida tiene su propia documentación y propio repositorio en github, que vamos a usar.
# 1. Clonar repositorio en tu máquina (Host)
git clone https://github.com/datacharmer/test_db.git
# 2. Copiar archivos al contenedor MySQL
docker cp test_db mysql-kafka:/tmp/test_db
# 3. Importar los datos
docker exec -it mysql-kafka bash -c "cd /tmp/test_db && mysql -u root -ppass < employees.sql"
# 4. Verificar que los datos se han cargado correctamente
docker exec -it mysql-kafka mysql -u root -ppass -e "USE employees; SELECT COUNT(*) FROM employees;"
(Debería devolver unas 300,000 filas).
- Preparación de HDFS. Asegúrate de tener Hadoop levantado y no esté en modo seguro. Crea el directorio correspondiente en nuestro HDFS:
# Usamos el namenode (como root de HDFS) para preparar la carpeta
docker exec namenode hdfs dfs -mkdir -p /bda/kafka/ejemplo5
docker exec namenode hdfs dfs -chmod -R 777 /bda/kafka
8.3 Configuración de los Conectores (Docker)¶
En el modo distribuido, no pasamos archivos .properties por consola. Enviamos un archivo JSON a la API REST.
- Para ello, crearemos estos dos archivos en tu host, dentro de la carpeta de plugins
kafka_connect_plugins/config:
- Source Conector (JDBC): Debemos tener en cuenta la configuración de nuestro mysql. Guárdalo en
kafka_connect_plugins/config.
Nota: Fíjate que usamos el nombre del contenedor mysql-kafka en la URL de conexión.
{
"name": "mysql-employees-source-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "3",
"connection.url": "jdbc:mysql://mysql-kafka:3306/employees",
"connection.user": "root",
"connection.password": "pass",
"table.whitelist": "employees",
"mode": "incrementing",
"incrementing.column.name": "emp_no",
"topic.prefix": "empleados-",
"poll.interval.ms": "5000"
}
}
Cuando este conector utiliza tablas de base de datos como fuente de datos, asigna a cada tabla un topic de Kafka con el formato <prefix><table_name>. Si el conector está configurado para utilizar una consulta personalizada, el nombre del tema es simplemente <prefix>. El prefijo es obligatorio mediante la propiedad topic.prefix. Puedes consultar esta información en la documentación del conector
Con la propiedad table.whitelist indicamos que queremos copiar toda la tabla y "mode": "incrementing" para que esa replica esté basada en una columna de incremento. Podríamos especificar una consulta determinada, para ellos eliminamos la propiedad table.whitelist y añadimos la query especifica, por ejemplo "query": "SELECT * FROM employees WHERE department_id = 5"
- Sink Conector (HDFS): Debemos tener en cuenta la configuración de nuestro HDFS. Guárdalo en
kafka_connect_plugins/config
Nota de Arquitectura: Kafka Connect en Docker no tiene las librerías de Hadoop. El conector HDFS3 intentará conectarse mediante la URI proporcionada.
{
"name": "hdfs3-employees-sink-connector",
"config": {
"connector.class": "io.confluent.connect.hdfs3.Hdfs3SinkConnector",
"tasks.max": "3",
"topics": "empleados-employees",
"store.url": "hdfs://namenode:9000/bda/kafka/ejemplo5",
"flush.size": "1000",
"format.class": "io.confluent.connect.hdfs3.json.JsonFormat",
"path.format": "'year'=YYYY/'month'=MM/'day'=dd",
"confluent.topic.bootstrap.servers": "kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092"
}
}
8.4 Ejecución del Pipeline - API REST (Docker)¶
-
Enviamos las configuraciones al clúster de Connect (puedes atacar a cualquiera de los 3 workers, usaremos el
8083). -
Primero comprobamos los conectores activos, que no debería haber ninguno
-
Justo antes de iniciar los conectores, observa la ventana donde hemos usado Consumer API para observar como consume los datos de la Base de Datos.
-
Podemos observar los logs de los workers para verificar que no hay errores relacionados con la conexión a mysql o hdfs, y que han cargado correctamente los conectores.
# Con observer uno de ellos es suficiente, ya que forman un cluster y se reparten las tareas automáticamente. Pero puedes observar los 3 para ver como se reparten las tareas.
docker logs -f kafka-worker-1
docker logs -f kafka-worker-2
docker logs -f kafka-worker-3
- Antes de lanzar el conector, usamos Consumer API para observar como Kafka consume los registros de la Base de Datos.
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh --topic empleados-employees --from-beginning --bootstrap-server kafka-broker-1:9092
- Lanzamos el Conector Source:
# Desde el host, enviamos la configuración a través de la API REST
cd kafka_connect_plugins/config
curl -X POST -H "Content-Type: application/json" --data @mysql-employees-source-connector.json http://localhost:8083/connectors
- Verificación:
- Abre Kafbat UI (
http://kafka.localhost). Ve a la sección "Topics". Deberías ver que se ha creado automáticamente el topicempleados-employeesy que los mensajes están entrando rapidamente. - También puedes usar Consumer API para observar como Kafka consume los registros de la Base de Datos.
- Lanzamos el Conector Sink:
cd kafka_connect_plugins/config
curl -X POST -H "Content-Type: application/json" --data @hdfs3-employees-sink-connector.json http://localhost:8083/connectors
- Comprobamos que están activos
curl http://localhost:8083/connectors | jq
curl http://localhost:8083/connectors/mysql-employees-source-connector/status | jq
curl http://localhost:8083/connectors/hdfs3-employees-sink-connector/status | jq
8.5 Ejecución (Docker)¶
Si el Sink está funcionando correctamente, habrá empezado a agrupar los mensajes en bloques de 1000 (propiedad flush.size) y a enviarlos a HDFS.
