UD 8 - Monitor Apache Spark¶
1. Integración Nativa con Prometheus¶
En el apartado anterior, aprendimos a monitorizar Kafka utilizando un agente externo (JMX Exporter) porque su arquitectura original no integra la compatibilidad con Prometheus.
Sin embargo, Spark es diferente. Desde la versión 3.0, Spark tiene una integración nativa con Prometheus, lo que significa que no necesitamos ningún agente externo para exponer sus métricas a Prometheus. Esto simplifica enormemente el proceso de monitorización y nos permite obtener métricas detalladas sobre el rendimiento de nuestras aplicaciones Spark de manera más eficiente.
Métricas de Clúster vs. Métricas de Aplicación
Es importante entender qué vamos a monitorizar:
- Métricas del Clúster (Lo que haremos aquí): Monitorizamos la salud del Master y los Workers (Memoria usada, Cores libres, Workers vivos). Siempre están disponibles mientras los contenedores estén encendidos.
- Métricas de Aplicación: Monitorizan un Job específico (Stages, Tasks, Shuffle Bytes). Estas métricas son efímeras: solo existen mientras el script de Python o Scala se está ejecutando.
2. Habilitar el Endpoint de Prometheus en Spark¶
Spark utiliza un archivo llamado metrics.properties para definir a dónde envía su telemetría.
Si nos vamos al repositorio oficial de Spark, podemos ver el template que tiene spark para las métricas en el archivo metrics.properties.template. Busca la configuración de Prometheus buscando PrometheusServlet (probablemente al final del archivo). Verás que Spark ya tiene una configuración predefinida comentada para exponer sus métricas a través de un endpoint HTTP compatible con Prometheus. Solo necesitamos habilitar esta configuración y asegurarnos de que el puerto que utiliza esté abierto para que Prometheus pueda acceder a él.
2.1 Habilitar el Endpoint de Prometheus en Spark¶
Vamos a activar esta configuración para que Spark exponga sus métricas a Prometheus en nuestro cluster de contenedores. Para ello, sigue estos pasos:
- En la raíz de nuestro proyecto de docker compose, vamos a crear una nueva carpeta para la configuración de Spark en nuestra monitorización:
- Crea el archivo
metrics.propertiesdentro de esa carpeta:
- Añade la siguiente línea (que debería ser la misma que la que aparece en el template). El asterisco (
*) indica que esta regla aplica a todos los componentes (Master, Worker y Driver):
*.sink.prometheusServlet.class=org.apache.spark.metrics.sink.PrometheusServlet
*.sink.prometheusServlet.path=/metrics/prometheus
master.sink.prometheusServlet.path=/metrics/master/prometheus
applications.sink.prometheusServlet.path=/metrics/applications/prometheus
2.2 Actualizar el docker-compose.yml para Spark¶
Editamos las secciones volumes de spark-master y de nuestros tres spark-worker:
# Ejemplo para el Master (Aplica lo mismo a los Workers)
spark-master:
# ... resto de configuración ...
volumes:
- spark_master_logs:/opt/spark/logs
# --- NUEVO: Inyectamos la configuración de métricas ---
- ./monitoring/spark_conf/metrics.properties:/opt/spark/conf/metrics.properties:ro
spark-worker-1, 2 y 3).
2.3 Actualizar la configuración de Prometheus para Spark¶
Ahora tenemos que decirle a nuestra base de datos de métricas (Prometheus) el endpoint.
Rutas diferentes para Master y Worker
A diferencia de Kafka donde todo colgaba de /metrics, Spark organiza sus endpoints web de forma diferente. El Master expone sus métricas en /metrics/master/prometheus (puerto 8080), mientras que los Workers lo hacen en /metrics/prometheus (puerto 8081). Puedes consultarlo en la documentación oficial de Spark (busca la tabla de componentes y métricas).
