UD 6 - Apache Spark - Cluster Docker + Spark¶
En este bloque desplegaremos un clúster Apache Spark 4.x.x en modo Standalone sobre nuestra infraestructura de contenedores.
Buscamos un desacoplamiento total: Spark se encargará del cómputo en memoria y HDFS de la persistencia, sin intermediarios.
1. Selección de la Imagen Docker¶
Para este despliegue, hemos tomado decisiones arquitectónicas basadas en las recomendaciones oficiales del proyecto.
1.1. Fuente Oficial vs. Upstream¶
Existen dos imágenes principales para Spark:
apache/spark(Mantenida por el proyecto Apache).spark(Imagen Oficial de Docker Library).
Nuestra Elección: Usaremos la imagen oficial spark (spark:4.0.1).
Motivos de la Elección
Justificación Oficial: En el repositorio oficial de GitHub, los mantenedores indican explícitamente: "We recommend using Spark Docker Official Image (https://hub.docker.com/_/spark), the Apache Spark Image (https://hub.docker.com/r/apache/spark) are provided in case of delays in the review process by Docker community."
Elegimos la imagen oficial porque pasa por procesos de revisión de seguridad y estandarización más rigurosos por parte de la comunidad de Docker.
1.2. Diseño "Kubernetes First" y el Entrypoint¶
Es crucial entender que esta imagen está diseñada nativamente para Kubernetes.
Si analizamos el script de arranque (entrypoint.sh) de la imagen:
Note
Variables de entorno con kubernetes(k8s): Si usamos kubernetes, si podremos usar las correspondientes variables de entorno. Si quieres probar spark con Kubernetes, sigue la documentación oficial de Spark para desplegar en K8s.
- Tiene lógica específica para arrancar como
driveroexecutor(conceptos de K8s). - NO tiene lógica interna para procesar variables de entorno como
SPARK_MODE=master(típicas de imágenes de Bitnami). - Funciona en modo "Pass-through": Si el comando no es de K8s, simplemente ejecuta literalmente lo que le pasemos.
Consecuencia para Docker Compose
Debido a este diseño, no podemos confiar en variables de entorno para arrancar el servicio. Debemos definir el comando de arranque explícitamente en nuestro docker-compose.yml, invocando directamente los binarios de Java (spark-class).
2. Implementación en Docker Compose¶
Añade los siguientes servicios a tu archivo docker-compose.yml.
2.1 Configuración del Master¶
El Master expone el puerto 7077 para recibir trabajos (spark-submit) y coordinar a los workers. Su interfaz web (puerto 8080 interno) será accesible a través de Traefik.
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- "8080:8080" # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
2.2 Configuración de los Workers¶
Desplegamos 3 workers. Es fundamental limitar su memoria mediante variables nativas de Spark (SPARK_WORKER_MEMORY) para no saturar el host. También es posible limitar CPU con SPARK_WORKER_CORES.
Configuración de los Workers y Gestión de Recursos
Aquí utilizaremos variables de entorno para limitar la CPU y RAM.
¿Por qué funcionan estas variables?¶
Puede parecer contradictorio: acabamos de decir que la imagen ignora variables como SPARK_MODE, pero ahora usamos SPARK_WORKER_MEMORY. ¿Por qué esta sí funciona?
- Variables de la Imagen (Ignoradas): Variables inventadas por creadores de imágenes (ej:
SPARK_MODE) para controlar el scriptentrypoint.sh. Como usamos la imagen oficial, estas no existen. - Variables Nativas de Spark (Funcionan): Variables como
SPARK_WORKER_MEMORYoSPARK_WORKER_CORESson leídas internamente por los scripts binarios de Spark (/opt/spark/bin/spark-class) cuando la Máquina Virtual de Java (JVM) arranca.
Al definir estas variables en el docker-compose.yml, se inyectan en el entorno del contenedor y el proceso Java de Spark las consume directamente para autoconfigurarse.
📚 Referencia Oficial: Puedes consultar la lista completa de variables nativas soportadas por los demonios de Spark en la documentación oficial de Apache: Spark Standalone Mode - Environment Variables
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
environment:
- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
environment:
- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
2.3 Configuración de Spark Connect¶
Añadimos un nuevo servicio al docker-compose.yml dedicado exclusivamente para Spark Connect, que será la puerta de enlace para clientes remotos (IDEs, Notebooks). Este servicio:
- Arrancará como un cliente del clúster (se conectará al Master 7077).
