UD 6 - Apache Spark - Plataformas¶
1. Databricks¶
1.1 ¿Qué es Databricks?¶
Databricks es el nombre de la plataforma analítica de datos basada en Apache Spark desarrollada por la compañía con el mismo nombre. La empresa se fundó en 2013 con los creadores y los desarrolladores principales de Spark. Permite hacer analítica Big Data e inteligencia artificial con Spark de una forma sencilla y colaborativa.
Esta plataforma está disponible como servicio cloud en Azure, AWS y Google Cloud.
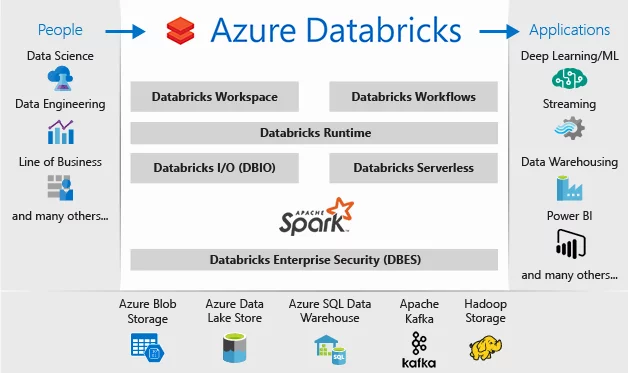
Databricks contiene muchas funcionalidades que la hacen una solución analítica bastante completa. Aun así, depende de servicios adicionales como almacenamientos externos de datos para poder convertirse en la pieza central de un sistema analítico empresarial completo como Data Warehouse o Data Lake.
Es una plataforma que permite múltiples casos de uso como procesamiento batch, streaming y machine learning.
1.2 Características de Databricks¶
Permite auto-escalar y dimensionar entornos de Apache Spark de forma sencilla en función de las necesidades. También es posible terminar automáticamente estos clústers. De esta forma, se facilitan los despliegues y se acelera la instalación y configuración de los entornos. Con la opción serverless se puede abstraer toda la complejidad alrededor de la infraestructura y obtener directamente acceso al servicio. Así se facilita su uso por equipos independientes que necesiten recursos volátiles y despliegues ad-hoc.
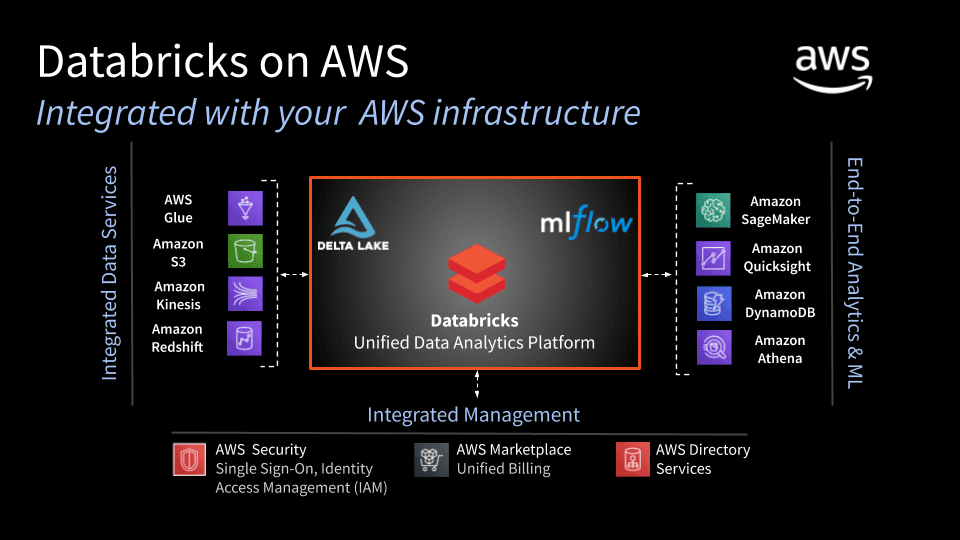
Incluye proyectos colaborativos y espacios de trabajo interactivos llamados notebooks. Estos pueden servir para desarrollar procesos y prototipos de transformación y análisis y más adelante ponerlos en producción con el planificador. Están integrados con sistemas de control de versiones como Github y Bitbucket y es posible crear directorios separados para diferentes unidades o equipos.
Databricks no es responsable de la capa de persistencia de los datos. Esto quiere decir que los datos se procesan con Spark pero antes deben estar almacenados en algún componente adicional (Azure Blob Storage, Amazon S3, ADLS (Azure Data Lake Storage), Azure SQL Data Warehouse, etc).
