UD 8 - Monitor Apache Kafka¶
1. Introducción¶
En un entorno de producción, la monitorización de Kafka (y cualquier otro de Big Data) es crucial para asegurar que el sistema esté funcionando de manera eficiente y sin interrupciones. Kafka es una plataforma de mensajería distribuida muy robusta, pero requiere una supervisión constante para garantizar que todos los componentes, como los brokers, controllers, productores y consumidores, estén operando correctamente. Sin una monitorización adecuada, es difícil detectar problemas de rendimiento, cuellos de botella, y errores en tiempo real que pueden afectar la calidad del servicio.
La monitorización de Kafka permite:
-
Rendimiento: Evaluar las métricas de throughput, latencia y el uso de recursos para garantizar un rendimiento óptimo.
-
Escalabilidad: Detectar problemas antes de que afecten a la escalabilidad del sistema.
-
Detección de fallos: Identificar problemas potenciales con los brokers, consumidores o productores que puedan estar interfiriendo con el flujo de datos.
-
Optimización: Tomar decisiones informadas sobre la configuración y la infraestructura para mejorar la eficiencia del sistema.
En esta guía, exploraremos cómo monitorizar un clúster de Kafka utilizando JMX (Java Management Extensions) para exponer métricas internas de Kafka, Prometheus para recolectar estas métricas, y Grafana para visualizar las métricas en paneles interactivos.
2. ¿Qué es JMX?¶
JMX (Java Management Extensions) es una tecnología de Java que permite gestionar y monitorizar aplicaciones, dispositivos y servicios basados en Java. Kafka, al ser una aplicación basada en Java, expone muchas de sus métricas internas a través de JMX.
JMX permite obtener métricas valiosas como el uso de CPU, la memoria, el rendimiento de los brokers, el rendimiento de los consumidores y los productores, la latencia, el número de particiones y más. Estas métricas son fundamentales para la administración eficiente de un clúster de Kafka.
3. ¿Qué es Prometheus?¶
Prometheus es una herramienta de monitoreo y recopilación de métricas de código abierto, diseñada para almacenar series temporales de datos. Funciona extrayendo métricas de las aplicaciones a través de un formato estándar que puede ser consultado mediante su lenguaje de consulta, PromQL.
Prometheus es ampliamente utilizado para la monitorización de sistemas distribuidos como Kafka debido a su capacidad para recolectar y almacenar grandes volúmenes de métricas de manera eficiente y en tiempo real.
Características principales de Prometheus:
-
Recolección de métricas basada en scrapes: Prometheus obtiene métricas mediante el mecanismo de scraping desde los endpoints HTTP de las aplicaciones.
-
Modelo de datos multidimensional: Las métricas son etiquetadas, lo que permite una rica semántica de consulta y filtrado.
-
Escalabilidad: Puede recolectar y almacenar grandes cantidades de datos sin comprometer el rendimiento.
-
Integración con Grafana (además de otros servicios): Prometheus se integra perfectamente con Grafana para crear dashboards visuales.
4. ¿Qué es Grafana?¶
Grafana es una plataforma de código abierto para la visualización y análisis de métricas. Es compatible con diversas fuentes de datos, y se usa principalmente para la visualización de series temporales de datos.
Cuando se combina con Prometheus, Grafana se convierte en una herramienta poderosa para representar visualmente las métricas de sistemas distribuidos como Kafka (y muchísimos otros). Con Grafana, puedes crear paneles interactivos y gráficos que muestran el rendimiento de Kafka en tiempo real, facilitando la detección de anomalías o problemas.
Características principales de Grafana:
-
Visualización de datos en tiempo real: Ofrece gráficos interactivos que se actualizan en tiempo real.
-
Paneles personalizables: Los usuarios pueden crear paneles personalizados según sus necesidades.
-
Soporte para múltiples fuentes de datos: Grafana puede conectarse a una amplia variedad de fuentes de datos, como Prometheus, Elasticsearch, InfluxDB, entre otras.
5. ¿Por qué usar JMX, Prometheus y Grafana para la monitorización de Kafka?¶
La combinación de JMX, Prometheus y Grafana es una solución altamente eficiente para la monitorización de Kafka por las siguientes razones:
-
JMX permite acceder directamente a las métricas internas de Kafka, proporcionando una visión profunda de su rendimiento y estado.
-
Prometheus es ideal para recolectar y almacenar estas métricas de manera eficiente, soportando grandes volúmenes de datos y permitiendo consultas de alto rendimiento con PromQL.
-
Grafana es una herramienta muy completa para visualizar las métricas recolectadas, permitiendo una monitorización en tiempo real con dashboards altamente personalizables y fáciles de usar.
Esta combinación ofrece una solución completa y escalable para monitorizar un clúster de Kafka, ayudando a los administradores a detectar problemas rápidamente, optimizar el rendimiento y garantizar la disponibilidad continua del sistema.
6 Funcionamiento JMX + Prometheus + Grafana¶
6.1 Conectando JMX y Prometheus¶
Sin entrar en mucho detalle, el flujo de monitorización con JMX, Prometheus y Grafana es el siguiente:
Kafka expone una variedad de métricas a través de JMX, las cuales están relacionadas con los brokers, productores, consumidores, etc.
Por otro lado, Prometheus es un ecosistema con dos componentes principales:
- el componente del lado del servidor
- la configuración del lado del cliente.
El componente del lado del servidor se encarga de almacenar todas las métricas y de realizar el scraping de todos los clientes. Prometheus se diferencia de servicios como Elasticsearch y Splunk, que suelen utilizar un componente intermedio responsable de extraer los datos de los clientes y enviarlos a los servidores. Dado que no hay ningún componente intermedio que extraiga las métricas de Prometheus, todas las configuraciones relacionadas con las encuestas están presentes en el propio servidor.
El proceso tiene este aspecto:
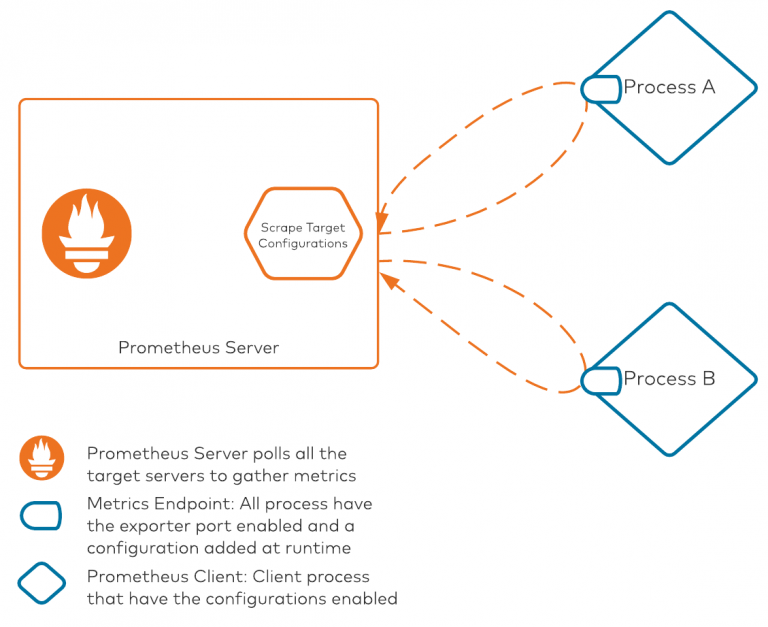
Hay dos piezas centrales en este diagrama:
-
Servidor Prometheus: Este componente es responsable de sondear todos los procesos/clientes con sus métricas expuestas en un puerto específico. El servidor de Prometheus mantiene internamente un archivo de configuración que enumera todas las direcciones IP/nombres de host del servidor y los puertos en los que se exponen las métricas de Prometheus. La configuración de objetivos de scrape es el archivo que mantiene toda la asignación de objetivos dentro de Prometheus. Los objetivos de scrape son necesarios cuando estamos desplegando todo manualmente sin ningún tipo de automatización. Prometheus también admite módulos de descubrimiento de servicios, que puede aprovechar para descubrir cualquier servicio disponible que esté exponiendo métricas.
-
Procesos cliente: Todos los clientes que quieran aprovechar Prometheus necesitarán dos piezas de configuración. En primer lugar, deben utilizar la biblioteca de clientes de Prometheus para exponer métricas en un formato compatible con Prometheus (OpenMetrics). En segundo lugar, deben utilizar un archivo de configuración YAML para extraer métricas JMX. Este archivo de configuración se utiliza para convertir, renombrar y filtrar algunos de los atributos para su consumo.
6.2 Connecting Grafana a Prometheus¶
Ahora que tenemos nuestros datos de métricas transmitiéndose al servidor Prometheus, podemos empezar a crear paneles de control de nuestras métricas. La herramienta elegida en nuestra pila es Grafana. Conceptualmente, este es el aspecto que tendrá el proceso una vez que hayamos conectado Grafana a Prometheus:
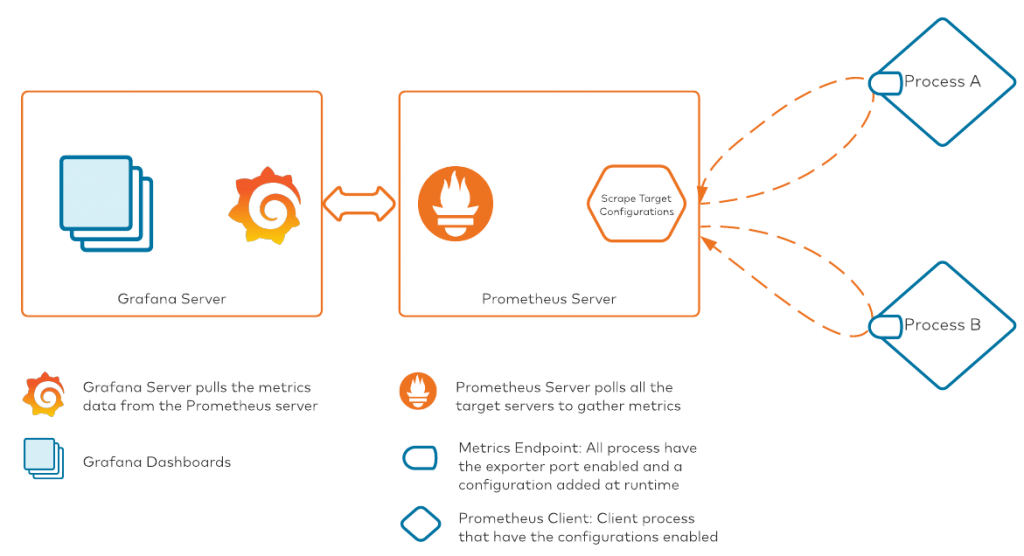
Hay dos maneras de conectar Grafana con Prometheus: Podemos configurar la conexión desde la GUI de Grafana, o podemos añadir los detalles de la conexión a las configuraciones de Grafana antes del arranque. Hay artículos muy detallados disponibles en la documentación de Grafana. Seguiremos esta documentación en el siguiente apartado donde explicamos la instalación y configuración.
Más información
Para más información sobre la monitorización de Kafka con JMX, Prometheus y Grafana, puedes consultar los siguientes recursos:
- Documentación oficial de Kafka sobre Monitorización
- Documentación oficial de Prometheus
- Documentación oficial de Grafana
- Repositorio de github de Prometheus. Incluye toda la documentación y ejemplos de configuración.
- Repositorio de github de JMX Exporter
7. Configuración de JMX + Prometheus + Grafana¶
7.1 Habilitar JMX en Kafka¶
- En primer lugar, necesitamos añadir la librería JMX Exporter. Descarga la última versión.
wget https://github.com/prometheus/jmx_exporter/releases/download/1.2.0/jmx_prometheus_javaagent-1.2.0.jar
- Guardamos la librería en el directorio de librerías de Kafka
- Necesitamos configurar nuestro JMX Exporter para que sepa lo que va a extraer de Kafka. Para explicarlo brevemente, la configuración es una colección de regexps que nombra y filtra las métricas para Prometheus. Gracias a Prometheus, tenemos configuraciones de ejemplo en su repositorio de Github. Usaremos la configuración de ejemplo mas reciente (
kafka-kraft-3_0_0.yml) en esta configuración.
wget https://raw.githubusercontent.com/prometheus/jmx_exporter/refs/heads/main/examples/kafka-kraft-3_0_0.yml
- La movemos a la carpeta de configuración de kafka
-
Añadimos JMX a Kafka. Para ello, tenemos que indicarlo cada vez que usamos kafka. Por tanto, debemos abrir el script de inicio de los servidores de kafka (
kafka-server-start.sh) y añadir JMX Exporter con su configuración correspondiente. -
Primero hacemos una copia de respaldo y abrimos el script
cp /opt/kafka_2.13-4.0.0/bin/kafka-server-start.sh /opt/kafka_2.13-4.0.0/bin/kafka-server-start.sh.bak
nano /opt/kafka_2.13-4.0.0/bin/kafka-server-start.sh
- Añadimos al final la configuración de JMX Exporter. Debemos colocar esta línea antes de la linea de la ejecución de
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@". Por tanto, la colocamos, por ejemplo, al principio. Hemos elegido el puerto9091para exponer los datos a Prometheus. Puedes usar el que quieras
export KAFKA_OPTS="-javaagent:/opt/kafka_2.13-4.0.0/libs/jmx_prometheus_javaagent-1.2.0.jar=9091:/opt/kafka_2.13-4.0.0/config/jmx-exporter-kafka.yml"
- En el caso de que tuviéramos kafka en ejecución, lo reiniciamos.
