UD 4 - Apache Hadoop - Cluster Docker¶
En esta unidad se explica cómo desplegar un clúster de Apache Hadoop utilizando Docker y Docker Compose. Se proporcionan los pasos necesarios para configurar y ejecutar un clúster básico con HDFS y YARN, permitiendo a los estudiantes experimentar con un entorno de Big Data de manera sencilla y eficiente.
Hasta ahora has visto cómo montar Hadoop en máquinas virtuales, un proceso que simula fielmente la administración de servidores físicos ("Bare Metal"). Sin embargo, en el desarrollo moderno, necesitamos agilidad.
En esta sección, aprenderás a orquestar un clúster de Hadoop completo (HDFS + YARN) utilizando Docker Compose.
Pero primero vamos a realizar unas introducción teórica usando analogías claras y enfocada a la realidad profesional.
1. Virtualización vs. Contenerización:¶
Antes de tirar empezar necesitamos entender dónde estamos. Hasta ahora, en este curso (y probablemente en tu vida académica), has trabajado mucho con Máquinas Virtuales (VMs). Ahora vamos a dar el salto a Contenedores (Docker).
No es una moda; es una necesidad de supervivencia en el mundo del Big Data.
1.1 La Diferencia Arquitectónica¶
Para entender por qué Docker es el estándar, vamos a ver las diferencias usando una analogía arquitectónica.
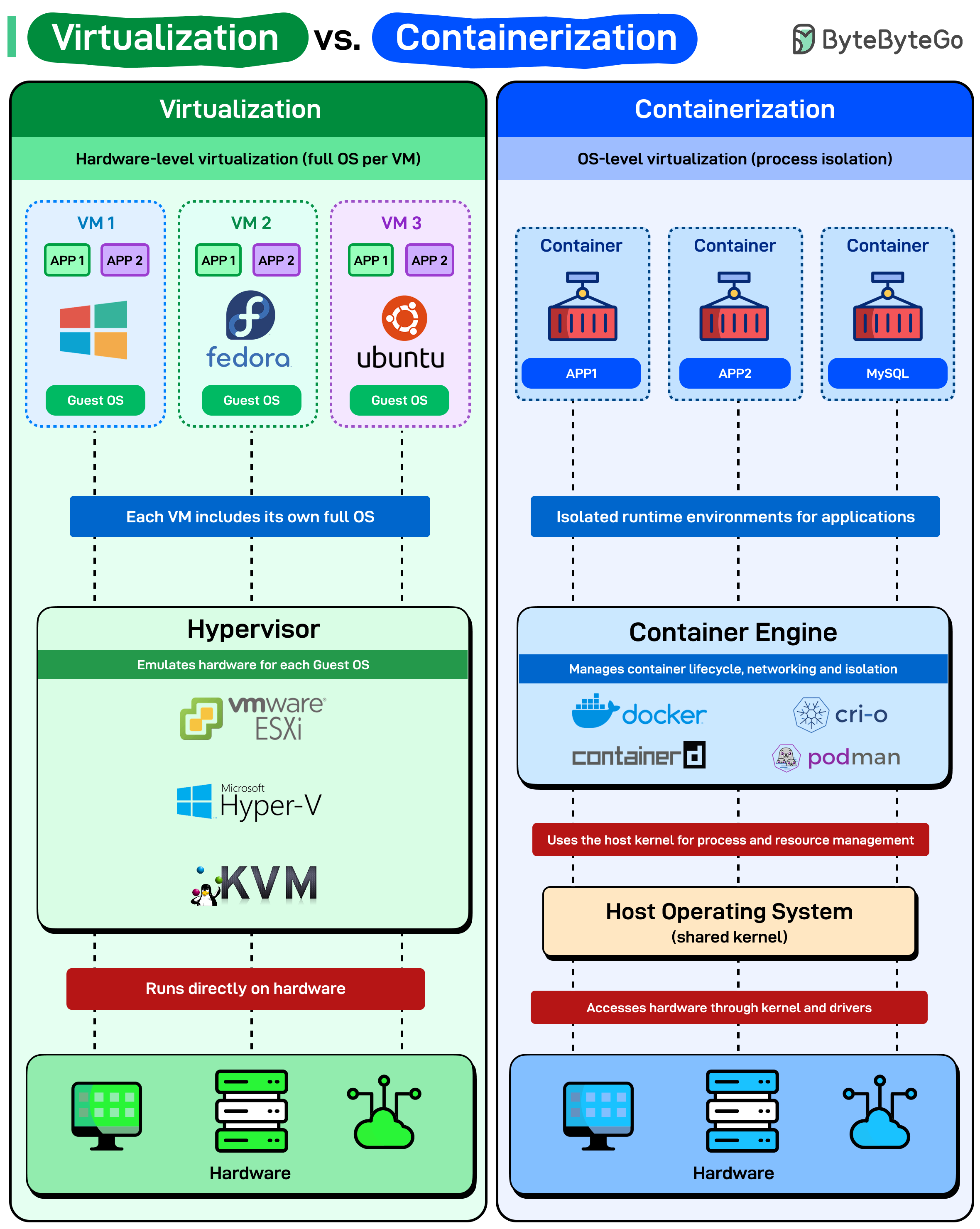
A. Virtualización¶
Imagina que quieres alojar a 3 familias (Aplicaciones).