Abrimos nuestro archivo monitoring/prometheus.yml y añadimos estos dos nuevos jobs al final de la sección scrape_configs:
# ... (Jobs de prometheus y kafka-cluster anteriores) ...
# 1. Scrape del Spark Master
- job_name: "spark-master"
metrics_path: '/metrics/master/prometheus'
static_configs:
- targets:
- "spark-master:8080"
# 2. Scrape de los Spark Workers
- job_name: "spark-workers"
metrics_path: '/metrics/prometheus'
static_configs:
- targets:
- "spark-worker-1:8081"
- "spark-worker-2:8081"
- "spark-worker-3:8081"
2.4 Docker compose completo¶
Para más comodidad, aquí tienes el docker-compose.yml completo con las modificaciones para la monitorización:
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
prometheus_data:
grafana_data: {}
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
# --- Inyectamos la configuración de métricas ---
- ./monitoring/spark_conf/metrics.properties:/opt/spark/conf/metrics.properties:ro
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
# --- Inyectamos la configuración de métricas ---
- ./monitoring/spark_conf/metrics.properties:/opt/spark/conf/metrics.properties:ro
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
# --- Inyectamos la configuración de métricas ---
- ./monitoring/spark_conf/metrics.properties:/opt/spark/conf/metrics.properties:ro
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
# --- Inyectamos la configuración de métricas ---
- ./monitoring/spark_conf/metrics.properties:/opt/spark/conf/metrics.properties:ro
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
# Añadimos también la librería de Kafka separada por coma del paquete de Connect para Spark Streaming con Kafka
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1,org.apache.spark:spark-sql-kafka-0-10_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
# Le inyectamos el worker directamente. La UI lo auto-descubrirá.
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)
# -------------------------------------------
# Monitoring con Prometheus
# -------------------------------------------
prometheus:
image: prom/prometheus:v3.5.1
container_name: prometheus
networks:
- bda-network
ports:
- "9090:9090" # Acceso directo a la UI de Prometheus
volumes:
# Inyectamos nuestra configuración
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
# Persistencia de métricas
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
labels:
# --- ENRUTAMIENTO TRAEFIK ---
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.localhost`)"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
- "traefik.http.routers.prometheus.entrypoints=web"
# --- DASHBOARDS VISUALES ---
grafana:
image: grafana/grafana
container_name: grafana
restart: unless-stopped
networks:
- bda-network
ports:
- "3000:3000" # Acceso a la UI de Grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin # Contraseña por defecto
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
labels:
# Opcional: Integración con Traefik
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.localhost`)"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.entrypoints=web"
# --- KAFKA EXPORTER (Calculador de Lag de Consumidores) ---
kafka-exporter:
image: danielqsj/kafka-exporter:latest
container_name: kafka-exporter
networks:
- bda-network
command:
- "--kafka.server=kafka-broker-1:9092"
- "--kafka.server=kafka-broker-2:9092"
- "--kafka.server=kafka-broker-3:9092"
ports:
- "9308:9308" # Puerto donde expone las métricas
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
2.5 Prometheus completo¶
Para más comodidad, aquí tienes el bloque completo de prometheus.yml con la configuración que vimos antes.:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
# Monitorización de nuestros 3 Brokers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-brokers"
static_configs:
- targets:
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Monitorización de nuestros 3 Controllers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-controllers"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- job_name: "kafka"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Scrape del calculador de Lag
- job_name: "kafka-exporter"
static_configs:
- targets: ["kafka-exporter:9308"]
# Monitorización de nuestro Clúster de Spark
# Scrape del Spark Master
- job_name: "spark-master"
metrics_path: '/metrics/master/prometheus'
static_configs:
- targets:
- "spark-master:8080"
# Scrape de los Spark Workers
- job_name: "spark-workers"
metrics_path: '/metrics/prometheus'
static_configs:
- targets:
- "spark-worker-1:8081"
- "spark-worker-2:8081"
- "spark-worker-3:8081"
2.6 Despliegue y verificación¶
Reiniciamos la infraestructura para aplicar los cambios de volúmenes y la nueva configuración de Prometheus.
Antes de ir a Grafana, verificamos que el endpoint HTTP está funcionando.