7.2 Prometheus¶
- Descarga la última versión LTS de Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.53.4/prometheus-2.53.4.linux-amd64.tar.gz
tar -xzf prometheus-2.53.4.linux-amd64.tar.gz
- Movemos el directorio a nuestro directorio
/optpara una correcta organización
- Accedemos al directorio de Prometheus
- Vemos que existe un fichero de configuración
prometheus.yml. Hacemos una copia de respaldo
- Abrimos el archivo de configuración
-
Como vemos, ya existe una configuración de scraping del propio prometheus en
job_name. Como puedes observar, para añadir diferentes scrapings(en este caso para nuestro JMX Exporter de Kafka), debemos añadir un configurar en un nuevojob_name. Añadimos la configuración indicando también el correspondiente endpoint en el puerto 9091. -
Por tanto, añadimos debajo (recuerda respetar tabulaciones y formatos)
- job_name: "kafka"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9091"]
- El resultado sería.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "kafka"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9091"]
- En el caso de que tuviéramos prometheus en ejecución, lo reiniciamos.
7.3. Ejemplo JMX + Prometheus¶
-
Antes de seguir con la configuración con Grafana, vamos a comprobar que nuestra configuración es correcta. Lanzamos un cluster de kafka en modo server y vemos si JMX Exporter da métricas correctamente y éstas son recogidas por prometheus.
-
Iniciamos Kafka
#Genera un cluster UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
#Si no te permite formatear (con el comando siguiente) es debido a que se mantienen los logs del ejemplo anterior. debes borrarlos
#sudo rm -r /tmp/kraft-combined-logs/
#Formatea el directorio de log
bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/server.properties
#Ejecuta el servidor Kafka
bin/kafka-server-start.sh config/server.properties
- Comprobamos que se ha expuesto correctamente el endpoint en
9091:
tcp LISTEN 0 3 *:9091 *:* users:(("java",pid=9692,fd=115)) uid:1000 ino:34770 sk:f cgroup:/user.slice/user-1000.slice/session-1.scope v6only:0 <->
- Y comprobamos que JMX Exporter está funcionando correctamente. Podemos hacerlo con curl o en el navegador en el puerto
:9091/metrics
# TYPE jmx_config_reload_failure_total counter
jmx_config_reload_failure_total 0.0
# HELP jmx_config_reload_success_total Number of times configuration have successfully been reloaded.
# TYPE jmx_config_reload_success_total counter
jmx_config_reload_success_total 0.0
# HELP jmx_exporter_build_info JMX Exporter build information
# TYPE jmx_exporter_build_info gauge
jmx_exporter_build_info{name="jmx_prometheus_javaagent",version="1.2.0"} 1
# HELP jmx_scrape_cached_beans Number of beans with their matching rule cached
# TYPE jmx_scrape_cached_beans gauge
jmx_scrape_cached_beans 0.0
# HELP jmx_scrape_duration_seconds Time this JMX scrape took, in seconds.
# TYPE jmx_scrape_duration_seconds gauge
jmx_scrape_duration_seconds 0.667689572
# HELP jmx_scrape_error Non-zero if this scrape failed.
# TYPE jmx_scrape_error gauge
jmx_scrape_error 0.0
# HELP jvm_buffer_pool_capacity_bytes Bytes capacity of a given JVM buffer pool.
# TYPE jvm_buffer_pool_capacity_bytes gauge
jvm_buffer_pool_capacity_bytes{pool="direct"} 1574526.0
jvm_buffer_pool_capacity_bytes{pool="mapped"} 2.0971516E7
jvm_buffer_pool_capacity_bytes{pool="mapped - 'non-volatile memory'"} 0.0
# HELP jvm_buffer_pool_used_buffers Used buffers of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_buffers gauge
jvm_buffer_pool_used_buffers{pool="direct"} 11.0
jvm_buffer_pool_used_buffers{pool="mapped"} 2.0
jvm_buffer_pool_used_buffers{pool="mapped - 'non-volatile memory'"} 0.0
# HELP jvm_buffer_pool_used_bytes Used bytes of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_bytes gauge
jvm_buffer_pool_used_bytes{pool="direct"} 1574526.0
jvm_buffer_pool_used_bytes{pool="mapped"} 2.0971516E7
jvm_buffer_pool_used_bytes{pool="mapped - 'non-volatile memory'"} 0.0
# HELP jvm_classes_currently_loaded The number of classes that are currently loaded in the JVM
# TYPE jvm_classes_currently_loaded gauge
jvm_classes_currently_loaded 9132.0
- Iniciamos Prometheus. Vamos a su directorio
/opt/prometheus-2.53.4. Levantamos prometheus
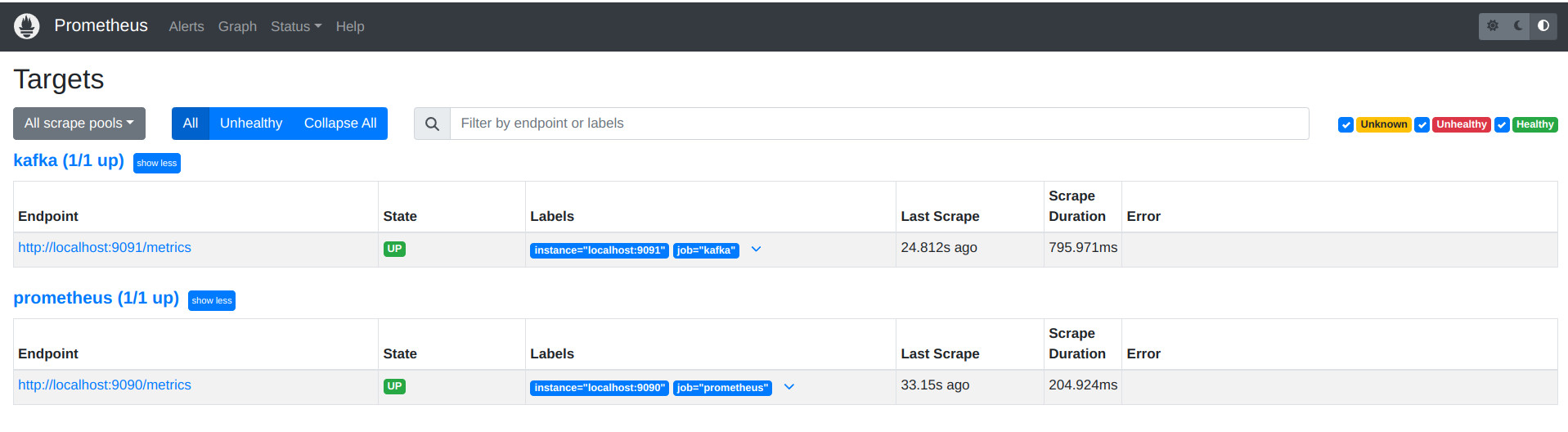
- Comprobamos que prometheus captura correctamente el endpoint
http://192.168.56.10:9090/targets(recuerda que accedemos desde nuestro host con esta configuración de red a nuestra máquina)
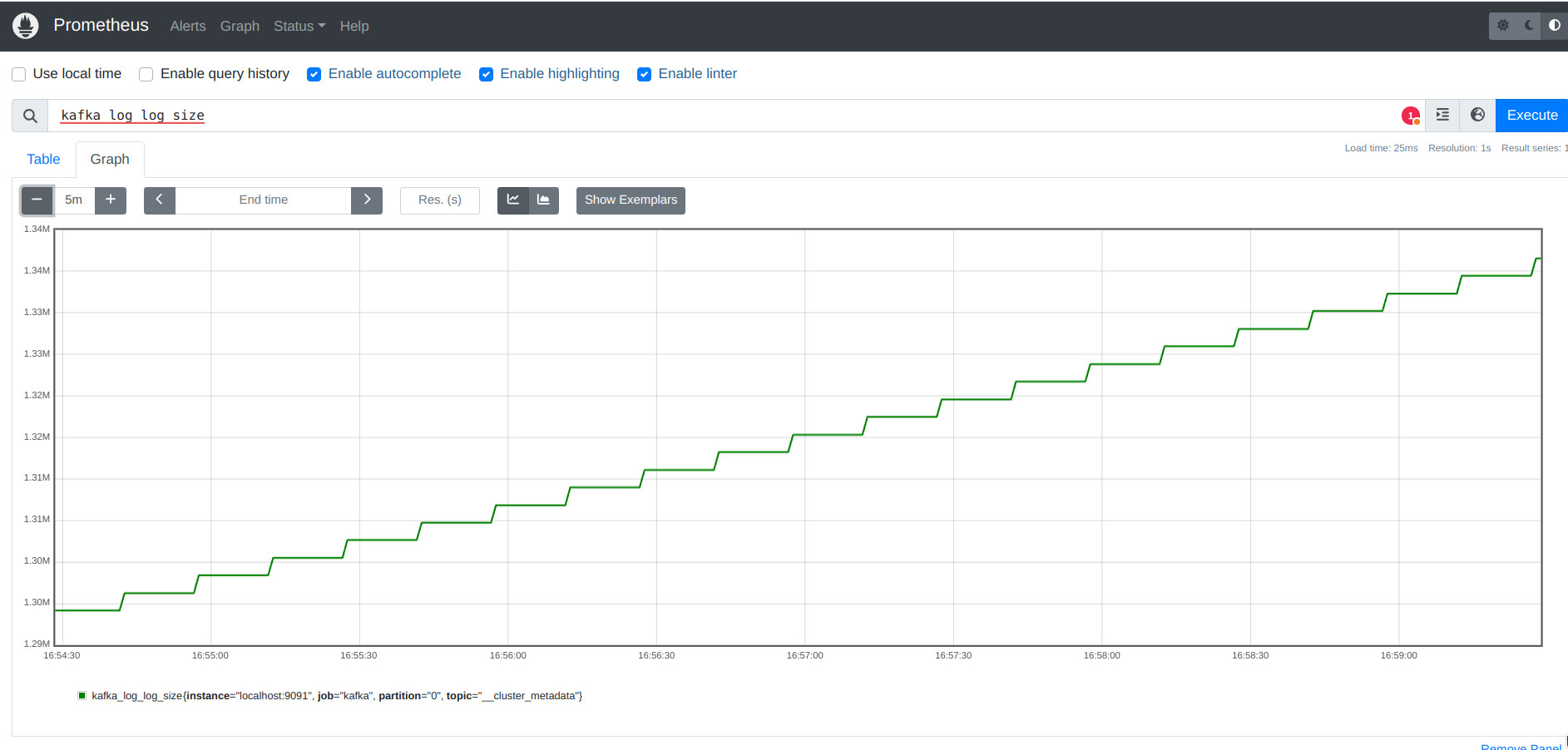
- También podemos comprobar que los datos de kafka se capturan correctamente desde Prometheus buscando
kafka.
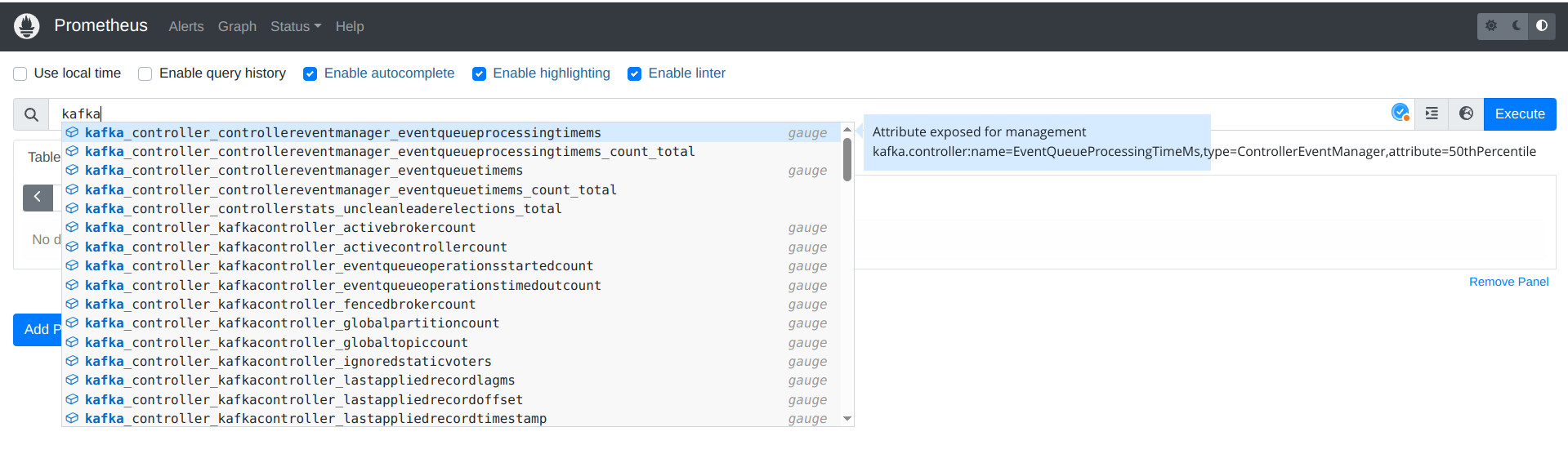
- Puedes elegir cualquiera de las métricas
7.4 Prometheus + Grafana¶
-
Toda la documentación de Grafana OSS la tenemos en su página oficial
-
Descarga e instala la última versión de Grafana.
sudo apt-get install -y adduser libfontconfig1 musl
wget https://dl.grafana.com/enterprise/release/grafana-enterprise_11.6.1_amd64.deb
sudo dpkg -i grafana-enterprise_11.6.1_amd64.deb
- Inicia Grafana
Grafana como servicio
Si quieres habilitar grafana para que arranque automáticamente usando systemd, ejecuta:
-
Accedemos a su WebUI en el puerto
3000http://localhost:3000, en nuestro casohttp://192.168.56.10:3000/desde el host -
Entramos con las credenciales usuario
adminy passadmin. Cámbiala a tu criterio.