- La Solución VM: Construyes 3 casas independientes.
- Cada casa tiene sus propios cimientos, su propio tejado, su propia caldera y su propia acometida de agua.
- Técnicamente: Tienes un Hipervisor (VirtualBox/VMware) que "engaña" al sistema operativo invitado. Cada VM carga su propio Kernel (Núcleo) completo, sus drivers de tarjeta gráfica, de sonido, de red... aunque no los necesite.
- Resultado: Muchos recursos. Mucho desperdicio.
B. Contenedores¶
Imagina las mismas 3 familias.
- La Solución Docker: Construyes un edificio de apartamentos.
- Hay un solo cimiento y una sola caldera central (El Kernel del Host). Cada familia tiene su apartamento privado (su espacio de usuario), pero comparten la infraestructura pesada del edificio.
- Técnicamente: El Docker Engine usa características del Kernel de Linux (Namespaces y Cgroups) para aislar procesos. Los contenedores comparten el Kernel de tu máquina.
- Resultado: Ligereza extrema.
Analogía Resumen
Una VM es como llevar tu casa entera a cuestas (muebles, paredes y tuberías) cada vez que te mudas. Un Contenedor es como llevar solo tu maleta de ropa a un hotel amueblado.
1.2 ¿Por qué el cambio? La "Tasa" de Recursos¶
En Big Data, los recursos (RAM y CPU) tienen coste. Necesitamos procesar datos, no mantener sistemas operativos zombies.
Observa esta comparativa de coste en recursos (overhead) para un clúster de 3 nodos (Hadoop):
| Característica | Máquinas Virtuales (VMs) | Contenedores (Docker) |
|---|---|---|
| Lo que ejecutas | 3 Kernels + 3 OS Completos + Hadoop | 1 Kernel (el tuyo) + Hadoop |
| Arranque | Minutos (Boot del OS) | Milisegundos (Arrancar proceso) |
| Tamaño en Disco | Gigabytes (GBs) por nodo | Megabytes (MBs) por capa |
| RAM Desperdiciada | ~1-2 GB solo para mantener los OS vivos | ~50 MB (Docker Engine overhead) |
El Impacto en tu Laboratorio: Si intentas levantar un clúster de Big Data (HDFS, YARN, Spark, Hive, Kafka) con VMs en tu portátil, consumiorá muchísismos recursos y probablemente se bloqueará o no podrá levantar todos los sistemas. Con Docker, puedes levantar 10-15 servicios simultáneamente con muchísimo menos coste en recursos.
1.3 La Realidad del Mercado Laboral (El "Porqué" Profesional)¶
¿Por qué aprendemos esto? No es solo para ahorrar RAM en tu portátil. Es porque así es como trabaja la industria hoy.
- "En mi local funcionaba": Esta es la frase más odiada por un Jefe de Proyecto. Con las VMs, tu entorno es ligeramente distinto al de producción. Con Docker, el contenedor que construyes en tu portátil es idéntico bit a bit al que se ejecuta en el servidor de producción. Garantizas la reproducibilidad.