-
Nos aseguramos que se ha habilitado correctamente las métricas en Spark. Lo podemos observar entrando en el apartado Spark Properties de
Environmentsen el Spark UI http://spark.localhost/environment/ usando Traefik o http://localhost:8080/environment/. Deberíamos ver la propiedadspark.ui.prometheus.enabledcon el valortrue. -
También podemos verificar que el endpoint HTTP de métricas está funcionando correctamente. Para ello, abrimos el navegador y entramos en el endpoint del Master http://spark.localhost:8080/metrics/master/prometheus. Deberíamos ver una página con un formato similar a este:
metrics_master_aliveWorkers_Number{type="gauges"} 3
metrics_master_aliveWorkers_Value{type="gauges"} 3
metrics_master_apps_Number{type="gauges"} 0
metrics_master_apps_Value{type="gauges"} 0
metrics_master_waitingApps_Number{type="gauges"} 0
metrics_master_waitingApps_Value{type="gauges"} 0
metrics_master_workers_Number{type="gauges"} 3
metrics_master_workers_Value{type="gauges"} 3
.....
- Por último, verificamos que Prometheus está recogiendo correctamente las métricas. Para ello, entramos en el panel de Prometheus (http://prometheus.localhost/targets) usando Traefik o (http://localhost:9090/targets). Deberíamos ver los jobs
spark-masteryspark-workerscon todos los endpoints en estado UP (Verde).
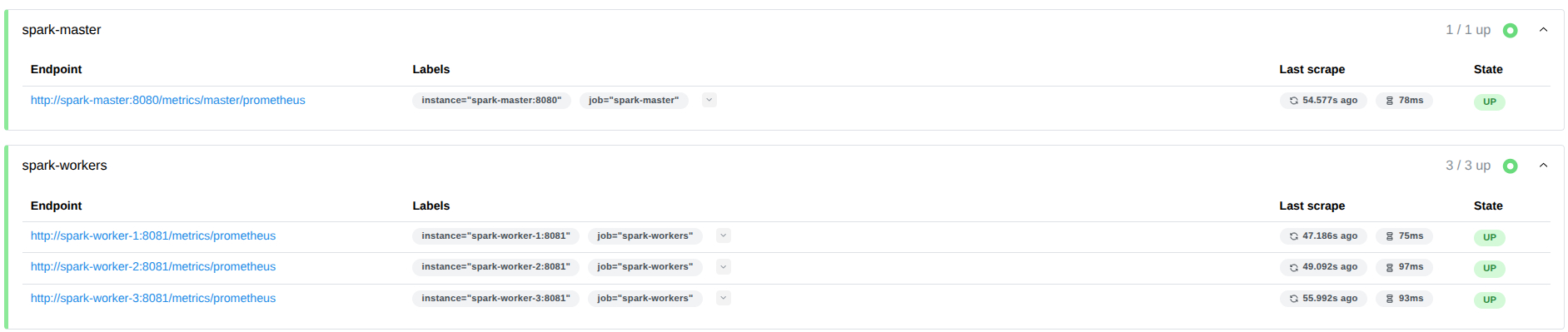
Abrimos el navegador y entramos en el panel de Prometheus: http://prometheus.localhost/targets
Deberíamos ver los jobs spark-master y spark-workers con todos los endpoints en estado UP (Verde).
3. Visualización con Grafana¶
Ya tenemos los datos fluyendo hacia Prometheus. Solo falta añadir el dashboard. Haremos lo mismo que hicimos para el clúster de Kafka, pero esta vez con un dashboard específico para Spark. Por tanto:
- Abrimos Grafana en tu navegador: http://grafana.localhost
- Vamos al menú lateral: Dashboards -> New -> Import.
- En este caso, usaremos de nuevo un dashboard personalizado que puedes descargar en este enlace.
- Haz clic en Upload JSON file y selecciona el archivo que acabas de descargar.
- En el último paso, en la opción
DS_PROMETHEUS, selecciona tu conexión de Prometheus en el desplegable y haz clic en Import.