En un entorno de producción, además de lanzar el clúster necesitamos saber cuántos mensajes entran, si los consumidores van lentos (Lag) o si un Broker se está quedando sin memoria.
Para ello, implementaremos el unos de los stack más utilizados por la industria JMX + Prometheus + Grafana:
- JMX Exporter: Un "agente" o que se inyecta en la Máquina Virtual Java (JVM) de Kafka para traducir sus métricas internas a un formato moderno.
- Prometheus: Una base de datos de series temporales que "tira" (pull) de las métricas de Kafka cada 15 segundos y las almacena.
- Grafana: Un panel de control visual que lee de Prometheus y pinta gráficos interactivos.
7.1. Preparación del Entorno - Agente JMX (Docker)¶
Para que Kafka exponga sus métricas a Prometheus, necesitamos descargar el agente JMX y su archivo de configuración (las reglas de qué métricas leer).
-
En primer lugar, necesitamos añadir la librería JMX Exporter. Descarga la última versión.
-
En tu máquina Host (donde está el
docker-compose.yml), crea una carpeta para la monitorización:
mkdir -p monitoring/jmx
cd monitoring/jmx
# 1. Descargamos el Agente Java de Prometheus
wget https://github.com/prometheus/jmx_exporter/releases/download/1.5.0/jmx_prometheus_javaagent-1.5.0.jar
- Descargamos las reglas de métricas recomendadas para Kafka (puedes elegir otras dependiendo de tu versión y necesidades, pero esta es una buena base)
# 2. Descargamos las reglas de métricas recomendadas para Kafka KRaft
wget https://raw.githubusercontent.com/prometheus/jmx_exporter/refs/heads/main/examples/kafka-kraft-3_0_0.yml -O kafka-jmx.yml
7.2. Configuración de Prometheus (Docker)¶
Prometheus necesita un "mapa" para saber a qué puertas debe llamar para recoger las métricas. Crearemos su archivo de configuración. Para ello usaremos como base el archivo de configuración base de prometheus (prometheus.yml), para después, añadirle los bloques de configuración configuración necesarios para que sepa que tiene que recoger las métricas que le indiquemos de nuestro cluster.
- Descarga el archivo
prometheus.ymldentro de la carpetamonitoring:
# Estando en la raíz del proyecto
cd monitoring
wget https://raw.githubusercontent.com/prometheus/prometheus/refs/heads/main/documentation/examples/prometheus.yml
- Edita el archivo
prometheus.ymlpara añadir la configuración de scraping de Kafka. Debajo del bloque de configuración del propio Prometheus, añadiremos nuevos bloques para Kafka, cada uno en su correspondientejob_name. Este sería sólo para los brokers, pero puedes añadir otro bloque para los controllers si quieres.
# Monitorización de nuestros 3 Brokers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-brokers"
static_configs:
- targets:
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
- El resultado final de todos nuestros job_names debería ser algo así:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
# Monitorización de nuestros 3 Brokers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-brokers"
static_configs:
- targets:
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Monitorización de nuestros 3 Controllers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-controllers"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- job_name: "kafka"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
7.3. Integración en Docker Compose (Docker)¶
Ahora uniremos todas las piezas.
- Inyectaremos el agente JMX en los brokers de Kafka.
- Desplegaremos Prometheus.
- Desplegaremos Grafana.
7.3.1 Actualizamos los nodos de Kafka¶
Variables de entorno
A diferencia de un servidor físico donde tendrías que modificar el archivo kafka-server-start.sh, en Docker simplemente usamos la variable KAFKA_OPTS. El script de arranque de la imagen oficial está programado para concatenar esta variable al comando de Java automáticamente.
Abrimos nuestro docker-compose.yml y modificamos la configuración de nuestros 3 Brokers (kafka-broker-1, 2 y 3) y 3 Controllers (kafka-controller-1, 2 y 3).
Debes añadir la variable KAFKA_OPTS y montar la carpeta monitoring/jmx.
Ejemplo para kafka-broker-1 (repite para el 2 y el 3 y para los controllers):
kafka-broker-1:
image: apache/kafka:4.2.0
# ... (redes, puertos, etc. se mantienen igual) ...
environment:
# ... (resto de tus variables KAFKA_...) ...
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
7.3.2 Añadimos Prometheus¶
Usaremos la última versión LTS de Prometheus. Dependiendo de cunado estés leyendo esta documentación, puede ser una versión diferente a la usada aquí. Consulta la documentación oficial para saber la versión actual LTS y la última versión de Grafana.
Añadimos prometheus al final de nuestro docker-compose.yml:
# ---- Monitoring ---
prometheus:
image: prom/prometheus:v3.5.1
container_name: prometheus
networks:
- bda-network
ports:
- "9090:9090" # Acceso directo a la UI de Prometheus
volumes:
# Inyectamos nuestra configuración
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
# Persistencia de métricas
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
labels:
# --- ENRUTAMIENTO TRAEFIK ---
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.localhost`)"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
- "traefik.http.routers.prometheus.entrypoints=web"
No olvides registrar el volúmen de Prometheus:
7.3.3 Añadimos Grafana¶
Antes de añadir Grafana, es importante destacar que hay 2 versiones de Grafana: la versión OSS (Open Source) y la versión Enterprise.
-
Grafana OSS (Open Source Software): Es la versión 100% gratuita y de código abierto (licencia AGPLv3). Tiene todo lo que necesitas para el 99% de los casos: conexión con Prometheus, creación de Dashboards, alertas, gestión básica de usuarios y conexión con bases de datos estándar (MySQL, Postgres, ElasticSearch...).
-
Grafana Enterprise Edition: Es la versión comercial de pago de Grafana Labs. Incluye todo lo del OSS, pero añade características para grandes corporaciones:
- Fuentes de datos Premium: Permite conectar Grafana a herramientas privativas caras como Splunk, Datadog, Oracle, Snowflake, ServiceNow o AppDynamics.
- Seguridad Avanzada: Control de acceso basado en roles (RBAC) muy granular, sincronización avanzada con Active Directory/SAML, y logs de auditoría (quién vio qué panel y a qué hora).-
- Soporte: Soporte técnico 24/7.
Nosotros elegiremos la versión OSS: Estamos construyendo un stack puro Open Source (Apache Hadoop, Apache Spark, Apache Kafka, Prometheus). Mantener Grafana en su versión OSS es ser fieles a esa arquitectura.
Por tanto, siguiendo el sitio oficial de descargas de Grafana y teniendo en cuenta la documentación oficial de instalación y uso en Docker compose de Grafana, añadiremos el siguiente bloque a nuestro docker-compose.yml:
# --- DASHBOARDS VISUALES ---
grafana:
image: grafana/grafana
container_name: grafana
restart: unless-stopped
networks:
- bda-network
ports:
- "3000:3000" # Acceso a la UI de Grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin # Contraseña por defecto
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
labels:
# Opcional: Integración con Traefik
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.localhost`)"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.entrypoints=web"
No olvides registrar le nuevos volúmenes de Grafana:
7.4 Docker compose completo con JMX, Prometheus y Grafana (Docker)¶
Recursos del host
Si tienes problemas de recursos en tu máquina host, puedes comentar el bloque de Kafka Connect si no lo vas a usar.
Por tanto, el bloque completo de monitorización en nuestro docker-compose.yml quedaría así:
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
prometheus_data:
grafana_data: {}
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
# Añadimos también la librería de Kafka separada por coma del paquete de Connect para Spark Streaming con Kafka
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1,org.apache.spark:spark-sql-kafka-0-10_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
# Le inyectamos el worker directamente. La UI lo auto-descubrirá.
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)
# -------------------------------------------
# Monitoring con Prometheus
# -------------------------------------------
prometheus:
image: prom/prometheus:v3.5.1
container_name: prometheus
networks:
- bda-network
ports:
- "9090:9090" # Acceso directo a la UI de Prometheus
volumes:
# Inyectamos nuestra configuración
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
# Persistencia de métricas
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
labels:
# --- ENRUTAMIENTO TRAEFIK ---
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.localhost`)"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
- "traefik.http.routers.prometheus.entrypoints=web"
# --- DASHBOARDS VISUALES ---
grafana:
image: grafana/grafana
container_name: grafana
restart: unless-stopped
networks:
- bda-network
ports:
- "3000:3000" # Acceso a la UI de Grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin # Contraseña por defecto
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
labels:
# Opcional: Integración con Traefik
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.localhost`)"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.entrypoints=web"
7.5 Despliegue y Verificación (Docker)¶
- Arrancamos el entorno con un reinicio limpio para aplicar todos los cambios:
- Validamos que el Exporter JMX de Kafka está funcionando correctamente:
Contendedor efímero para validar el Exporter JMX
En producción, las imágenes de los contenedores se construyen con lo estrictamente necesario para ejecutar la aplicación (Java o el binario en C de Prometheus). No incluir herramientas como curl, wget o bash reduce drásticamente la superficie de ataque si alguien logra colarse en el contenedor.
Por tanto, para comprobar que JMX se está ejecutandop correctamente, no podemos entrar al contenedor y hacer un curl local. En su lugar, levantamos un contenedor temporal en la misma red (bda-network), basado en una imagen de utilidades de red, hacemos la petición y dejamos que el contenedor se autodestruya (--rm). Esto descargará una imagen mínima de curl, entrará en tu red de Big Data, leerá las métricas de tu broker y desaparecerá sin dejar rastro.
docker run --rm --network bda-network curlimages/curl -s http://kafka-broker-1:9091/metrics | head -n 10
jmx_exporter_build_info, el agente está funcionando).
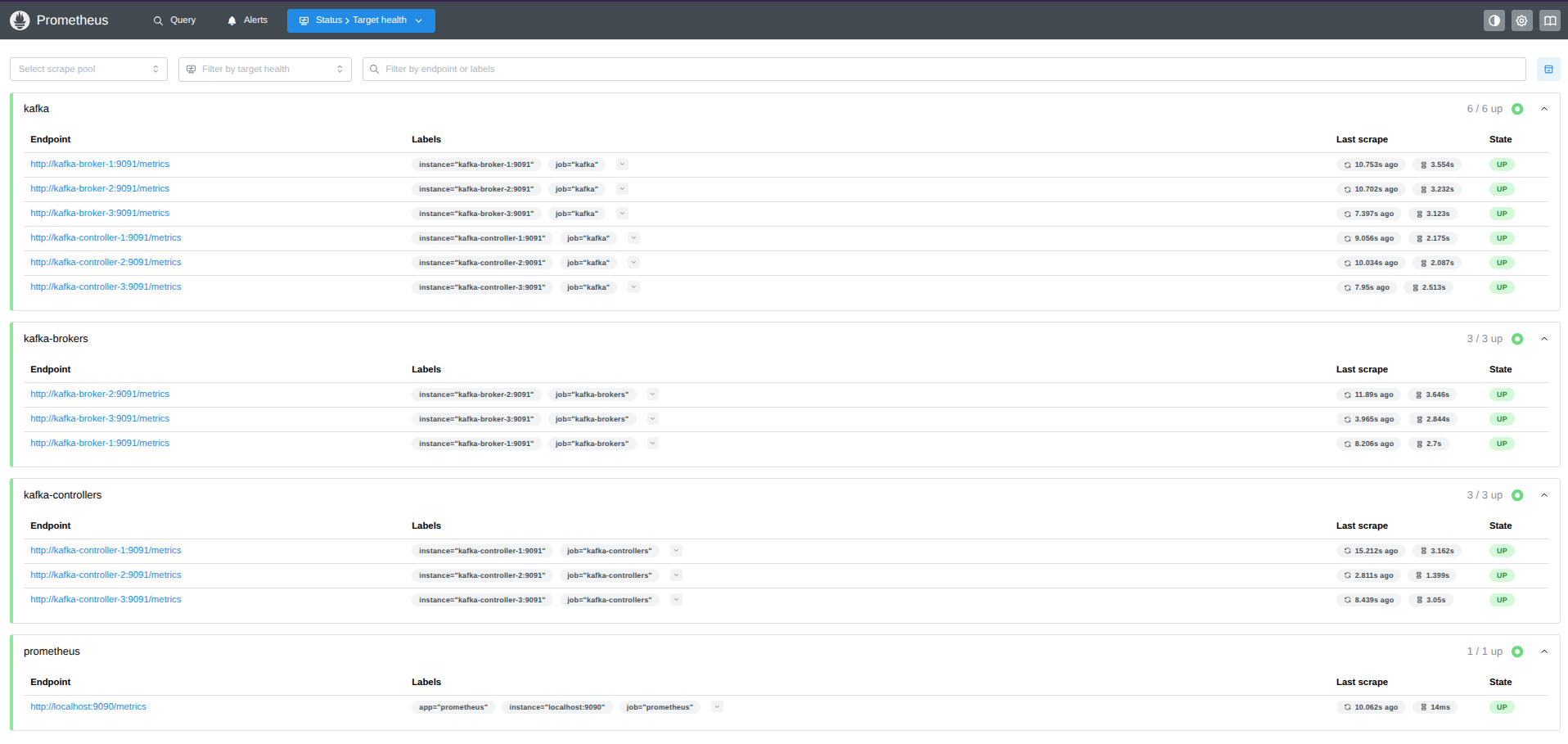
- Comprobamos que prometheus captura correctamente el endpoint a través de Traefik en http://prometheus.localhost/targets o http://localhost:9090/targets sin usar Treafik. Deberíamos ver los Jobs
kafka-brokersykafka-controllerscon los tres contenedores de cada uno en estado UP (verde).