- Expondrá el puerto 15002 hacia tu host.
- Expondrá su propia Web UI del Driver en el puerto 4040 para la monitorización de los jobs enviados desde clientes remotos.
- Tendrá acceso a la configuración de HDFS (para que tus queries remotas lean datos reales).
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
Cómo funciona Spark Connect
- Una vez levantado con
docker-compose up -d, este contenedor lanza unspark-submit. - Ese submit inicia un Driver que se queda escuchando permanentemente en el puerto 15002.
-
Desde tu portátil (Host), ejecutas tu script Python:
-
Nuestro script manda la query al puerto
15002-> Llega al contenedorspark-connect-> Este reparte el trabajo a losspark-workers-> Los workers leen de HDFS -> El resultado vuelve a nuestra pantalla.
Justificación del Servicio Adicional¶
Podrías preguntarte: "¿Por qué no le añadimos esa funcionalidad al Master y ahorramos un contenedor?".
El motivo es Porque el Spark Master y el Spark Connect Server son dos programas Java distintos y excluyentes:
En Docker, un contenedor ejecuta un solo proceso principal (PID 1).
-
El proceso del Master: Ejecuta la clase
org.apache.spark.deploy.master.Master:a. Su trabajo es escuchar en el puerto 7077. b. Solo sabe gestionar recursos (decirle a los workers: "dale 2 CPU a este tipo"). c. NO sabe ejecutar código SQL, ni Python, ni DataFrames.
-
El proceso de Spark Connect: Ejecuta la clase
org.apache.spark.sql.connect.service.SparkConnectServer:a. Este proceso actúa como un Driver (una aplicación Spark). b. Necesita conectarse a un Master (en el 7077) para pedirle recursos. c. Mantiene la sesión de usuario, optimiza el plan lógico y coordina la ejecución.
¿Qué pasa si intentas juntarlos?
En el docker-compose.yml, en la línea command:, tienes que elegir UNA clase para arrancar.
- Si arrancas el
Master, no tienes Spark Connect (nadie escucha en el 15002). - Si arrancas el
SparkConnectServer, no tienes Master (nadie escucha en el 7077), por lo que el Connect Server no tendría a quién pedirle workers y fallaría (o tendría que correr en modolocal, ignorando a tus workers).
Note
Podríamos hacer "trampas" usando scripts tipo supervisord para arrancar dos procesos Java en el mismo contenedor, pero eso es un "anti-patrón" sucio en Docker que hace que los logs se mezclen y el manejo de errores no sea adecuado.
2.4 Spark Connect y la gestión de Recursos¶
Puede darse el caso, que al intentar ejecutar un trabajo, mientras el servicio Spark Connect está activo, es posible que te encuentres con que el trabajo nunca arranca y el terminal muestra repetidamente este mensaje:
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2.4.1 Causa del problema¶
Por defecto, el gestor de clúster Standalone de Spark es "codicioso" (greedy). Cuando una aplicación se conecta (en este caso, el servicio spark-connect que arranca automáticamente con Docker), intenta reservar TODOS los núcleos de CPU disponibles en todos los Workers.
Como spark-connect llega primero, acapara el 100% del clúster. Cuando intentas lanzar un script, se queda en cola esperando recursos que nunca se liberan.
Por tanto, si no tienes suficientes recursos disponibles para tener a la vez los workwers y el servicio spark-connect, debemos limitar los recursos de este último.
2.4.2 Solución: Limitar el apetito de Spark Connect¶
Para permitir la concurrencia (que varios trabajos se ejecuten a la vez), debemos limitar explícitamente cuántos recursos puede consumir el servicio residente spark-connect.
Modifica la sección command del servicio spark-connect en tu docker-compose.yml para añadir límites estrictos de Cores y Memoria:
spark-connect:
# ... (resto de configuración igual) ...
# COMANDO: Lanza el servidor con límites de recursos
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
Comenta o descomenta en función de los recursos de tu máquina host.
Verificación
Tras aplicar este cambio y reiniciar (docker-compose up -d --force-recreate), accede a la Web UI del Master (http://spark.localhost). Verás que la aplicación SparkConnectServer ahora solo consume 1 Core, dejando el resto libres para que puedas ejecutar scripts simultáneamente.
2.5 Declaración de Volúmenes¶
No olvides declarar los volúmenes para los logs de Spark:
volumes:
# ... otros volúmenes ...
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
2.6 Stack completo del docker compose¶
Nuestro archivo docker-compose.yml debería tener ahora los servicios de HDFS (Namenode, Datanode), Traefik y Spark (Master, Workers, Connect) correctamente configurados.