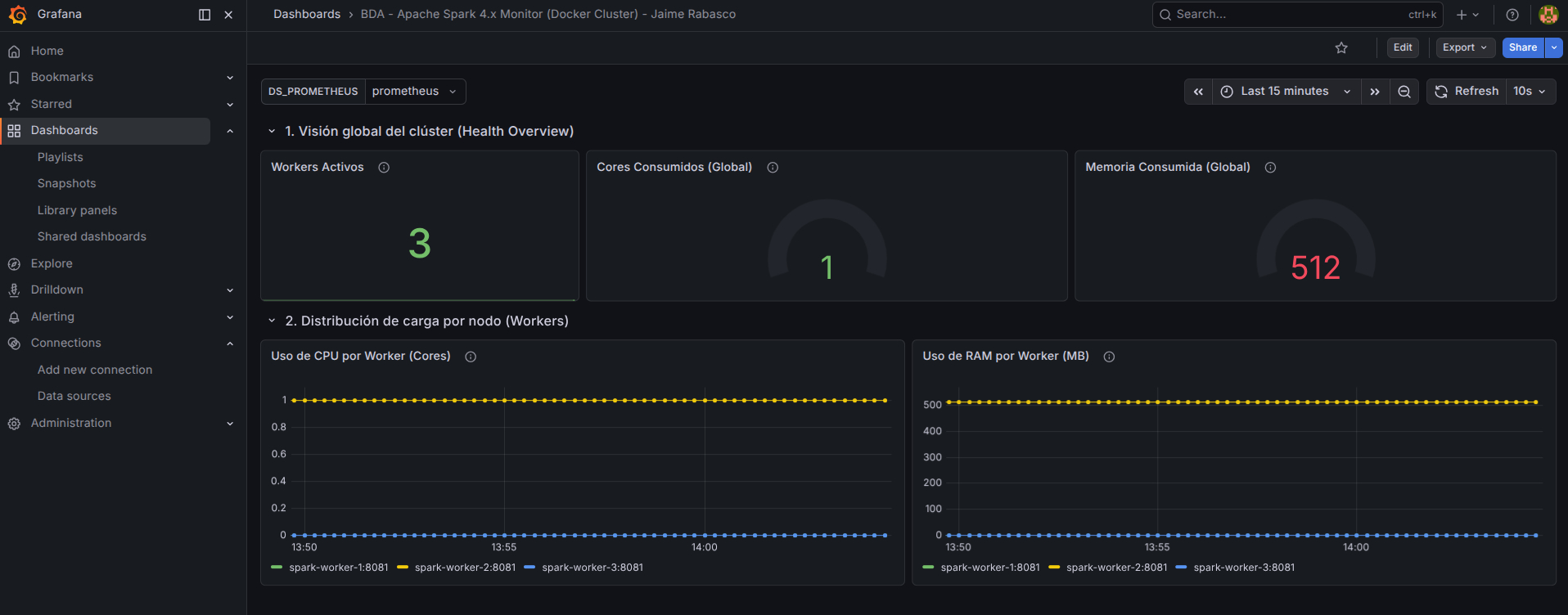
Generar Tráfico
Si el dashboard aparece muy "plano", es porque el clúster está inactivo. Lanza el script del "Cálculo de Pi" o el ejemplo de "Pandas on Spark" que hicimos en los temas anteriores. Inmediatamente verás cómo las gráficas de Cores Used, Active Workers y Memory pegan un salto en tiempo real. ¡Has logrado visibilidad total sobre tu motor de cómputo!
4. Ejemplo 1: Monitorización del cálculo de Pi con Spark¶
Vamos a lanzar el clásico ejemplo de cálculo de Pi con Spark para generar algo de tráfico en el clúster y ver cómo se refleja en nuestro dashboard de Grafana.
- Abrimos nuestro Dashboard de Grafana para Spark.
- Lanzamos el script de cálculo de Pi en nuestro cluster, tal y como hicimos en el ejemplo del cálculo de Pi con Spark en la UD6.
- Ejecutamos el script:
docker exec -it spark-master /opt/spark/bin/spark-submit \
--master spark://spark-master:7077 \
--class org.apache.spark.examples.SparkPi \
/opt/spark/examples/jars/spark-examples_2.13-4.0.1.jar 10
- Observa cómo las métricas de tu dashboard de Grafana para Spark reflejan el aumento de actividad en el clúster: el número de cores usados, la memoria consumida, el número de tareas activas, etc.