- El Camino a Kubernetes: Docker es el ladrillo; Kubernetes (K8s) es el edificio. Hoy en día, las arquitecturas de Big Data modernas (Spark on K8s, Kafka on K8s) se despliegan sobre orquestadores de contenedores. Saber Docker es el prerrequisito obligatorio para acceder a puestos de Data Engineer o Site Reliability Engineer (SRE).
- CI/CD (Integración Continua): Las empresas despliegan código cientos de veces al día. Levantar una VM para testear tarda demasiado. Levantar un contenedor para testear es instantáneo.
2. Desplegando un Clúster Hadoop con Docker Compose¶
Una vez vista esta introducción, vamos a desplegar una arquitectura distribuida clásica, pero adaptada a la filosofía de Docker: "Un contenedor, un proceso".
Diagrama de Servicios¶
- Capa de Almacenamiento (HDFS):
- 1x NameNode: El cerebro. Gestiona los metadatos.
- 3x DataNodes: El músculo. Almacenan los bloques de datos.
- Capa de Procesamiento (YARN):
- 1x ResourceManager: El jefe de obra. Reparte recursos (RAM/CPU).
- 3x NodeManagers: Los obreros. Ejecutan las tareas.
Nota sobre Data Locality (Diferencia con Producción)
En un clúster físico real, buscamos la Localidad del Dato ( Data Locality): el DataNode y el NodeManager se instalan en la misma máquina física para procesar el dato donde está almacenado.
En este laboratorio educativo, hemos separado estos procesos en contenedores distintos (datanode1 es distinto de nodemanager1).
- Ventaja: Mejor observabilidad. Si falla el disco, cae el DataNode, pero el NodeManager sigue vivo. Facilita entender los logs por separado.
- Coste: Perdemos la optimización de red, pero en un entorno Docker local (Bridge Network), la latencia es despreciable.
3. Estructura del Proyecto¶
El orden es la mitad del éxito. Crea la siguiente estructura de directorios en tu espacio de trabajo:
miproyecto-bigdata/
├── docker-compose.yaml # El orquestador
└── hadoop.env # Variables de entorno para Hadoop
4. Configuración de Variables de Entorno¶
Crea el archivo hadoop.env con las siguientes variables:
# --- CONFIGURACIÓN DEL CORE (core-site.xml) ---
# Define el sistema de archivos por defecto
CORE-SITE.XML_fs.defaultFS=hdfs://namenode:9000
# Buffer size (opcional, buena práctica)
CORE-SITE.XML_io.file.buffer.size=131072
# --- CONFIGURACIÓN DE HDFS (hdfs-site.xml) ---
# Replicación a 1 (estamos en local con 1 disco físico real)
HDFS-SITE.XML_dfs.replication=1
# Rutas de datos (Coinciden con los volúmenes de Docker)
HDFS-SITE.XML_dfs.namenode.name.dir=file:///opt/hadoop/hadoop_data/hdfs/namenode
HDFS-SITE.XML_dfs.datanode.data.dir=file:///opt/hadoop/hadoop_data/hdfs/datanode
# Checkpoint dir para el Secondary
HDFS-SITE.XML_dfs.namenode.checkpoint.dir=file:///opt/hadoop/hadoop_data/hdfs/secondary_namenode
# WebHDFS (necesario para algunas operaciones REST)
HDFS-SITE.XML_dfs.webhdfs.enabled=true
# Permisos (Descomenta para desactivar comprobación estricta para laboratorio. Nunca en producción)
#HDFS-SITE.XML_dfs.permissions.enabled=false
# --- CONFIGURACIÓN DE YARN (yarn-site.xml) ---
# Hostname del ResourceManager
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
# Habilitar Shuffle para MapReduce
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
YARN-SITE.XML_yarn.nodemanager.aux-services.mapreduce_shuffle.class=org.apache.hadoop.mapred.ShuffleHandler
# UI Moderna y Logs
YARN-SITE.XML_yarn.webapp.ui2.enable=true
YARN-SITE.XML_yarn.log-aggregation-enable=true
# Scheduler
YARN-SITE.XML_yarn.scheduler.capacity.root.queues=default
YARN-SITE.XML_yarn.scheduler.capacity.root.default.capacity=100
YARN-SITE.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1.0
# Memoria (Límites físicos para evitar que YARN mate contenedores por error en Lab)
YARN-SITE.XML_yarn.nodemanager.resource.memory-mb=4096
YARN-SITE.XML_yarn.scheduler.minimum-allocation-mb=512
YARN-SITE.XML_yarn.scheduler.maximum-allocation-mb=4096
# IMPORTANTE: Desactivar chequeo de memoria física virtual (evita fallos en Docker Desktop)
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false
# --- CONFIGURACIÓN DE MAPREDUCE (mapred-site.xml) ---
MAPRED-SITE.XML_mapreduce.framework.name=yarn
MAPRED-SITE.XML_mapreduce.application.classpath=/opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
Bug de Persistencia de la imagen oficial de Hadoop de Docker Hub
Es posible que en tutoriales de internet veas que usan la variable ENSURE_NAMENODE_DIR en el docker-compose. Nosotros la hemos eliminado deliberadamente y sustituido por un comando manual propio.