Comentamos Hive Metastore y la limitación de recursos de spark-connect
- Comentamos los servicios de Hive ya que no son necesarios en nuestro stack con la configuración elegida con Spark
- Comentamos las líneas de limitación de recursos en spark-connect para facilitar su uso en máquinas con pocos recursos. Asegúrate de descomentarlas si tienes problemas de recursos.
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
postgres:
image: postgres:18
container_name: postgres
networks:
- bda-network
environment:
POSTGRES_DB: metastore_db
POSTGRES_USER: hive
POSTGRES_PASSWORD: hive_password
# Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- postgres_data:/var/lib/postgresql/data
# healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
healthcheck:
test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
interval: 10s
timeout: 5s
retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
metastore:
image: apache/hive:standalone-metastore-4.2.0
container_name: metastore
networks:
- bda-network
environment:
SERVICE_NAME: metastore
# Credenciales explícitas para el script de inicio de la imagen
DB_DRIVER: postgres
# Configuración JAVA directa (Sin XMLs intermedios para la DB)
SERVICE_OPTS: >-
-Xmx1G
-Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
-Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
-Djavax.jdo.option.ConnectionUserName=hive
-Djavax.jdo.option.ConnectionPassword=hive_password
-Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
-Dfs.defaultFS=hdfs://namenode:9000
depends_on:
postgres:
# Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
condition: service_healthy
namenode:
condition: service_started
ports:
- "9083:9083" # Puerto Thrift expuesto para clientes externos
volumes:
# Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
- ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
- ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
- ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
hiveserver2:
image: apache/hive:4.2.0
container_name: hiveserver2
networks:
- bda-network
environment:
SERVICE_NAME: hiveserver2
TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# Evita re-inicializar el esquema (ya lo hace el metastore)
IS_RESUME: "true"
# Configuración: Conéctate al metastore remoto y usa HDFS
SERVICE_OPTS: >-
-Dhive.metastore.uris=thrift://metastore:9083
-Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
-Dfs.defaultFS=hdfs://namenode:9000
depends_on:
metastore:
condition: service_started
resourcemanager:
condition: service_started
ports:
- "10000:10000" # Puerto JDBC (Beeline/DBeaver)
- "10002:10002" # Web UI de HiveServer2
labels:
- "traefik.enable=true"
# Acceso HTTP a la UI de Hive
- "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
- "traefik.http.services.hive.loadbalancer.server.port=10002"
- "traefik.http.routers.hive.entrypoints=web"
# Desactivando el paso de la cabecera Host (passHostHeader = false).
# Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
- "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
environment:
- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
environment:
- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
#- "--conf"
#- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
#- "--conf"
#- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1"
3. Despliegue y Verificación¶
-
Arrancar el Clúster:
-
Acceso a la Web UI:
Abrimos http://spark.localhost. Deberíamos ver el Spark Master UI con 3 Workers en estado ALIVE.
-
Logs:
Si algún worker falla, revisa los logs:
docker logs spark-masterdocker logs spark-worker-1docker logs spark-worker-2docker logs spark-worker-3
Deberíamos ver:
Successfully registered with master spark://spark-master:7077.
4. Shells Interactivos¶
Si queremos probar comandos interactivos de python y/o escala en Spark con nuestra configuración de docker compose, hacemos los siguiente:
Iniciamos
....
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 4.0.1
/_/
Using Scala version 2.13.16 (OpenJDK 64-Bit Server VM, Java 17.0.17)
Type in expressions to have them evaluated.
Type :help for more information.
26/01/22 11:08:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://spark-master:4040
Spark context available as 'sc' (master = local[*], app id = local-1769080091588).
Spark session available as 'spark'.
scala>
Ejecutamos los comandos que queramos
Para salir
....
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
26/01/22 11:09:48 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 4.0.1
/_/
Using Python version 3.10.12 (main, Jan 8 2026 06:52:19)
Spark context Web UI available at http://spark-master:4040
Spark context available as 'sc' (master = local[*], app id = local-1769080188862).
SparkSession available as 'spark'.
>>>
Para salir
5. Ejemplo 1: Cálculo de Pi¶
Para probar que el clúster procesa tareas (CPU/RAM), lanzaremos el cálculo del número Pi usando el ejemplo incluido en la imagen.
docker exec -it spark-master /opt/spark/bin/spark-submit \
--master spark://spark-master:7077 \
--class org.apache.spark.examples.SparkPi \
/opt/spark/examples/jars/spark-examples_2.13-4.0.1.jar 10
Resultado esperado: Logs de ejecución y al final Pi is roughly 3.141....