1.3 Databricks Community¶
Databricks community es la versión de Databricks gratuita. Permite usar un pequeño clúster con recursos limitados y notebooks no colaborativos. La versión de pago no tiene estas limitaciones y aumenta las capacidades.

Para crear una cuenta gratuita, hacemos click sobre Sign up, tras rellenar los datos personales, antes de seleccionar el proveedor cloud, en la parte inferior, hemos de pulsar sobre Get started with Community Edition:
Una vez hemos hecho login en la plataforma, nos permitirá hacer un tutorial rápido que nos explica la funcionalidad básica:
- Crear un clúster de Spark
- Asociar notebooks al clúster y ejecutar comandos
- Crear tablas de datos
- Hacer consultas y visualizar los datos
- Manipular y transformar los datos
- El primer paso es crear un nuevo serverless. Esto se puede hacer desde la pestaña clusters. Lo creamos cluster y esperamos que se despliegue.
Warning
Databricks finaliza el cluster automáticamente si no tiene actividad en 10 minutos
-
Con Databricks Community no podemos ejecutar jobs de Spark desde ficheros JAR, solamente desde notebooks.
-
Una vez desplegado el cluster, ya podemos crear un notebook (
create -> notebook) que se conecta al cluster que acabamos de desplegar. Si no lo hace automáticamente, lo seleccionamos nosotros. -
En el notebook ya tenemos acceso a Spark mediante el objeto
spark
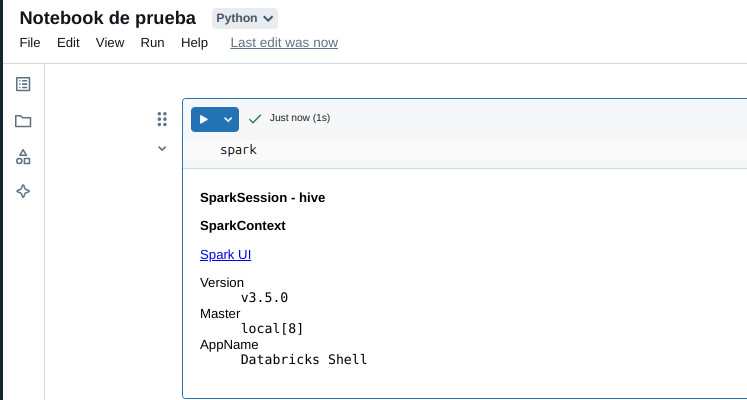
- Podemos ejecutar PySpark a través del notebook
spark
df = spark.createDataFrame([
(1, "Alice"),
(2, "Bob"),
(3, "Charlie")
], ["id", "name"])
display(df)
1.4 Limitaciones de Databricks Community¶
La filosofía de DataBricks Community ha cambiado mucho en los últimos tiempos. Anteriormente, era una plataforma bastante completa para aprender y practicar con Spark. Sin embargo, en la actualidad, presenta varias limitaciones que afectan su utilidad para el aprendizaje y la experimentación con Spark:
- Limitaciones actuales: Utiliza "Serverless Compute", lo que significa que no tienes acceso a la configuración del clúster ni a la Spark UI completa.
- Recursos limitados: El clúster tiene recursos muy limitados (CPU, memoria), lo que puede dificultar la ejecución de trabajos más complejos o con grandes volúmenes de datos.
- Uso recomendado: Ideal para probar sintaxis de PySpark rápidamente sin instalar nada, pero insuficiente para aprender ingeniería de datos profunda (no ves los logs, ni la gestión de recursos).
Por tanto, en este curso, utilizaremos nuestro Clúster Docker Local como entorno principal. Esto nos da una ventaja educativa crítica: Visibilidad Total. Podemos ver los logs de los workers, la Spark UI en el puerto 8080 y acceder al sistema de archivos HDFS, algo que la versión Community de Databricks oculta.
2. Desarrollo Interactivo: Jupyter Notebooks¶
Los Notebooks son el estándar para la exploración de datos. Permiten ejecutar código celda a celda, ver resultados inmediatos y documentar el proceso.
Gracias a la arquitectura Spark Connect (Spark 4.0+), ya no necesitamos instalar Jupyter dentro del clúster. Lo instalaremos en tu ordenador (Host) y se conectará al Docker como si fuera una base de datos remota.
Tienes dos formas de usarlo. Elige la que prefieras.