¿Por qué?
Existe un bug documentado en la imagen oficial de Hadoop (Ticket HDFS-17307).
- El Error: Al reiniciar el contenedor, el script oficial a veces detecta erróneamente que el disco está "sucio" y decide formatearlo de nuevo.
- La Consecuencia: El NameNode cambia su
ClusterID. Los DataNodes (que tienen el ID antiguo) rechazan conectarse y se apagan. - Nuestra Solución: Hemos inyectado nuestra propia lógica en el
commanddel NameNode:if [ ! -d .../current ]. Esto garantiza que solo se formatee si la carpetacurrentno existe. - Referencia: HDFS-17307
Si en el futuro usamos una versión de Hadoop superior a la 3.4.1 (ej. 3.5.0+), deberíamos probar si han arreglado el script oficial eliminando nuestro comando manual y reactivando la variable ENSURE_NAMENODE_DIR (que dejo comentada en el docker-compose). Sólo habría que:
- Comentar:
- command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
- Descomentar:
- environment:
- ENSURE_NAMENODE_DIR=/opt/hadoop/hadoop_data/hdfs/namenode
Mientras tanto, nuestro método es el más seguro.
5. El Orquestador: Docker Compose¶
Este archivo define toda nuestra infraestructura.
Crea el archivo docker-compose.yaml:
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
services:
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
6. Resolución de Nombres (DNS Local)¶
Para acceder a los servicios cómodamente desde tu navegador y para que los enlaces internos de Hadoop funcionen, necesitamos resolver los nombres desde tu maquina anfitrión para poder usar los alias definidos en Docker Compose.
Tenemos dos estrategias para solucionar esto.
6.1 Opción 1: El Método Clásico (/etc/hosts)¶
Añadimos al sistema operativo de tu ordenador para que resuelva los nombres de los contenedores a tu propia máquina (127.0.0.1).
Ventajas:
- No requiere contenedores extra.
- Funciona siempre.
Desventajas:
- Es manual y tedioso.
- Requiere permisos de administrador.
Instrucciones:
Edita tu archivo de hosts (Linux/Mac: /etc/hosts, Windows: C:\Windows\System32\drivers\etc\hosts) y añade:
127.0.0.1 cluster-bda namenode resourcemanager
127.0.0.1 datanode1 datanode2 datanode3
127.0.0.1 nodemanager1 nodemanager2 nodemanager3
6.2 Opción 2: Buenas prácticas de DevOps (Traefik & Portainer)¶
Para un entorno más profesional y escalable, usaremos un Reverse Proxy llamado Traefik junto con Portainer para gestionar nuestros contenedores.