Si no lo ves entre tanta información de logs, ejecútalo usando grep:
docker exec -it spark-master /opt/spark/bin/spark-submit \
--master spark://spark-master:7077 \
--class org.apache.spark.examples.SparkPi \
/opt/spark/examples/jars/spark-examples_2.13-4.0.1.jar 10 2>&1 | grep "Pi is"
6. Ejemplo 2: Integración con HDFS (Storage)¶
Verificaremos que Spark puede leer y escribir en nuestro sistema de archivos distribuido HDFS. Realizaremos un conteo de palabras sobre el texto de "El Quijote".
6.1 Paso A: Preparar datos en HDFS¶
Como Spark leerá de HDFS, primero debemos subir el archivo usando el contenedor namenode.
- Descargar fichero en local:
mkdir -p datos_origen
cd datos_origen
wget https://gist.githubusercontent.com/jaimerabasco/cb528c32b4c4092e6a0763d8b6bc25c0/raw/54b30a89f3b608d0837bd1fc10bc31e64ba4c7c8/El_Quijote.txt
- Subir a HDFS:
# Copiar al contenedor namenode
docker cp El_Quijote.txt namenode:/tmp/
# Crear directorio y subir (Comandos HDFS)
docker exec namenode hdfs dfs -mkdir -p /bda/spark/ejemplos
docker exec namenode hdfs dfs -put /tmp/El_Quijote.txt /bda/spark/ejemplos/
6.2 Paso B: Script PySpark¶
Crea un archivo llamado wordcount.py en tu directorio local.
Nota: Usamos la URI completa hdfs://namenode:9000 para ser explícitos y evitar ambigüedades con el sistema de ficheros local.
from pyspark.sql import SparkSession
if __name__ == "__main__":
# Inicializar sesión
spark = SparkSession.builder.appName("HDFS_WordCount").getOrCreate()
# 1. Leer de HDFS
input_file = "hdfs://namenode:9000/bda/spark/ejemplos/El_Quijote.txt"
print(f"--- Leyendo de: {input_file} ---")
df = spark.read.text(input_file)
# 2. Transformación: Contar líneas que contienen "Sancho"
sancho_lines = df.filter(df.value.contains("Sancho"))
count = sancho_lines.count()
print(f"--- Líneas con 'Sancho': {count} ---")
# 3. Escribir resultado en HDFS (CSV)
output_path = "hdfs://namenode:9000/bda/spark/ejemplos/salida_sancho"
print(f"--- Escribiendo en: {output_path} ---")
sancho_lines.write.mode("overwrite").csv(output_path)
spark.stop()
6.3 Paso C: Ejecución¶
- Copia el script al Master:
docker exec spark-master mkdir -p /opt/spark/ejemplos
docker cp wordcount.py spark-master:/opt/spark/ejemplos/
- Lanza el trabajo (
spark-submit):
docker exec -it spark-master /opt/spark/bin/spark-submit \
--master spark://spark-master:7077 \
--deploy-mode client \
/opt/spark/ejemplos/wordcount.py
6.4 Paso D: Verificación de Resultados¶
Comprueba que Spark ha escrito los ficheros en HDFS:
docker exec namenode hdfs dfs -ls /bda/spark/ejemplos/salida_sancho
# Leer el contenido del resultado
docker exec namenode hdfs dfs -cat /bda/spark/ejemplos/salida_sancho/part-00000*.csv | head
Si ves las líneas de texto extraídas, la integración Spark <-> HDFS es un éxito.
7. Ejemplo 3: Desarrollo Remoto con VS Code y Spark Connect¶
Ejecutaremos código Python en nuestro ordenador (Host), pero el procesamiento ocurrirá dentro del clúster Docker.
7.1 Requisitos previos (En Host)¶
En tu máquina local (Windows/Mac/Linux), solo necesitas Python. No hace falta Java ni Hadoop. Si no lo hiciste en el ejemplo anterior, crea un entorno virtual para aislar las librerías.
- Crea una carpeta para el proyecto en tu ordenador:
- Crea un entorno virtual y activa las librerías de cliente:
python -m venv venv
source venv/bin/activate # O venv\Scripts\activate en Windows
pip install pyspark-connect grpcio-status
7.2 Preparación de Datos (En Docker)¶
Si no lo hiciste en el ejemplo anterior, sube los datos a HDFS.