2.1 Paso Previo Común: Preparar el Entorno (Host)¶
Sea cual sea la opción que elijas, necesitamos Python y las librerías cliente en tu ordenador. Es una buena práctica usar un entorno virtual para no ensuciar tu sistema.
Abre tu terminal (PowerShell o Bash) en tu carpeta de proyecto y ejecuta:
1. Crear y Activar el Entorno Virtual:
2. Instalar Librerías:
Necesitamos jupyterlab (el entorno), pyspark-connect (el cliente de Spark) y pandas.
2.2 Opción A: Jupyter Lab Clásico (Navegador)¶
Esta es la experiencia tradicional. Se abre una pestaña en tu Chrome/Firefox/Edge con la interfaz dedicada de Jupyter.
- Instalación de Jupyter Lab:
- Arrancamos:
Desde la terminal donde tienes el venv activado:
- Acceso:
Se abrirá automáticamente el navegador en http://localhost:8888.
- Creación del Notebook:
Pulsa en el botón "Python 3 (ipykernel)" para crear un nuevo notebook .ipynb
2.3 Opción B: Jupyter integrado en VS Code (Recomendada)¶
Si ya usas VS Code, esta opción es la más potente, ya que integra tus scripts, tu terminal y tus notebooks en una sola ventana.
- Instalación de ipykernel
- Extensiones:
Asegúrate de tener instaladas las extensiones oficiales de Microsoft:
- Python
- Jupyter
- Data Wrangler (opcional, para manipulación visual de datos)
- Crear:
En VS Code, crea un archivo nuevo y llámalo analisis_spark.ipynb.
- Seleccionar Kernel (¡Importante!):
Arriba a la derecha del editor verás un botón que pone "Select Kernel" (o "Seleccionar Kernel").
- Púlsalo y selecciona Python Environments.
- Busca y selecciona el entorno
venvque creamos en el paso 2.1 (debería aparecer con una estrella o marcado como recomendado). - Recomendación: Ábre en el directorio con
code .o añádelo como Project Folder.
- Listo para Usar:
Ya puedes crear celdas y ejecutar PySpark en VS Code conectado a tu clúster Docker.
2.4 Ejemplo Práctico: Generación de Datos en Memoria¶
Para probar la conexión sin depender de ficheros externos en HDFS, vamos a pedirle a Spark que genere datos matemáticos al vuelo. Esto valida que el clúster está procesando sin riesgo de errores de "File Not Found".
Copia y pega este código en la primera celda de tu notebook y ejecútalo (Shift + Enter).
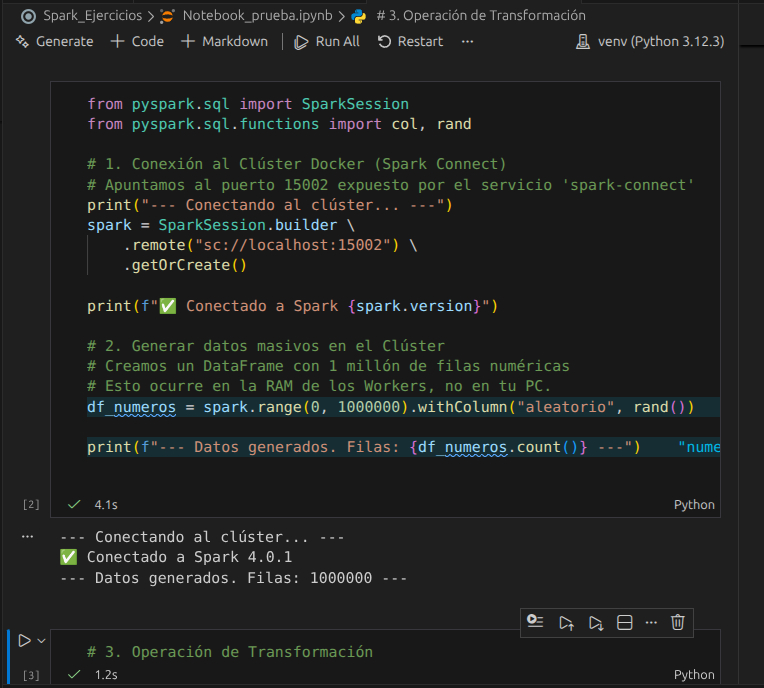
Celda 1: Conexión y Generación de Datos
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, rand
# 1. Conexión al Clúster Docker (Spark Connect)
# Apuntamos al puerto 15002 expuesto por el servicio 'spark-connect'
print("--- Conectando al clúster... ---")
spark = SparkSession.builder \
.remote("sc://localhost:15002") \
.getOrCreate()
print(f"✅ Conectado a Spark {spark.version}")