- También podemos comprobar que los datos de kafka se capturan correctamente desde Prometheus buscando
kafka.
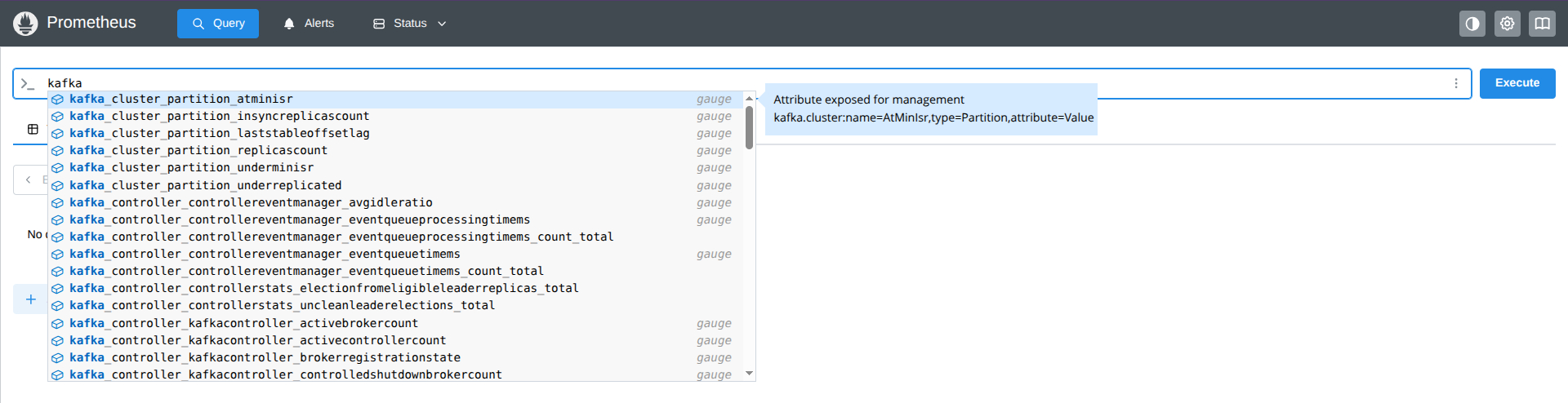
- También podemos comprobar que los datos de kafka se capturan correctamente desde Prometheus buscando
kafka.
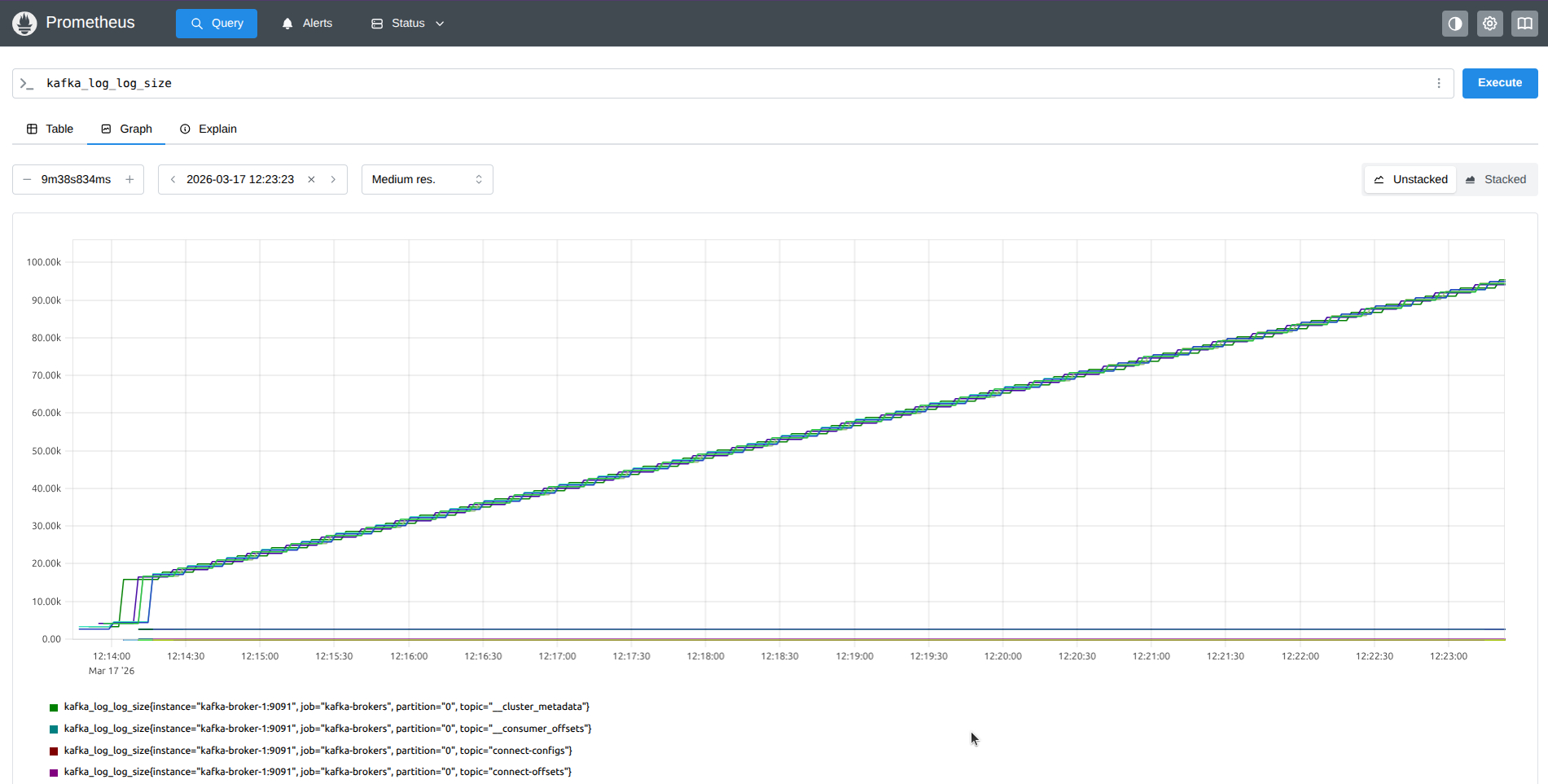
8. El "Consumer Lag". Una métrica crítica de Kafka¶
En el ecosistema Kafka, no sólo son importantes las métricas de la CPU o la memoria de los Brokers. Una métrica muy importante para tener controlada la producción y eficiencia de tu kafka es el Consumer Lag (Retraso del Consumidor).
8.1 ¿Qué es el Consumer Lag?¶
El Lag es la diferencia matemática entre:
- Log End Offset: La posición del último mensaje que un Productor ha escrito en un Topic.
- Current Offset: La posición del último mensaje que un Grupo de Consumidores ha leído (y confirmado).
Si el Productor escribe 100 mensajes por segundo, pero tu aplicación en Python (Consumidor) solo es capaz de procesar 50 mensajes por segundo, el Lag empezará a crecer. Los datos se acumularán sin procesar, generando retrasos en tu pipeline analítico.
8.2 JMX y Kafka Exporter para medir el Lag¶
Podrías pensar: "Si ya tenemos el agente JMX inyectado en la JVM de los Brokers, ¿por qué no le pedimos el Lag?"
El problema es que el Lag no es una métrica interna del Broker. Es un cálculo relacional entre la velocidad de un productor externo y un consumidor externo. El Broker almacena las posiciones (Offsets), pero calcular el Lag en tiempo real para cientos de grupos de consumidores consumiría demasiada CPU de la máquina virtual de Kafka.
Para esta casuhística, una de las soluciones más extendidas es el uso de una herramienta de código abierto llamada Kafka Exporter (danielqsj/kafka-exporter): https://github.com/danielqsj/kafka_exporter.
Es un microservicio ligero (escrito en Go) que actúa como un cliente externo: se conecta al clúster, lee matemáticamente las posiciones de los topics y de los consumidores, calcula el Lag exacto, y expone una métrica robusta (kafka_consumergroup_lag) para que Prometheus la recolecte.
8.3 Integración de Kafka Exporter en Docker Compose¶
Vamos a añadir esta pieza clave a nuestra arquitectura de monitorización. Añadimos el siguiente servicio a nuestro docker-compose.yml:
# --- CALCULADOR DE LAG (Kafka Exporter) ---
kafka-exporter:
image: danielqsj/kafka-exporter:latest
container_name: kafka-exporter
restart: on-failure
networks:
- bda-network
# Le pasamos la lista de nuestros brokers internos
command:
- "--kafka.server=kafka-broker-1:9092"
- "--kafka.server=kafka-broker-2:9092"
- "--kafka.server=kafka-broker-3:9092"
ports:
- "9308:9308" # Puerto donde expone las métricas a Prometheus
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
8.4 Configurar Prometheus para leer el Exporter¶
Prometheus necesita saber que existe un nuevo objetivo (Target) al que preguntar.
Edita tu archivo monitoring/prometheus.yml y añade un nuevo Job al final:
# ... (Jobs de kafka) ...
# Scrape del calculador de Lag
- job_name: "kafka-exporter"
static_configs:
- targets: ["kafka-exporter:9308"]
Aplica los cambios reiniciando los servicios de monitorización:
8.5 Docker compose y prometheus completo¶
networks:
bda-network:
driver: bridge
name: bda-network
volumes:
namenode_data:
secondary_namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
portainer_data:
#postgres_data: # Persistencia del catálogo
spark_master_logs:
spark_worker1_logs:
spark_worker2_logs:
spark_worker3_logs:
kafka_controller_1_data:
kafka_controller_2_data:
kafka_controller_3_data:
kafka_broker_1_data:
kafka_broker_2_data:
kafka_broker_3_data:
prometheus_data:
grafana_data: {}
services:
# --- INFRAESTRUCTURA DEVOPS ---
# --- TRAEFIK: Reverse Proxy y Gestor de Rutas ---
# Traefik actúa como el único punto de entrada (puerta de enlace) para nuestro cluster.
# Su función es interceptar todas las peticiones HTTP (en el puerto 80) y, basándose
# en el dominio solicitado (ej. 'portainer.localhost'), redirigir el tráfico al
# contenedor correcto de forma automática. Esto nos evita tener que gestionar y recordar
# un puerto diferente para cada servicio. El dashboard en el puerto 8089 nos permite
# ver las rutas que ha descubierto y si están activas.
#Si quiere añadirlo a más servicios, usa la etiqueta 'labels' para definir las reglas de Traefik, como está en portainer y namenode
traefik:
image: traefik:v3.6.2
container_name: traefik
command:
- "--api.insecure=true" # Habilita el dashboard inseguro para desarrollo
- "--providers.docker=true" # Escucha eventos de Docker
- "--providers.docker.exposedbydefault=false" # Seguridad: No exponer nada automáticamente
- "--entrypoints.web.address=:80" # Punto de entrada HTTP estándar
ports:
- "80:80" # Peticiones HTTP del host
- "8089:8080" # Dashboard de administración de Traefik
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Traefik necesita acceso al socket de Docker
networks:
- bda-network
# --- PORTAINER: Interfaz Gráfica para Docker ---
# Portainer nos da una UI web para gestionar de forma visual nuestros contenedores,
# imágenes, redes y volúmenes, facilitando la administración del entorno Docker.
#
# Este servicio está configurado para ser accesible de dos maneras:
# 1. Acceso Directo: A través del puerto 9000 (http://localhost:9000). Esto es gracias
# a la sección 'ports'. Es un acceso fiable y directo.
# 2. Acceso vía Traefik: Las 'labels' definen la regla para acceder por el dominio
# http://portainer.localhost. Esto permite unificar el acceso a todos los servicios
# bajo el mismo proxy inverso, usando nombres amigables en lugar de puertos
portainer:
image: portainer/portainer-ce:latest
container_name: portainer
networks:
- bda-network
ports:
# Mapeo de puertos directo: <PUERTO_EN_EL_HOST>:<PUERTO_EN_EL_CONTENEDOR>
# Exponemos la UI de Portainer (puerto 9000) en el puerto 9010 de nuestra máquina para evitar conflictos con el 9000 del namenode
- "9010:9000"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro" # Acceso al socket de Docker
- portainer_data:/data # Volumen para persistir la data de Portainer
command: -H unix:///var/run/docker.sock
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla: si el host es 'portainer.localhost', reenvía a este servicio
- "traefik.http.routers.portainer.rule=Host(`portainer.localhost`)"
# Definimos el punto de entrada (entrypoint) como 'web' (puerto 80)
- "traefik.http.routers.portainer.entrypoints=web"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9000)
- "traefik.http.services.portainer.loadbalancer.server.port=9000"
# --- SERVICIOS BIG DATA (Con etiquetas Traefik) ---
# --- CAPA DE ALMACENAMIENTO (HDFS) ---
namenode:
image: apache/hadoop:3.4.1
container_name: namenode
hostname: namenode
user: root
networks:
bda-network:
aliases:
- cluster-bda # Alias for the namenode service. Para que así pueda resolver docker. Docker registra ese nombre de host en la red.