Observa el video de la ejecución de nuestro ejemplo:
-
Iniciamos el primer conector, que accede a la base de datos. En ese momento, Consumer API muestra como procesa los datos Kafka.
-
Iniciamos el segundo conector, que accede a HDFS, transforma los datos en formato Avro y los almacena en el directorio indicado.
-
Podemos ver como son almacenados los datos en HDFS
9. Troubleshooting limitando recursos en Docker¶
Error Crítico al reducir el número de Brokers (Limitación de Recursos)
Si por limitaciones de CPU/RAM en tu máquina Host decides modificar el docker-compose.yml para levantar menos de 3 Brokers (por ejemplo, 1 o 2) en tus prácticas de kafka connect (es independiente del número de workers), es muy probable que te enfrentes a un error fatal en cadena.
Tus consumidores dejarán de leer y los workers de Kafka Connect se quedarán bloqueados en un bucle infinito mostrando el error:
Request timed out. The worker is currently ensuring membership in the cluster...
¿Por qué ocurre esto?
Por diseño. Apache Kafka está configurado para entornos de Alta Disponibilidad en producción. Al conectarse el primer grupo de consumidores (o Kafka Connect), el clúster intenta crear automáticamente los topics internos del sistema (como __consumer_offsets y los estados de transacciones) exigiendo un factor de replicación estricto de 3. Si el clúster detecta que solo hay 1 o 2 brokers registrados, la operación matemática falla, los topics internos no se crean, y Kafka deniega el servicio silenciosamente.
Solución:
Para que el clúster funcione con menos recursos, debemos ordenar a los Brokers que relajen sus reglas de seguridad. Debes añadir estas variables de entorno en la configuración de TODOS tus Brokers (kafka-broker-1, 2, etc.), ajustando el valor numérico a la cantidad total de brokers que tengas levantados (ejemplo para 2 brokers):
environment:
# ... (resto de tus variables KAFKA_...)
# --- AJUSTE PARA CLÚSTERES DE LABORATORIO (Ej: 2 Brokers) ---
# Ajusta el número al total de brokers reales en tu arquitectura
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 2
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 2
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2
Paso de limpieza obligatorio: Si ya intentaste levantar el clúster sin estas variables, Kafka habrá guardado el estado de error en el disco. Debes destruir los volúmenes para que levanten los volumenes limpios y así el clúster pueda arrancar correctamente con la nueva configuración. Para ello, ejecuta:
o bien si sólo quieres reiniciar los brokers:9.1 Docker compose completo teniendo en cuenta esta limitación¶
Si tienes este problema de limitación de recursos, aquí tienes un ejemplo completo de docker-compose.yml con las variables de entorno necesarias comentadas, para que puedas levantar un clúster de Kafka con 2 brokers y Kafka Connect sin que se bloquee.
Para ello, sólo tienes que descomentar las líneas relacionadas con KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR, KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR y KAFKA_TRANSACTION_STATE_LOG_MIN_ISR en la sección de cada broker, y ajustar el número al total de brokers reales puedas tener levantados (es decir, deja 1 broker con valor 1 o 2 brokers con valor 2), eliminando el resto de brokers para que no se levanten. Esto es independiente del número de workers que quieras levantar, que pueden seguir siendo 3 para asegurar la alta disponibilidad de los workers, o incluso 1 worker si quieres , si fuera motivado también por limitación de recursos
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- AJUSTE PARA CLÚSTERES DE LABORATORIO ---
# Para evitar bloqueos por falta de recursos, ajustamos la replica de los topics internos a 1 (si sólo tienes 1 broker) o 2 (si tienes 2 brokers).
# Ajusta el número al total de brokers reales en tu arquitectura (Ej: Si sólo tienes 1 broker, pon 1. Si tienes 2 brokers, pon 2. Si tienes 3 brokers, pon 2 o 3 según tus recursos).
# Descomenta estas líneas y ajusta el número según tu arquitectura para evitar bloqueos por falta de recursos en entornos de laboratorio.
# KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- AJUSTE PARA CLÚSTERES DE LABORATORIO ---
# Para evitar bloqueos por falta de recursos, ajustamos la replica de los topics internos a 1 (si sólo tienes 1 broker) o 2 (si tienes 2 brokers).
# Ajusta el número al total de brokers reales en tu arquitectura (Ej: Si sólo tienes 1 broker, pon 1. Si tienes 2 brokers, pon 2. Si tienes 3 brokers, pon 2 o 3 según tus recursos).
# Descomenta estas líneas y ajusta el número según tu arquitectura para evitar bloqueos por falta de recursos en entornos de laboratorio.
# KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- AJUSTE PARA CLÚSTERES DE LABORATORIO ---
# Para evitar bloqueos por falta de recursos, ajustamos la replica de los topics internos a 1 (si sólo tienes 1 broker) o 2 (si tienes 2 brokers).
# Ajusta el número al total de brokers reales en tu arquitectura (Ej: Si sólo tienes 1 broker, pon 1. Si tienes 2 brokers, pon 2. Si tienes 3 brokers, pon 2 o 3 según tus recursos).
# Descomenta estas líneas y ajusta el número según tu arquitectura para evitar bloqueos por falta de recursos en entornos de laboratorio.
# KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 2
# KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
# Le inyectamos el worker directamente. La UI lo auto-descubrirá.
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)