# Descargar (Host)
wget https://gist.githubusercontent.com/jaimerabasco/cb528c32b4c4092e6a0763d8b6bc25c0/raw/54b30a89f3b608d0837bd1fc10bc31e64ba4c7c8/El_Quijote.txt
docker cp El_Quijote.txt namenode:/tmp/
# Subir a HDFS (Contenedor)
docker exec namenode hdfs dfs -mkdir -p /bda/spark/ejemplos
docker exec namenode hdfs dfs -put /tmp/El_Quijote.txt /bda/spark/ejemplos/
7.3 El Script en VS Code¶
Crea un archivo remote_wordcount.py en tu VS Code.
Puntos clave:
- Conectamos a
sc://localhost:15002(el puerto expuesto por el contenedorspark-connect). - Leemos de
hdfs://namenode:9000(la dirección interna de Docker).
from pyspark.sql import SparkSession
# Conectamos al servicio Spark Connect (Puerto 15002 expuesto en Docker)
spark = SparkSession.builder.remote("sc://localhost:15002").getOrCreate()
print("--- Conectado a Spark Cluster versión: ", spark.version)
# Leemos de HDFS (Ruta interna del clúster Docker)
input_path = "hdfs://namenode:9000/bda/spark/ejemplos/El_Quijote.txt"
print(f"--- Procesando archivo: {input_path}")
try:
df = spark.read.text(input_path)
# Transformación: Contar líneas con "Sancho"
count = df.filter(df.value.contains("Sancho")).count()
print(f"Resultado: Sancho aparece en {count} líneas.")
# Escritura en HDFS
output_path = "hdfs://namenode:9000/bda/spark/ejemplos/salida_sancho_remote"
print(f"--- Escribiendo en: {output_path}")
df.filter(df.value.contains("Sancho")).write.mode("overwrite").csv(output_path)
except Exception as e:
print("ERROR:", e)
spark.stop()
7.4 Ejecución desde el Host¶
Opción A: Desde la Terminal (Recomendada)¶
Es la forma más directa y te asegura ver todos los logs sin depender de configuraciones del editor. Asegúrate de tener tu entorno virtual activado.
Opción B: Desde VS Code (Botón Play)¶
Si prefieres ejecutarlo directamente desde el editor:
- Instala la extensión Python (de Microsoft) en VS Code.
- Abre el archivo
remote_wordcount.py. - Abajo a la derecha, asegúrate de seleccionar el Intérprete de Python que está dentro de tu carpeta
venv(VS Code te preguntará o puedes hacer click para cambiarlo). - Pulsa el botón ▷ (Play).
7.5 Monitorización¶
Si vas a la UI del Master (http://spark.localhost), NO verás tu aplicación. Esto es debido a que tu script no es una aplicación nueva; es un cliente enviando comandos al servidor SparkConnectServer que ya está ejecutándose. Lo explicamos a continuación.
Es un comportamiento normal debido a la arquitectura de Spark Connect. La razón por la que no ves una "nueva aplicación" en la Web UI del Master (puerto 8080) cada vez que ejecutas tu script es la siguiente:
-
El Servidor es la Aplicación, no tu Script. Cuando utilizamos Spark Connect, el flujo es distinto al de un
spark-submittradicional. Spark Connect Server es un proceso persistente que hemos "levantado" previamente gracias astart-connect-server.sh). -
Tu cliente (Python): Al usar
.remote("sc://..."), nuestro script no envía la aplicación entera al cluster. Solo envía "instrucciones" (planes lógicos) al servidor de Spark Connect. El servidor recibe esas instrucciones y las ejecuta dentro de su propia sesión de Spark ya existente.
Dónde ver la ejecución de los trabajos (Jobs)¶
Aunque no aparezca como una aplicación nueva en el puerto 8080, sí puedes ver los Jobs, Stages y tareas de tu script, pero no en el Master, sino en la UI del Driver del Servidor:
- Puerto 4040: Por defecto, el servidor de Spark Connect levanta su propia interfaz de monitorización en el puerto 4040 (o 4041, 4042 si el 4040 estaba ocupado) de la máquina donde iniciaste el servicio
Traefik y la UI del Driver¶
Gracias a nuestra configuración de Traefik, puedes ver la UI específica del Driver de Spark Connect en:
👉 http://spark-connect.localhost
Ahí verás los Jobs y Stages generados por tu script de Python en tiempo real.