ports:
- "9870:9870" # UI Web
env_file:
- ./hadoop.env
#environment:
# Esta variable formatea el NameNode si la carpeta está vacía
#- ENSURE_NAMENODE_DIR="/opt/hadoop/hadoop_data/hdfs/namenode"
volumes:
- namenode_data:/opt/hadoop/hadoop_data/hdfs/namenode
#command: ["hdfs", "namenode"]
command:
- "/bin/bash"
- "-c"
- "if [ ! -d /opt/hadoop/hadoop_data/hdfs/namenode/current ]; then echo '--- FORMATTING NAMENODE (FRESH START) ---'; hdfs namenode -format -nonInteractive; else echo '--- NAMENODE DATA FOUND (NO FORMAT) ---'; fi; hdfs namenode"
labels:
# Activamos Traefik para este contenedor
- "traefik.enable=true"
# Regla de enrutamiento: responder a namenode.localhost
- "traefik.http.routers.namenode.rule=Host(`namenode.localhost`)"
# IMPORTANTE: Decirle a Traefik cuál es el puerto interno del servicio web (9870)
- "traefik.http.services.namenode.loadbalancer.server.port=9870"
secondary_namenode:
image: apache/hadoop:3.4.1
container_name: secondary_namenode
hostname: secondary_namenode
user: root
networks:
- bda-network
ports:
- "9868:9868"
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- secondary_namenode_data:/opt/hadoop/hadoop_data/hdfs/secondary_namenode
command: ["hdfs", "secondarynamenode"]
datanode1:
image: apache/hadoop:3.4.1
container_name: datanode1
hostname: datanode1
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode1_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode2:
image: apache/hadoop:3.4.1
container_name: datanode2
hostname: datanode2
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode2_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
datanode3:
image: apache/hadoop:3.4.1
container_name: datanode3
hostname: datanode3
user: root
networks:
- bda-network
env_file:
- ./hadoop.env
depends_on:
- namenode
volumes:
- datanode3_data:/opt/hadoop/hadoop_data/hdfs/datanode
command: ["hdfs", "datanode"]
# --- CAPA DE PROCESAMIENTO (YARN) ---
resourcemanager:
image: apache/hadoop:3.4.1
container_name: resourcemanager
hostname: resourcemanager
user: root
networks:
- bda-network
ports:
- "8088:8088" # YARN ResourceManager Web UI
- "8032:8032" # YARN ResourceManager RPC
env_file:
- ./hadoop.env
depends_on:
- namenode
command: ["yarn", "resourcemanager"]
labels:
- "traefik.enable=true"
- "traefik.http.routers.resourcemanager.rule=Host(`yarn.localhost`)"
- "traefik.http.services.resourcemanager.loadbalancer.server.port=8088"
# NodeManager asociado a DataNode1
nodemanager1:
image: apache/hadoop:3.4.1
container_name: nodemanager1
hostname: nodemanager1
user: root
networks:
- bda-network
ports:
- "8042:8042" # Puerto único para la Web UI del NM1
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode2
nodemanager2:
image: apache/hadoop:3.4.1
container_name: nodemanager2
hostname: nodemanager2
user: root
networks:
- bda-network
ports:
- "8043:8042" # Puerto único para la Web UI del NM2
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# NodeManager asociado a DataNode3
nodemanager3:
image: apache/hadoop:3.4.1
container_name: nodemanager3
hostname: nodemanager3
user: root
networks:
- bda-network
ports:
- "8044:8042" # Puerto único para la Web UI del NM3
env_file:
- ./hadoop.env
depends_on:
- resourcemanager
- namenode
command: ["yarn", "nodemanager"]
# --- CAPA DE PERSISTENCIA RELACIONAL (Catalog Database) ---
#postgres:
# image: postgres:18
# container_name: postgres
# networks:
# - bda-network
# environment:
# POSTGRES_DB: metastore_db
# POSTGRES_USER: hive
# POSTGRES_PASSWORD: hive_password
# # Le decimos a Postgres dónde poner los datos exactamente (Necesario para Postgres 18+)
# PGDATA: /var/lib/postgresql/data/pgdata
# volumes:
# - postgres_data:/var/lib/postgresql/data
# # healthcheck declara una verificación que se ejecuta para determinar si los contenedores de servicio están "healthy" o no.
# healthcheck:
# test: ["CMD-SHELL", "pg_isready -U hive -d metastore_db"]
# interval: 10s
# timeout: 5s
# retries: 5
# --- SERVICIO DE METADATOS (Hive Metastore) ---
#metastore:
# image: apache/hive:standalone-metastore-4.2.0
# container_name: metastore
# networks:
# - bda-network
# environment:
# SERVICE_NAME: metastore
# # Credenciales explícitas para el script de inicio de la imagen
# DB_DRIVER: postgres
# # Configuración JAVA directa (Sin XMLs intermedios para la DB)
# SERVICE_OPTS: >-
# -Xmx1G
# -Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver
# -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://postgres:5432/metastore_db
# -Djavax.jdo.option.ConnectionUserName=hive
# -Djavax.jdo.option.ConnectionPassword=hive_password
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# postgres:
# # Establece la condición bajo la cual se considera satisfecha la dependencia (https://docs.docker.com/reference/compose-file/services/#depends_on)
# condition: service_healthy
# namenode:
# condition: service_started
# ports:
# - "9083:9083" # Puerto Thrift expuesto para clientes externos
# volumes:
# # Inyección del Driver postgres y librerias YARN (Fix SystemClock Error)
# - ./drivers/postgresql-42.7.8.jar:/opt/hive/lib/postgresql-jdbc.jar
# # --- NUEVOS PARCHES PARA YARN (Fix SystemClock Error) ---
# - ./drivers/hadoop-yarn-common-3.4.1.jar:/opt/hive/lib/hadoop-yarn-common-3.4.1.jar
# - ./drivers/hadoop-yarn-api-3.4.1.jar:/opt/hive/lib/hadoop-yarn-api-3.4.1.jar
# --- MOTOR DE EJECUCIÓN SQL (HiveServer2) ---
#hiveserver2:
# image: apache/hive:4.2.0
# container_name: hiveserver2
# networks:
# - bda-network
# environment:
# SERVICE_NAME: hiveserver2
# TEZ_CONTAINER_SIZE: 512 # Ajuste de memoria para contenedores Tez
# # Evita re-inicializar el esquema (ya lo hace el metastore)
# IS_RESUME: "true"
# # Configuración: Conéctate al metastore remoto y usa HDFS
# SERVICE_OPTS: >-
# -Dhive.metastore.uris=thrift://metastore:9083
# -Dhive.metastore.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse
# -Dfs.defaultFS=hdfs://namenode:9000
# depends_on:
# metastore:
# condition: service_started
# resourcemanager:
# condition: service_started
# ports:
# - "10000:10000" # Puerto JDBC (Beeline/DBeaver)
# - "10002:10002" # Web UI de HiveServer2
# labels:
# - "traefik.enable=true"
# # Acceso HTTP a la UI de Hive
# - "traefik.http.routers.hive.rule=Host(`hive.localhost`)"
# - "traefik.http.services.hive.loadbalancer.server.port=10002"
# - "traefik.http.routers.hive.entrypoints=web"
# # Desactivando el paso de la cabecera Host (passHostHeader = false).
# # Le decimos a Traefik que NO pase el nombre de dominio original al contenedor.
# # Así, Traefik reescribirá la cabecera Host para que coincida con la IP interna del contenedor y el puerto 10002.
# # Esto evita que Jetty de error en hiveserver2 por recibir tráfico del puerto 80.
# - "traefik.http.services.hive.loadbalancer.passhostheader=false"
# -------------------------------------------
# --- MOTOR DE PROCESAMIENTO (Spark) ---
# APACHE SPARK (COMPUTE LAYER)
# Versión: 4.0.1 (Official Docker Image)
# Arquitectura: Standalone Mode (1 Master + 3 Workers)
# -------------------------------------------
spark-master:
image: spark:4.0.1
container_name: spark-master
hostname: spark-master
user: root # Necesario para escribir logs en volúmenes
networks:
- bda-network
ports:
- "7077:7077" # Puerto RPC (Necesario para enviar trabajos desde fuera)
- 8080:8080 # Puerto Web UI
volumes:
- spark_master_logs:/opt/spark/logs
labels:
- "traefik.enable=true"
- "traefik.http.routers.spark.rule=Host(`spark.localhost`)"
- "traefik.http.services.spark.loadbalancer.server.port=8080"
- "traefik.http.routers.spark.entrypoints=web"
# Arrancamos la clase Master directamente
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.master.Master", "--host", "spark-master", "--port", "7077", "--webui-port", "8080"]
spark-worker-1:
image: spark:4.0.1
container_name: spark-worker-1
hostname: spark-worker-1
user: root
networks:
- bda-network
#environment:
# --- GESTIÓN DE RECURSOS ---
# Spark detecta nativamente estas variables al arrancar la JVM.
#- SPARK_WORKER_MEMORY=1G # Límite de RAM por Worker
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker1_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-2:
image: spark:4.0.1
container_name: spark-worker-2
hostname: spark-worker-2
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker2_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
spark-worker-3:
image: spark:4.0.1
container_name: spark-worker-3
hostname: spark-worker-3
user: root
networks:
- bda-network
#environment:
#- SPARK_WORKER_MEMORY=1G
# - SPARK_WORKER_CORES=1 # Descomentar para limitar CPU
volumes:
- spark_worker3_logs:/opt/spark/logs
depends_on:
- spark-master
- namenode
# Arrancamos la clase Worker apuntando al Master
command: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.worker.Worker", "--webui-port", "8081", "spark://spark-master:7077"]
# -------------------------------------------
# SPARK CONNECT SERVER (Gateway para Clientes Remotos)
# Este servicio permite conectar IDEs (VSCode/PyCharm) desde el Host
# -------------------------------------------
spark-connect:
image: spark:4.0.1
container_name: spark-connect
hostname: spark-connect
user: root
networks:
- bda-network
ports:
- "15002:15002" # Puerto gRPC expuesto al Host
- "4040:4040" # WebUI de este Driver específico
depends_on:
- spark-master
- namenode
labels:
# Exponemos la UI del Driver de Spark Connect
- "traefik.enable=true"
- "traefik.http.routers.spark-connect-ui.rule=Host(`spark-connect.localhost`)"
- "traefik.http.services.spark-connect-ui.loadbalancer.server.port=4040"
- "traefik.http.routers.spark-connect-ui.entrypoints=web"
# Arrancamos el servidor de Spark Connect conectándose al Master
command:
- "/opt/spark/bin/spark-submit"
- "--master"
- "spark://spark-master:7077"
- "--class"
- "org.apache.spark.sql.connect.service.SparkConnectServer"
- "--name"
- "SparkConnectServer"
- "--conf"
- "spark.driver.bindAddress=0.0.0.0"
# --- Límites para evitar Starvation si no tienes recursos suficientes ---
# Limitamos a 1 núcleo en total (deja libres los otros para tus jobs)
- "--conf"
- "spark.cores.max=1"
# Limitamos la memoria por ejecutor (deja RAM libre en los workers)
- "--conf"
- "spark.executor.memory=512m"
# ---------------------------------------------
# Importante: Las librerías de Connect suelen venir en la imagen,
# pero apuntamos al paquete local por seguridad en la carga de clases.
# Añadimos también la librería de Kafka separada por coma del paquete de Connect para Spark Streaming con Kafka
- "--packages"
- "org.apache.spark:spark-connect_2.13:4.0.1,org.apache.spark:spark-sql-kafka-0-10_2.13:4.0.1"
# -------------------------------------------
# APACHE KAFKA (STREAMING LAYER)
# Arquitectura: 3 Controllers + 3 Brokers (KRaft Isolated)
# -------------------------------------------
kafka-controller-1:
image: apache/kafka:4.2.0
container_name: kafka-controller-1
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
# Limitamos RAM para entornos de laboratorio
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-2:
image: apache/kafka:4.2.0
container_name: kafka-controller-2
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-controller-3:
image: apache/kafka:4.2.0
container_name: kafka-controller-3
user: root
networks:
- bda-network
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx256M -Xms256M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
volumes:
- kafka_controller_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-1:
image: apache/kafka:4.2.0
container_name: kafka-broker-1
user: root
networks:
- bda-network
ports:
- "9094:9094" # Puerto mapeado al Host
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-1:9092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
# --- INYECCIÓN DEL AGENTE JMX ---
# Le decimos a Java que cargue el agente en el puerto 9091 usando el archivo de reglas
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_1_data:/tmp/kafka-logs
# Montamos la carpeta local en el contenedor en modo lectura
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-2:
image: apache/kafka:4.2.0
container_name: kafka-broker-2
user: root
networks:
- bda-network
ports:
- "9095:9095"
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9095
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-2:9092,EXTERNAL://localhost:9095
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_2_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
kafka-broker-3:
image: apache/kafka:4.2.0
container_name: kafka-broker-3
user: root
networks:
- bda-network
ports:
- "9096:9096"
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: PLAINTEXT://:9092,EXTERNAL://:9096
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-broker-3:9092,EXTERNAL://localhost:9096
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka-controller-1:9093,2@kafka-controller-2:9093,3@kafka-controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CLUSTER_ID: MkU3OEVBNTcwNTJENDM2Qk
KAFKA_JVM_PERFORMANCE_OPTS: "-Xmx512M -Xms512M"
KAFKA_OPTS: "-javaagent:/opt/kafka/jmx/jmx_prometheus_javaagent-1.5.0.jar=9091:/opt/kafka/jmx/kafka-jmx.yml"
depends_on:
- kafka-controller-1
- kafka-controller-2
- kafka-controller-3
volumes:
- kafka_broker_3_data:/tmp/kafka-logs
- ./monitoring/jmx:/opt/kafka/jmx:ro
# --- OBSERVABILIDAD (Kafbat UI) ---
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
container_name: kafka-ui
networks:
- bda-network
environment:
# Nombre que aparecerá en la interfaz
KAFKA_CLUSTERS_0_NAME: bda-cluster
# Apuntamos a los puertos INTERNOS de los brokers en Docker
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Habilitamos la configuración dinámica desde la propia UI (muy útil en Labs)
DYNAMIC_CONFIG_ENABLED: 'true'