# 2. Generar datos masivos en el Clúster
# Creamos un DataFrame con 1 millón de filas numéricas
# Esto ocurre en la RAM de los Workers, no en tu PC.
df_numeros = spark.range(0, 1000000).withColumn("aleatorio", rand())
print(f"--- Datos generados. Filas: {df_numeros.count()} ---")
Celda 2: Transformación y Visualización
# 3. Operación de Transformación
# Filtramos números pares y ordenamos por el valor aleatorio
df_filtrado = df_numeros \
.filter(col("id") % 2 == 0) \
.orderBy("aleatorio")
# 4. Traer resultados al cliente (Tu Jupyter)
# .limit(5) asegura que solo traemos 5 filas por la red
# .toPandas() hace que se vea bonito en el notebook
print("--- Muestra de resultados procesados en el clúster ---")
df_filtrado.limit(5).toPandas()
2.5 Monitorización¶
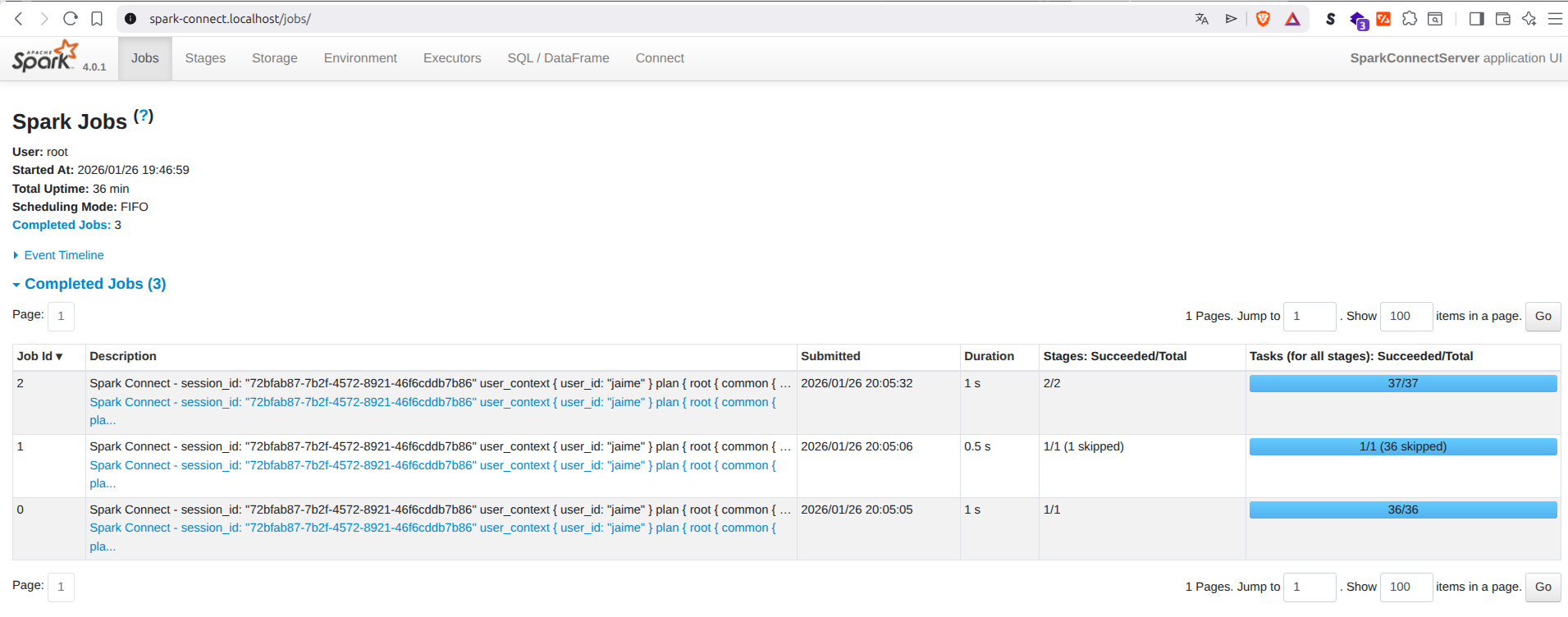
Mientras ejecutas la celda, puedes ver cómo el clúster trabaja en tiempo real. Abre en tu navegador: http://spark-connect.localhost
Verás los Jobs y Stages que tu notebook está enviando al servidor Docker.