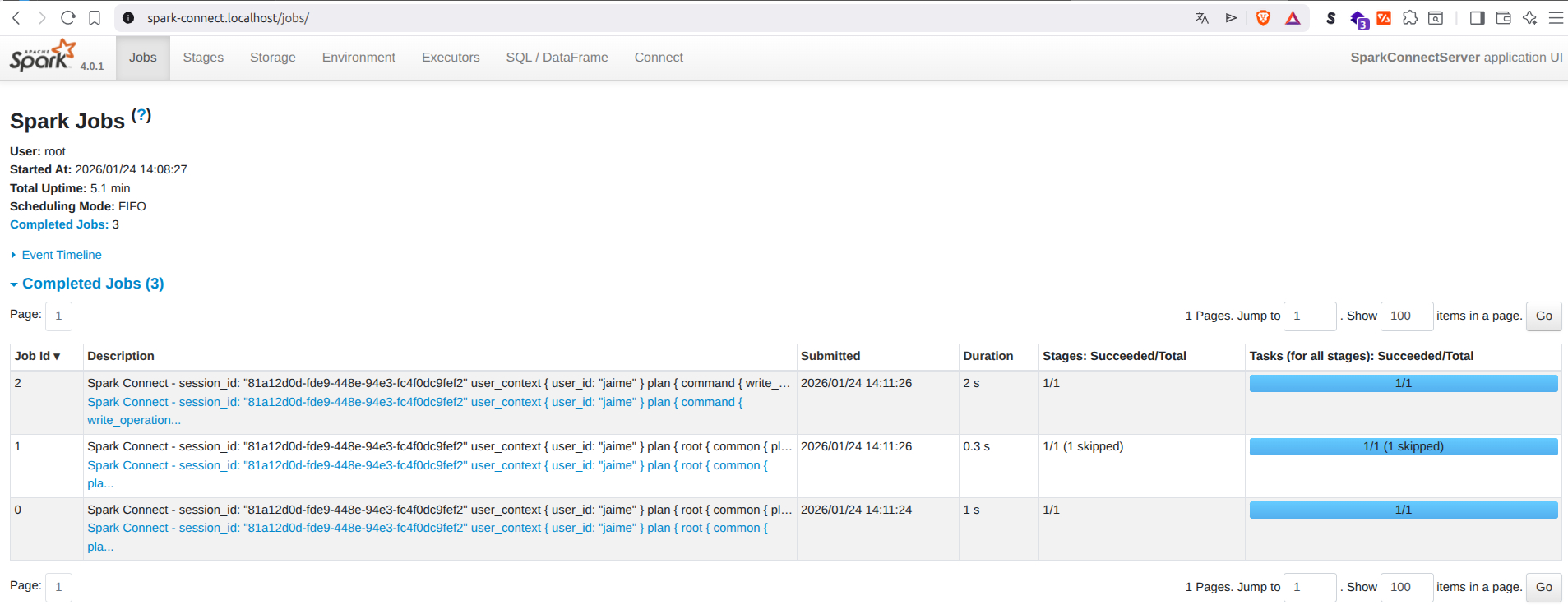
Recuerda que también puedes verlo desde loclahost accediendo al puerto 4040 si no usas Traefik: (http://localhost:4040).

Diferencias clave para tu flujo de trabajo¶
-
Si usas Spark Connect: El cluster se comporta como una base de datos a la que te conectas. La "app" es el servidor y siempre está encendida. Es ideal para notebooks e IDEs.
-
Si quieres ver una App independiente: Deberías ejecutar tu código usando
spark-submitdesde la consola del cluster o configurar tu script para usar un Master directo (.master("spark://spark-master:7077"), como hemos hecho anteriormente en el ejemplo 1) en lugar de.remote().
7.6 Verificación Final¶
Comprueba que el fichero se ha escrito en HDFS desde fuera:
Deberíamos ver los archivos _SUCCESS y part-.... Si es así, hemos logrado completar el ciclo de desarrollo remoto.
8. Resumen de la Arquitectura¶
Con esto has montado un entorno de Data Engineering completo:
- HDFS: Almacenamiento distribuido.
- Spark Master/Workers: Potencia de cálculo.
- Spark Connect: Puerta de enlace para desarrollo ágil desde el Host.
- Traefik: Acceso sencillo a todas las UIs (
spark.localhost,spark-connect.localhost).