# Le dice a la aplicación Spring Boot que respete las cabeceras que le envía Traefik
SERVER_FORWARD_HEADERS_STRATEGY: FRAMEWORK
# Le inyectamos el worker directamente. La UI lo auto-descubrirá.
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: cluster-conectores
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-worker-1:8083
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
labels:
# Integración con nuestro Traefik
- "traefik.enable=true"
- "traefik.http.routers.kafkaui.rule=Host(`kafka.localhost`)"
- "traefik.http.services.kafkaui.loadbalancer.server.port=8080"
- "traefik.http.routers.kafkaui.entrypoints=web"
# --- CLIENTE KAFKA (Edge Node) ---
# Usado exclusivamente para administrar el clúster sin afectar a los brokers
kafka-client:
image: apache/kafka:4.2.0
container_name: kafka-client
networks:
- bda-network
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
# Comando para mantener el contenedor vivo
command: tail -f /dev/null
# --- Kafka Connect ---
# =======================================================
# PLANTILLA BASE PARA KAFKA CONNECT (YAML Anchor)
# Definimos toda la configuración común para no repetirla
# =======================================================
x-connect-defaults: &connect-defaults
image: apache/kafka:4.2.0
networks:
- bda-network
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092
# Mismo Group ID une los workers en un solo clúster
CONNECT_GROUP_ID: bda-connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "true"
CONNECT_PLUGIN_PATH: /opt/kafka/plugins
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
volumes:
- ./kafka_connect_plugins:/opt/kafka/plugins:ro
# Inyección directa del driver MySQL (Asegúrate de tenerlo en esa ruta)
- ./kafka_connect_plugins/drivers/mysql-connector-j-9.6.0.jar:/opt/kafka/libs/mysql-connector-j.jar:ro
command:
- bash
- -c
- |
echo "bootstrap.servers=$$CONNECT_BOOTSTRAP_SERVERS" > /tmp/connect-distributed.properties
echo "group.id=$$CONNECT_GROUP_ID" >> /tmp/connect-distributed.properties
echo "key.converter=$$CONNECT_KEY_CONVERTER" >> /tmp/connect-distributed.properties
echo "value.converter=$$CONNECT_VALUE_CONVERTER" >> /tmp/connect-distributed.properties
echo "key.converter.schemas.enable=$$CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "value.converter.schemas.enable=$$CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE" >> /tmp/connect-distributed.properties
echo "offset.storage.topic=connect-offsets" >> /tmp/connect-distributed.properties
echo "offset.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "config.storage.topic=connect-configs" >> /tmp/connect-distributed.properties
echo "config.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "status.storage.topic=connect-status" >> /tmp/connect-distributed.properties
echo "status.storage.replication.factor=3" >> /tmp/connect-distributed.properties
echo "plugin.path=$$CONNECT_PLUGIN_PATH" >> /tmp/connect-distributed.properties
echo "Iniciando Kafka Connect en modo distribuido..."
/opt/kafka/bin/connect-distributed.sh /tmp/connect-distributed.properties
# -------------------------------------------
# KAFKA CONNECT CLUSTER (3 Workers)
# Heredan de la plantilla base (<<: *connect-defaults)
# -------------------------------------------
kafka-worker-1:
<<: *connect-defaults
container_name: kafka-worker-1
ports:
- "8083:8083" # API REST Worker 1
kafka-worker-2:
<<: *connect-defaults
container_name: kafka-worker-2
ports:
- "8084:8083" # API REST Worker 2 (Mapeado al 8084 del Host)
kafka-worker-3:
<<: *connect-defaults
container_name: kafka-worker-3
ports:
- "8085:8083" # API REST Worker 3 (Mapeado al 8085 del Host)
# -------------------------------------------
# Monitoring con Prometheus
# -------------------------------------------
prometheus:
image: prom/prometheus:v3.5.1
container_name: prometheus
networks:
- bda-network
ports:
- "9090:9090" # Acceso directo a la UI de Prometheus
volumes:
# Inyectamos nuestra configuración
- ./monitoring/prometheus.yml:/etc/prometheus/prometheus.yml:ro
# Persistencia de métricas
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
labels:
# --- ENRUTAMIENTO TRAEFIK ---
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`prometheus.localhost`)"
- "traefik.http.services.prometheus.loadbalancer.server.port=9090"
- "traefik.http.routers.prometheus.entrypoints=web"
# --- DASHBOARDS VISUALES ---
grafana:
image: grafana/grafana
container_name: grafana
restart: unless-stopped
networks:
- bda-network
ports:
- "3000:3000" # Acceso a la UI de Grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin # Contraseña por defecto
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
labels:
# Opcional: Integración con Traefik
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`grafana.localhost`)"
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
- "traefik.http.routers.grafana.entrypoints=web"
# --- KAFKA EXPORTER (Calculador de Lag de Consumidores) ---
kafka-exporter:
image: danielqsj/kafka-exporter:latest
container_name: kafka-exporter
restart: on-failure
networks:
- bda-network
command:
- "--kafka.server=kafka-broker-1:9092"
- "--kafka.server=kafka-broker-2:9092"
- "--kafka.server=kafka-broker-3:9092"
ports:
- "9308:9308" # Puerto donde expone las métricas
depends_on:
- kafka-broker-1
- kafka-broker-2
- kafka-broker-3
Prometheus completo¶
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
# Monitorización de nuestros 3 Brokers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-brokers"
static_configs:
- targets:
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Monitorización de nuestros 3 Controllers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-controllers"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- job_name: "kafka"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Scrape del calculador de Lag
- job_name: "kafka-exporter"
static_configs:
- targets: ["kafka-exporter:9308"]
Reinicia los servicios para aplicar los cambios:¶
9. Configuración de Grafana¶
-
Toda la documentación de Grafana OSS la tenemos en su página oficial
-
Descarga e instala la última versión de Grafana.
sudo apt-get install -y adduser libfontconfig1 musl
wget https://dl.grafana.com/enterprise/release/grafana-enterprise_11.6.1_amd64.deb
sudo dpkg -i grafana-enterprise_11.6.1_amd64.deb
- Inicia Grafana
Grafana como servicio
Si quieres habilitar grafana para que arranque automáticamente usando systemd, ejecuta:
-
Accedemos a su WebUI en el puerto
3000http://localhost:3000, en nuestro casohttp://192.168.56.10:3000/desde el host -
Entramos con las credenciales usuario
adminy passadmin. Cámbiala a tu criterio.
-
Vamos a añadir los datos de monitorización de Kafka (Recuerda tener levantado kafka y prometheus)
-
Vamos a
Connections -> Data sources -> Add data source
- Elegimos Prometheus y añadimos la configuración
http://localhost:9090
- Marcamos "Save & test"
-
Ahora necesitamos crear un dashboard para monitorizar visualmente los datos en tiempo real. Podemos crearlos nosotros manualmente, o usar algunas ya creados para importarlos. Puedes consultar dashboard en la página oficial de dashboards de grafana. Elegimos el que más nos interese de kafka
-
Si queremos elegir uno sólo habría que añadir el ćodigo identificador. Para que veamos como sería cargar uno, usaremos como ejemplo este o este
-
Para ello nos vamos a
Dashboards -> New -> Import
-
Cargamos el dashboard indicando el id del dashboard. En nuestro caso el
11962o18276 -
Marcamos el identificador y Load
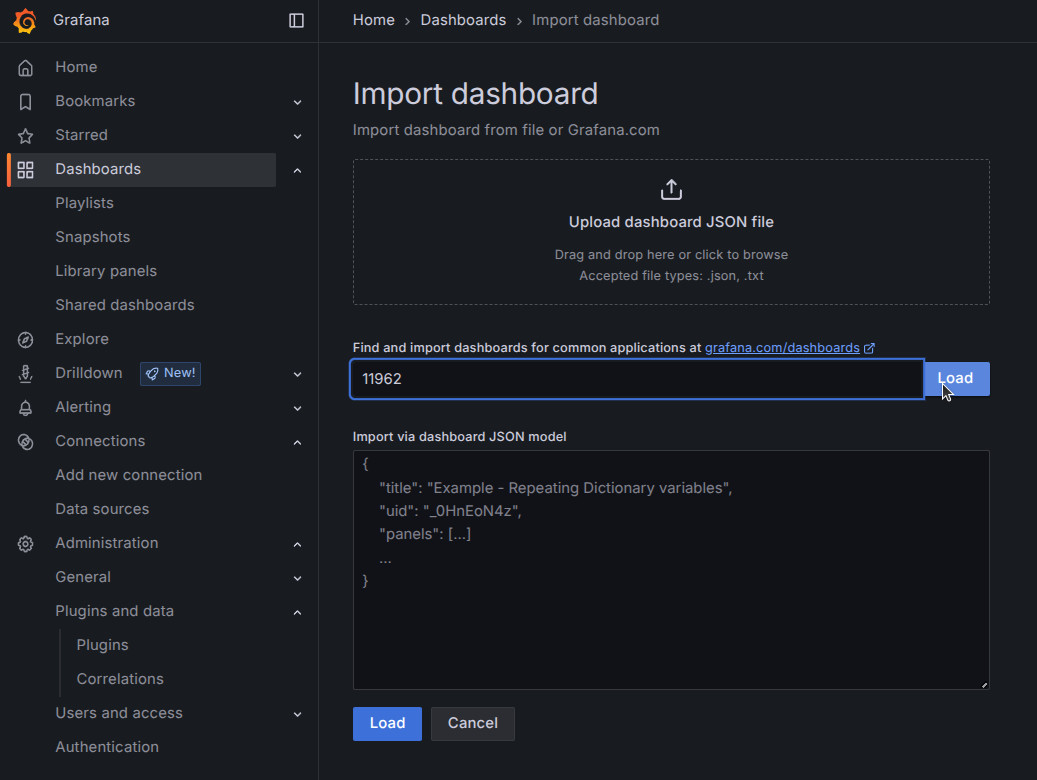
- Configuramos el dashboard. Hay que indicarle nuestro data source prometheus.
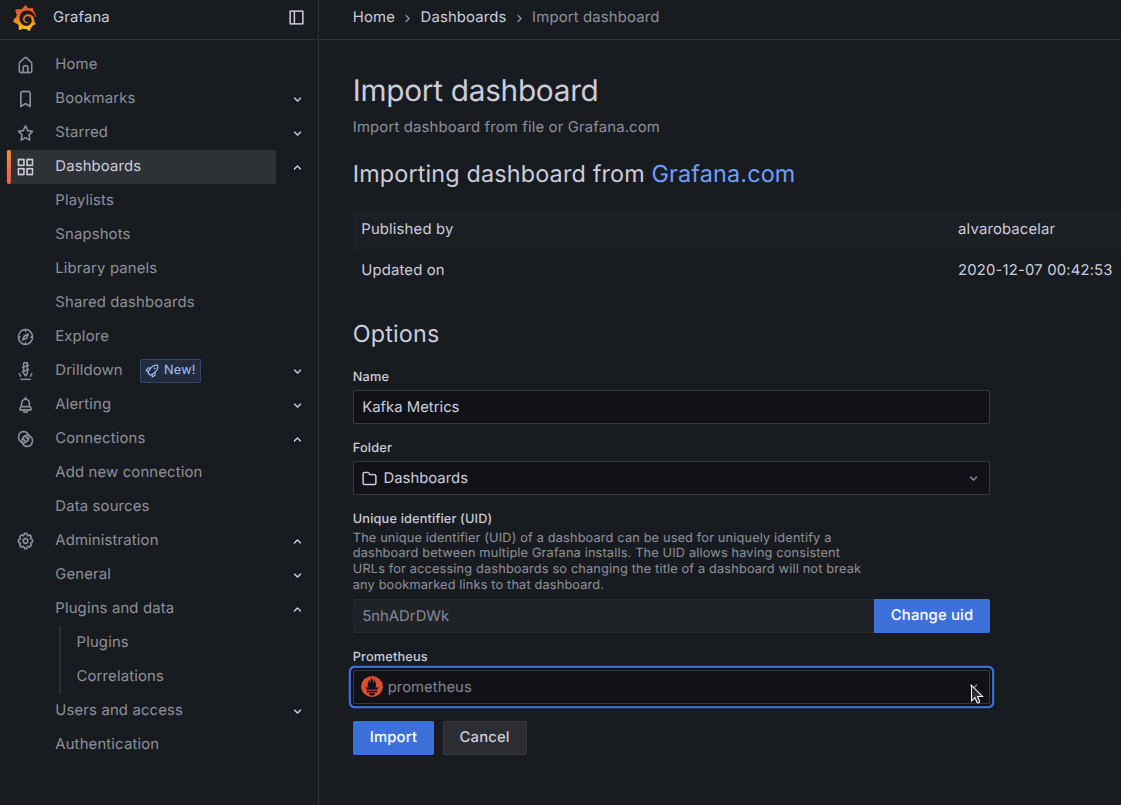
Versiones
Hay que tener en cuenta que cada dashboards está basado en unas versiones determinadas, tanto de la versión de kafka, como cual ha sido la configuración de la plantilla del scraping, si hemos usado JVM Exporter o Kafka Exporter,... (kafka-kraft-3_0_0.yml en kafka 4.0 y JMX Exporter en nuestro caso). Por tanto, ninguno de estos dashboards nos funcionaría. Pero si es interesante saber como hacerlo para cuando haya alguno o queramos usarlo para otro tipo de servicio
-
Haz lo mismo con el otro dashboard o el que quieras usar según tus necesidades.