-
Traefik: Es un proxy inverso y balanceador de carga moderno diseñado para entornos de computación en la nube y microservicios, que actúa como un router de borde (edge router) para gestionar el tráfico entrante hacia servicios internos. Se integra nativamente con tecnologías como Docker, Kubernetes, Docker Swarm, AWS, Mesos y otras plataformas de orquestación, permitiendo una configuración automática y dinámica basada en el descubrimiento de servicios
-
Portainer: Es una herramienta de código abierto y una interfaz gráfica web que permite gestionar entornos de contenedores Docker, Kubernetes y Docker Swarm de forma sencilla y eficiente. Se trata de una plataforma de gestión de contenedores autohospedada, potente y ligera, que facilita la administración de contenedores, imágenes, volúmenes, redes y clústeres desde una interfaz intuitiva accesible desde cualquier navegador
Ventajas:
- Cero Configuración en el Host: No necesitas editar archivos del sistema operativo.
- Escalabilidad: Añadir nuevos servicios es tan simple como definirlos en Docker Compose con las etiquetas adecuadas.
- Dashboard Visual: Portainer te permite ver y gestionar tus contenedores fácilmente.
Dominio .localhost
Cuando usamos Traefik, necesitamos establecer un dominio para nuestros servicios. Usaremos el dominio especial .localhost (ej: namenode.localhost).
Esta configuración está en el Estándar de Internet RFC 6761. Este documento define que el dominio de nivel superior .localhost está reservado para uso de "bucle local" (loopback).
¿Qué significa esto para ti?
- Resolución Automática: Tu Sistema Operativo (Windows, macOS o Linux) está programado para detectar cualquier dirección que termine en
.localhoste interceptarla inmediatamente. - Redirección Interna: El sistema operativo traduce automáticamente ese nombre a
127.0.0.1(tu propia máquina) sin salir a internet y sin preguntar a servidores DNS externos. - Ventaja "Zero Config": Gracias a este comportamiento estándar, podemos inventar subdominios infinitos (
kafka.localhost,spark.localhost) y funcionarán al instante sin tener que editar el archivo hosts.
Actualización del docker-compose.yml¶
Añadiremos los servicios de infraestructura (traefik y portainer) y configuraremos las etiquetas (labels) en los servicios de Hadoop. Las etiquetas son la forma en que le decimos a Traefik: "Oye, si alguien pregunta por este nombre, mándamelo a mí".
Copia y actualiza tu fichero con esta configuración:
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data: # Nuevo volumen
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR=/opt/hadoop/hadoop_data/hdfs/namenode
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
command: ["hdfs", "namenode"]
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
7. Despliegue y Verificación¶
- Arrancamos el clúster:
- Verificamos contenedores:
Ejecuta docker compose ps. Deberías ver todos los servicios en estado Up (o healthy).
- Verificamos el acceso
Una vez reinicies tu stack (docker-compose up -d), abre tu navegador y prueba estas URLs limpias:
- HDFS NameNode: http://namenode.localhost
- YARN ResourceManager: http://yarn.localhost
- Portainer: http://portainer.localhost (Te pedirá crear usuario/pass la primera vez).
- Panel de Traefik: http://localhost:8089 (Aquí verás todos los routers detectados automáticamente).
- Prueba Funcional HDFS:
Vamos a crear un directorio en HDFS desde la línea de comandos.
# Entra al contenedor del namenode
docker exec -it namenode bash
# Lista la raíz (debería estar vacío o con temporales)
hdfs dfs -ls /
# Crea una carpeta
hdfs dfs -mkdir -p /user/bda/prueba
# Verifica la creación de la carpeta
hdfs dfs -ls /user/bda/
Apaga todas las máquinas y vuelve a encenderlas para verificar persistencia:
Vuelve a listar:
# Entra al contenedor del namenode
docker exec -it namenode bash
# Comprueba que la carpeta sigue ahí
hdfs dfs -ls /user/bda/
- Prueba Funcional YARN
Vamos a ejecutar el ejemplo clásico del cálculo de Pi.
# Entra al contenedor del namenode
docker exec -it namenode bash
# Ejecuta el job de ejemplo para calcular Pi
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 15
Comprueba que el job se ejecuta correctamente y revisa la interfaz web de YARN para ver el estado del job.
- Actividades
Ya puedes realizar las actividades hechas en los puntos anteriores en el laboratorio usando este clúster Hadoop hecho con Docker.