-
Nosotros vamos a desarrollar nuestro propio dashboard. Para ver las métricas que podemos añadir, podemos verlas directamente desde prometheus. Pare ello nos vamos a
Graphhttp://192.168.56.10:9090/graph y le damos al botón deopen metrics explorerque está justo antes del botón "execute"
-
He generado un pequeño dashboard para que puedas importarlo y usarlo. Haz las modificaciones que creas oportunas. Recuerda, este dashboard está configurado y debe ser usado para nuestra configuración de JMX Exporter + Kafka 4.0 +
kafka-kraft-3_0_0.yml. Puedes descargar el json e importarlo como nuevo dashboard -
Observa la captura de como se vería para este pequeño ejemplo. Al no añadir ningún topic, consumidor,... no están completos los datos del dashboards. Este ejemplo nos sirve para ver como funcionan los dashboards y preparar una plantilla. En el siguiente ejemplo ejecutaremos un ejemplo más completo para verlo en funcionamiento.
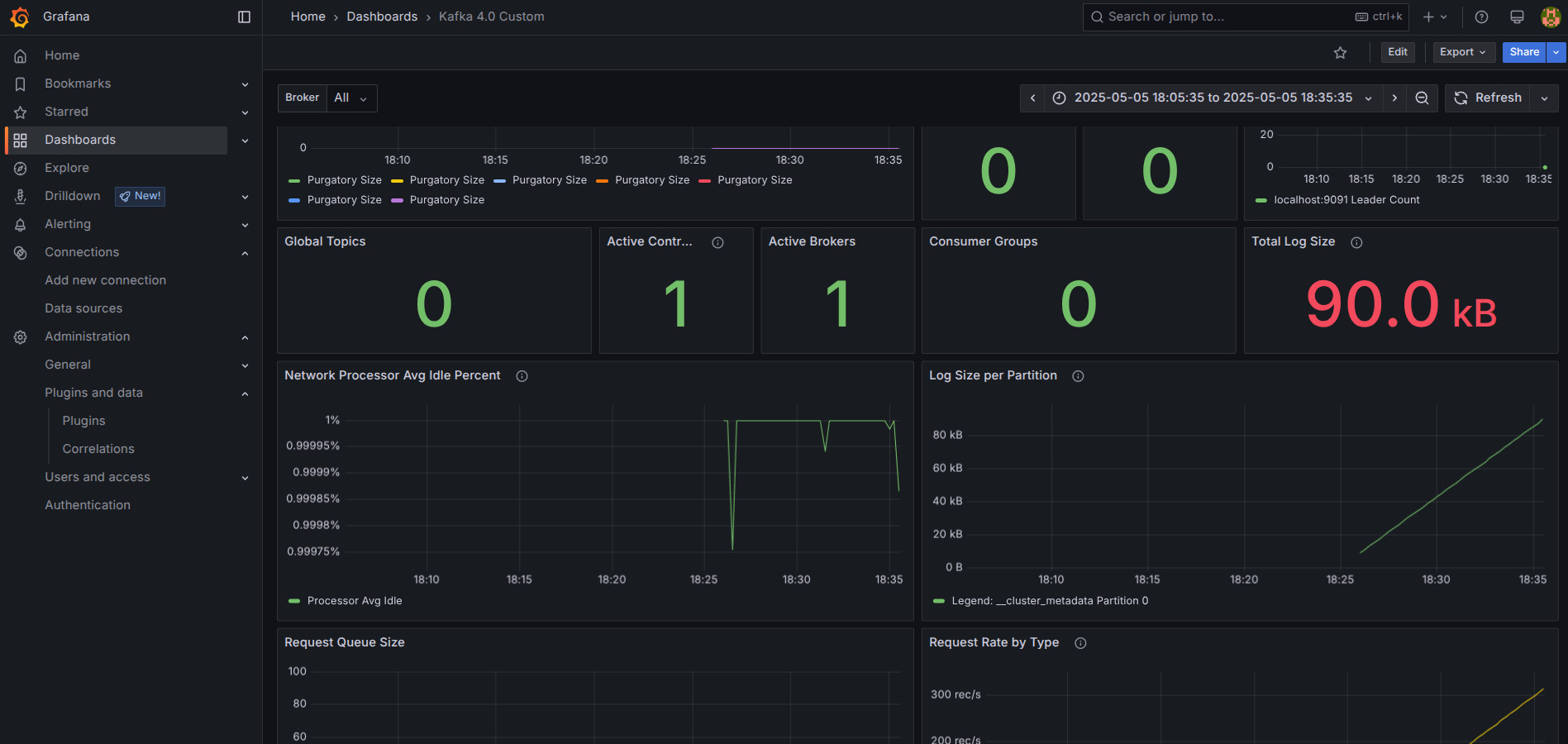
-
Toda la documentación de Grafana OSS la tenemos en su página oficial
-
Accedemos a su WebUI a través de la ruta limpia que nos proporciona Traefik: http://grafana.localhost (o alternativamente en
http://localhost:3000). -
Entramos con las credenciales por defecto: usuario
adminy contraseñaadmin. Te pedirá que la cambies por seguridad (puedes omitirlo o cambiarla a tu criterio).
9.1 Añadir Prometheus como Data Source¶
Vamos a decirle a Grafana de dónde tiene que sacar los datos (Recuerda tener levantado todo el stack: Kafka y Prometheus).
- En el menú lateral, vamos a
Connections -> Data sources -> Add data source.
- Elegimos Prometheus.
Cuidado con la URL (Concepto Docker)
En un entorno de Máquinas Virtuales pondríamos http://localhost:9090. Sin embargo, en Docker, localhost para Grafana es el propio contenedor de Grafana.
Para que Grafana se comunique con Prometheus, debemos usar el nombre del contenedor que asignamos en el docker-compose.yml, ya que Docker resuelve automáticamente los nombres a IPs internas.
- En el campo Prometheus server URL, añadimos:
http://prometheus:9090
- Bajamos hasta el final de la página y marcamos "Save & test". Debería aparecer un mensaje verde indicando que el Data Source funciona correctamente.
- Puedes ir a
Drilldown -> Metricspara comprobar que realmente se están recibiendo las métricas de Kafka. Veras todas las métricas relacionadas con Kafka que Prometheus está capturando.
9.2 Importar Dashboards¶
Ahora necesitamos crear un dashboard para monitorizar visualmente los datos en tiempo real. Podemos crearlos nosotros manualmente, o usar algunos ya creados por la comunidad para importarlos.
Puedes consultar la página oficial de dashboards de Grafana.
-
Para ver cómo se cargaría uno de la comunidad, usaremos como ejemplo los IDs
18276o24626. -
Nos vamos a
Dashboards -> New -> Import.
- Introducimos el ID del dashboard (ej.
24626o18276) y pulsamos Load.
- En el paso final, seleccionamos nuestro data source (Prometheus) en el desplegable y hacemos clic en Import.
El problema de las Versiones y los Exporters
Al importar dashboards de la comunidad, te darás cuenta de que muchos gráficos aparecen vacíos o con la etiqueta "No Data".
Hay que tener en cuenta que cada dashboard está diseñado para unas versiones determinadas (de Kafka) y, sobre todo, para un Exporter específico. Si el dashboard esperaba el Kafka Exporter y nosotros usamos el JMX Exporter con las reglas kafka-kraft-3_0_0.yml, los nombres de las métricas no coincidirán y el dashboard no funcionará. Conocer este proceso es vital para saber reciclar plantillas de otros servicios.
Además, podemos encontrarnos que que estos dashboards están llamando a job_names específicos que no coinciden con los que tenemos configurados en nuestro prometheus.yml (ej. kafka-brokers vs kafka-controllers), lo que también hará que el dashboard no funcione. O incluso siendo los mismos, en algunos casos hay que editarlos y volver a ejecututar la query para que se actualicen y muestren los datos.
9.3 Nuestro Dashboard Personalizado¶
Dado el problema de compatibilidad mencionado, nosotros vamos a utilizar un dashboard propio, diseñado específicamente para nuestro stack (Kafka 4.1.1 + KRaft + JMX Exporter).
- Para entender qué métricas estamos recibiendo realmente, podemos verlas directamente desde Prometheus. Entramos en http://prometheus.localhost/graph (gracias a Traefik) y pulsamos el botón de
Explore metrics(los 3 puntos a la izquierda del botón "Execute").
-
He generado un pequeño dashboard personalizado para nuestro laboratorio. Puedes descargar el json e importarlo usando la opción "Upload JSON file" en la misma pantalla de importación de Grafana.
-
Observa cómo se ve para nuestro ejemplo actual. Al no tener cargas masivas de datos en este instante, algunas gráficas estarán planas. En el siguiente ejemplo ejecutaremos un flujo de datos más completo (Productores y Consumidores en tiempo real) para ver cómo las métricas (Bytes In/Out, Messages per Second) cobran vida.
Recuerda
Si no se ve ningún dato, probablemente tengas que entrar en cada query y volverla a ejecutar.
10. Ejemplo 1. JMX + Prometheus + Grafana¶
Para ver grafana en funcionamiento, vamos a ejecutar el Ejemplo 3 de Kafka de la unidad anterior, donde configuramos 3 controller con 3 brokers, 1 topic junto a un consumidor y un productor.
Severs y puertos de kafka para el ejemplo
Para este caso, para poder realizar el ejemplo, tenemos 3 opciones
- Levantar un server en cada una de las máquinas que tenemos y usar el mismo puerto para JMX
- Levantar todos los servers de Kafka en una máquina y usar un puerto para cada uno de ellos
- Levantar todo el stack con docker (Se desarrollará en la siguiente Unidad)
Ambos casos tienen sus dificultades. En el primero necesitamos configurar el cluster de Kafka cada uno en un nodo, por ejemplo, en master 1 controller, y un broker en cada nodo (nodo1-> broker1, nodo2 -> broker2,..). En el segundo, el script de inicio de los servers de kafka debe tener mayor configuración, ya que debemos indicar en el script que arranque cada server en un puerto diferente.
Nosotros, elegiremos la segunda opción, así podemos establecer un ejemplo (NO EN PRODUCCIÓN) del funcionamiento de grafana con un posible cluster con quorum dinámico de varios controllers y brokers.
- Necesitamos cambiar el script de arranque de los servidores de Kafka. Para ello vamos a hacer una copia del ya existente y vamos modificarlo. Este nuevo script será el que usemos para este ejemplo.
cp /opt/kafka_2.13-4.0.0/bin/kafka-server-start.sh /opt/kafka_2.13-4.0.0/bin/kafka-server-start_ejemplo2_mon_kafka.sh
- Abrimos el script
- Sustituimos la línea de configuración de nuestro ejemplo anterior por el siguiente código. Hemos elegido los puertos
11000para exponer los datos a Prometheus. Puedes usar los que quieras
# --- INICIO DE MODIFICACIÓN PARA JMX EXPORTER ---
# Establecemos KAFKA_OPTS por defecto si no está definido
KAFKA_OPTS=${KAFKA_OPTS:-}
# Encontrar la ruta al archivo server.properties (o cualquier archivo .properties)
PROPERTIES_FILE=""
for arg in "$@"; do
if [[ "$arg" == *".properties" ]]; then
PROPERTIES_FILE="$arg"
break
fi
done
# Variables para JMX Exporter
JMX_AGENT_PATH="/opt/kafka_2.13-4.0.0/libs/jmx_prometheus_javaagent-1.2.0.jar"
# Ruta al archivo de configuración del JMX Exporter. Si no usas uno, déjala vacía pero mantén el ':' en el argumento final.
JMX_CONFIG_FILE="/opt/kafka_2.13-4.0.0/config/jmx-exporter-kafka.yml"
# Lógica para determinar el puerto y configurar KAFKA_OPTS
NODE_ID=""
JMX_PORT=""
JMX_JAVAAGENT_ARG=""
# 1. Intentar extraer node.id del archivo properties
if [ -n "$PROPERTIES_FILE" ] && [ -f "$PROPERTIES_FILE" ]; then
NODE_ID=$(grep "^[[:space:]]*node.id[[:space:]]*=" "$PROPERTIES_FILE" | head -1 | sed "s/^[[:space:]]*node.id[[:space:]]*=//" | cut -d'#' -f1 | tr -d '[:space:]')
fi
# 2. Validar NODE_ID y calcular JMX_PORT
if ! [[ "$NODE_ID" =~ ^[0-9]+$ ]]; then
echo "WARNING: JMX Exporter: No se pudo determinar el node.id del archivo $PROPERTIES_FILE o no es un número válido ('$NODE_ID')." >&2
echo "WARNING: JMX Exporter NO será cargado para esta instancia de Kafka." >&2
# 3. Validar si el JAR del JMX Exporter existe y es legible
elif [ ! -r "$JMX_AGENT_PATH" ]; then
echo "ERROR: JMX Exporter: El archivo JAR NO se encuentra o no es legible: $JMX_AGENT_PATH" >&2
echo "WARNING: JMX Exporter NO será cargado para esta instancia de Kafka." >&2
# 4. Validar si el archivo de configuración existe y es legible (si se especificó uno)
elif [ -n "$JMX_CONFIG_FILE" ] && [ ! -r "$JMX_CONFIG_FILE" ]; then
echo "ERROR: JMX Exporter: El archivo de configuración NO se encuentra o no es legible: $JMX_CONFIG_FILE" >&2
echo "WARNING: JMX Exporter NO será cargado para esta instancia de Kafka." >&2
# 5. Si todas las validaciones pasan, construir el argumento y configurar KAFKA_OPTS
else
JMX_BASE_PORT=11000 # Puerto base, JMX_PORT = JMX_BASE_PORT + NODE_ID
JMX_PORT=$((JMX_BASE_PORT + NODE_ID))
# Construir el argumento del javaagent: =puerto:/ruta/config (o =puerto:)
JMX_JAVAAGENT_ARG="-javaagent:$JMX_AGENT_PATH=$JMX_PORT"
if [ -n "$JMX_CONFIG_FILE" ]; then
JMX_JAVAAGENT_ARG="${JMX_JAVAAGENT_ARG}:${JMX_CONFIG_FILE}" # Añadir : y la ruta del archivo
else
JMX_JAVAAGENT_ARG="${JMX_JAVAAGENT_ARG}:" # Si no hay archivo, añadir solo el :
fi
# Añadir el argumento del javaagent a KAFKA_OPTS
if [ -z "$KAFKA_OPTS" ]; then
export KAFKA_OPTS="$JMX_JAVAAGENT_ARG"
else
export KAFKA_OPTS="$KAFKA_OPTS $JMX_JAVAAGENT_ARG" # Añadir un espacio antes por si ya hay opciones
fi
echo "DEBUG: JMX Exporter: Configurado en puerto $JMX_PORT para node.id=$NODE_ID." >&2
echo "DEBUG: JMX Exporter: KAFKA_OPTS resultante: '$KAFKA_OPTS'" >&2
fi
# --- FIN DE MODIFICACIÓN PARA JMX EXPORTER ---
- Hacemos una copia del fichero de configuración
prometheus.ymlpara adaptarlo a esta configuración.
- Abrimos el archivo de configuración
- Añadimos los diferentes scrapings. La configuración de los endpoint a partir del puerto 11000.
- job_name: "kafka"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: [
"localhost:11001", # Controller 1 (node.id=1)
"localhost:11002", # Controller 2 (node.id=2)
"localhost:11003", # Controller 3 (node.id=3)
"localhost:11005", # Broker 1 (node.id=5)
"localhost:11006", # Broker 2 (node.id=6)
"localhost:11007" # Broker 3 (node.id=7)
]
- El resultado sería.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "kafka"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: [
"localhost:11001", # Controller 1 (node.id=1)
"localhost:11002", # Controller 2 (node.id=2)
"localhost:11003", # Controller 3 (node.id=3)
"localhost:11005", # Broker 1 (node.id=5)
"localhost:11006", # Broker 2 (node.id=6)
"localhost:11007" # Broker 3 (node.id=7)
]
-
Arrancamos el ejemplo
-
Generamos los uuid
#Generamos un cluster UUID y los IDs de los controllers
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_1_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_2_UUID="$(bin/kafka-storage.sh random-uuid)"
CONTROLLER_3_UUID="$(bin/kafka-storage.sh random-uuid)"
#Formateamos los directorios de log indicando los controllers iniciales
#sudo rm -r /opt/kafka/ejemplo3/logs/*
#controller1
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller1.properties
#controller2
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller2.properties
#controller3
bin/kafka-storage.sh format --cluster-id ${KAFKA_CLUSTER_ID} \
--initial-controllers "1@localhost:9096:${CONTROLLER_1_UUID},2@localhost:9097:${CONTROLLER_2_UUID},3@localhost:9098:${CONTROLLER_3_UUID}" \
--config /opt/kafka/ejemplo3/config/controller3.properties
- Damos formato a los logs de los brokers
#Formateamos los directorios de log de los brokers
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker1.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker2.properties
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka/ejemplo3/config/broker3.properties
- Iniciamos los servers(3 controllers y 3 brokers) cada uno en una terminal
#Ejecutamos los servidores Kafka (uno en cada terminal)
#Observa en el log al arrancar que indica que Levanta JMX y el puerto correspondiente al node.id
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/controller1.properties
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/controller2.properties
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/controller3.properties
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/broker1.properties
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/broker2.properties
bin/kafka-server-start_ejemplo2_mon_kafka.sh /opt/kafka/ejemplo3/config/broker3.properties
- Comprobamos que se ha expuesto correctamente el endpoint en
1100*:
tcp LISTEN 0 3 *:11006 *:* users:(("java",pid=11101,fd=115)) uid:1000 ino:39171 sk:4 cgroup:/user.slice/user-1000.slice/session-1.scope v6only:0 <->
tcp LISTEN 0 3 *:11007 *:* users:(("java",pid=11562,fd=115)) uid:1000 ino:40394 sk:5 cgroup:/user.slice/user-1000.slice/session-7.scope v6only:0 <->
tcp LISTEN 0 3 *:11005 *:* users:(("java",pid=10685,fd=115)) uid:1000 ino:38804 sk:6 cgroup:/user.slice/user-1000.slice/session-3.scope v6only:0 <->
tcp LISTEN 0 3 *:11002 *:* users:(("java",pid=9819,fd=115)) uid:1000 ino:37271 sk:7 cgroup:/user.slice/user-1000.slice/session-5.scope v6only:0 <->
tcp LISTEN 0 3 *:11003 *:* users:(("java",pid=10266,fd=115)) uid:1000 ino:38499 sk:8 cgroup:/user.slice/user-1000.slice/session-4.scope v6only:0 <->
tcp LISTEN 0 3 *:11001 *:* users:(("java",pid=9428,fd=115)) uid:1000 ino:38008 sk:9 cgroup:/user.slice/user-1000.slice/session-2.scope v6only:0 <->
tcp LISTEN 0 50 [::ffff:127.0.0.1]:9093 *:* users:(("java",pid=11101,fd=156)) uid:1000 ino:39338 sk:c cgroup:/user.slice/user-1000.slice/session-1.scope v6only:0 <->
tcp LISTEN 0 50 *:36061 *:* users:(("java",pid=11101,fd=120)) uid:1000 ino:39174 sk:e cgroup:/user.slice/user-1000.slice/session-1.scope v6only:0 <->
- Iniciamos Prometheus. Vamos a su directorio
/opt/prometheus-2.53.4. Levantamos prometheus
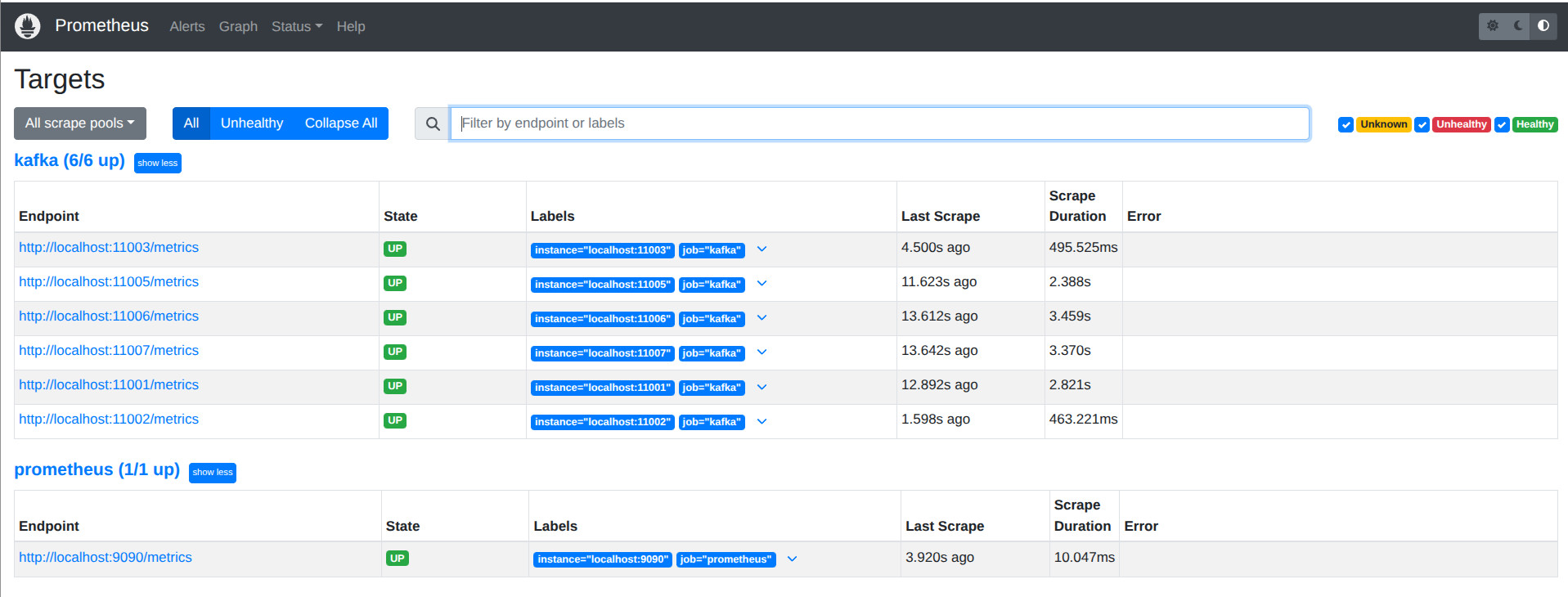
- Iniciamos Grafana
- Creamos el topic con factor de replica 3 y 3 particiones. El topic debe conectarse a un broker.
bin/kafka-topics.sh --create --topic financial-transactions --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3
- Podemos ver la descripción del topic creado
bin/kafka-topics.sh --describe --topic financial-transactions --bootstrap-server localhost:9092
Topic: financial-transactions TopicId: MjtMKW06RNyR0aZWDOiTdg PartitionCount: 3 ReplicationFactor: 3Configs: segment.bytes=1073741824
Topic: financial-transactionsPartition: 0 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7 Elr: LastKnownElr:
Topic: financial-transactionsPartition: 1 Leader: 6 Replicas: 6,7,5 Isr: 6,7,5 Elr: LastKnownElr:
Topic: financial-transactionsPartition: 2 Leader: 7 Replicas: 7,5,6 Isr: 7,5,6 Elr: LastKnownElr:
- Comprobamos el dashboard de Grafana
- Lanzamos el productor
- Lanzamos el consumidor
Para ver grafana en funcionamiento, vamos a usar como base el Ejemplo 3 de Kafka de la unidad anterior, pero en esta ocasión, usaremos ya nuestro stack completo con Docker (Kafka + Prometheus + Grafana).
- Asegúrate de que todo tu
docker-composeestá levantado. Primero, usaremos nuestro contenedor cliente (kafka-client) para crear el topic de forma segura, sin interferir en los brokers.
docker exec -it kafka-client /opt/kafka/bin/kafka-topics.sh \
--create --topic financial-transactions \
--bootstrap-server kafka-broker-1:9092 \
--replication-factor 3 --partitions 3
- Como estamos haciendo habitualmente, vamos a ejecutar nuestro script de productor y consumidor en nuestro host, como clientes externos. Por tanto, necesitamos preparar el entorno para que puedan comunicarse con el cluster de Kafka que tenemos levantado en Docker.
# Navegamos al directorio base de nuestros ejemplos
cd kafka_ejemplos
# Si o lo has hecho ya, creamos el entorno virtual
python -m venv venv
# Activamos el entorno
# Linux/Mac:
source venv/bin/activate
# Windows:
.\venv\Scripts\activate
# Si no lo has hecho ya, instalamos kafka-python
pip install kafka-python-ng
# Creamos el directorio del ejemplo
mkdir ejemplo1_grafana
cd ejemplo1_grafana
- Creamos el productor
from kafka import KafkaProducer
import json
import time
import random
producer = KafkaProducer(bootstrap_servers=['localhost:9094', 'localhost:9095', 'localhost:9096'],
value_serializer=lambda x: json.dumps(x).encode('utf-8'))
while True:
transaction = {
"source_account": random.randint(1000, 1999),
"destination_account": random.randint(2000, 2999),
"amount": round(random.uniform(10.00, 1000.00), 2),
"currency": "EUR",
"timestamp": time.time()
}
producer.send('financial-transactions', value=transaction)
print(f"Sent transaction: {transaction}")
time.sleep(0.1)
- Creamos el consumidor
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer('financial-transactions',
bootstrap_servers=['localhost:9094', 'localhost:9095', 'localhost:9096'],
auto_offset_reset='earliest',
group_id='python-banking-group',
# Le dice a Kafka que guarde el progreso para el cálculo del consumer lag con Kafka Exporter
enable_auto_commit=True,
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
transaction = message.value
print(f"Received transaction: {transaction}")
- Ejecutamos
kafka-console-consumer.shpara comprobar que kafka consume correctamente los mensajes generados por el productor.
docker exec -it kafka-client /opt/kafka/bin/kafka-console-consumer.sh \
--topic financial-transactions \
--bootstrap-server kafka-broker-1:9092 \
--from-beginning
- Lanzamos el productor y consumidor en terminales separadas
# recuerda tener activado el entorno virtual en esta terminal también
python producer.py
# recuerda tener activado el entorno virtual en esta terminal también
python consumer.py