UD 8 - Monitor Híbrido - Grafana Cloud¶
En arquitecturas corporativas modernas, es común utilizar un enfoque Híbrido (o 100% Cloud): recolectar métricas localmente y enviarlas a un servicio gestionado en la nube para almacenamiento a largo plazo y alertas globales.
En este ejercicio conectaremos nuestro Prometheus local con Grafana Cloud utilizando el estándar remote_write (Push).
1. La Realidad del Cloud: Límites y Cuotas¶
Antes de empezar, debemos entender un concepto crítico en la Ingeniería de Datos en la nube: Toda ingesta de datos tiene un coste.
Nuestro clúster Big Data (Hadoop, Spark, Kafka) genera decenas de miles de métricas por minuto. La capa gratuita (Free Tier) de Grafana Cloud impone un límite estricto de ingestión (aprox. 1500 métricas/segundo que pueden cambiar en el futuro- revisa la documentación para obtener la información más actualizada).
El Error '429 Too Many Requests'
Si intentamos enviar todas las métricas de nuestro clúster local a Grafana Cloud sin filtrar, superaremos la cuota casi instantáneamente. Prometheus registrará en sus logs el error 429 Too Many Requests y Grafana Cloud rechazará los paquetes.
Consecuencia: El dashboard en la nube no mostrará datos porque la conexión ha sido bloqueada temporalmente por el proveedor.
Solución SRE: Implementaremos dos estrategias: 1. Traffic Shaping: Enviar paquetes más pequeños y espaciados. 2. Allow-Listing (Lista Blanca): Filtrar y enviar exclusivamente las métricas que utilizan nuestros Dashboards, descartando el resto.
2. Requisitos en Grafana Cloud¶
-
Creamos una cuenta gratuita en Grafana Cloud.
-
Accedemos al portal y navegamos a la sección "Details" de nuestro grafana cloud stack/instance.
-
Aquí deberíamos ver las lista de servicios disponibles. Para este ejercicio, nos centraremos en Prometheus.
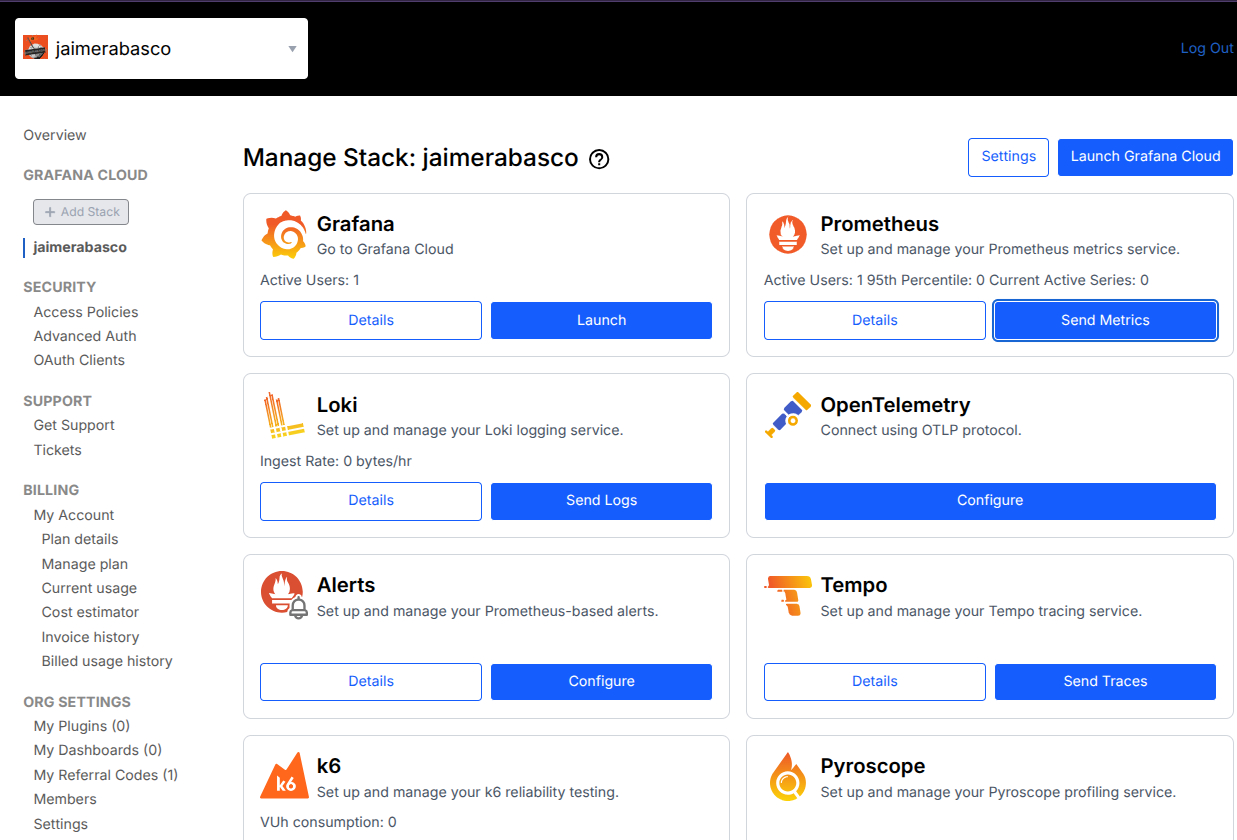
- Aquí veras información de como debemos configurar la conexión de Prometheus para enviar las métricas a nuestra grafana cloud(además de como ya hacíamos a nuestro Grafafa OSS)
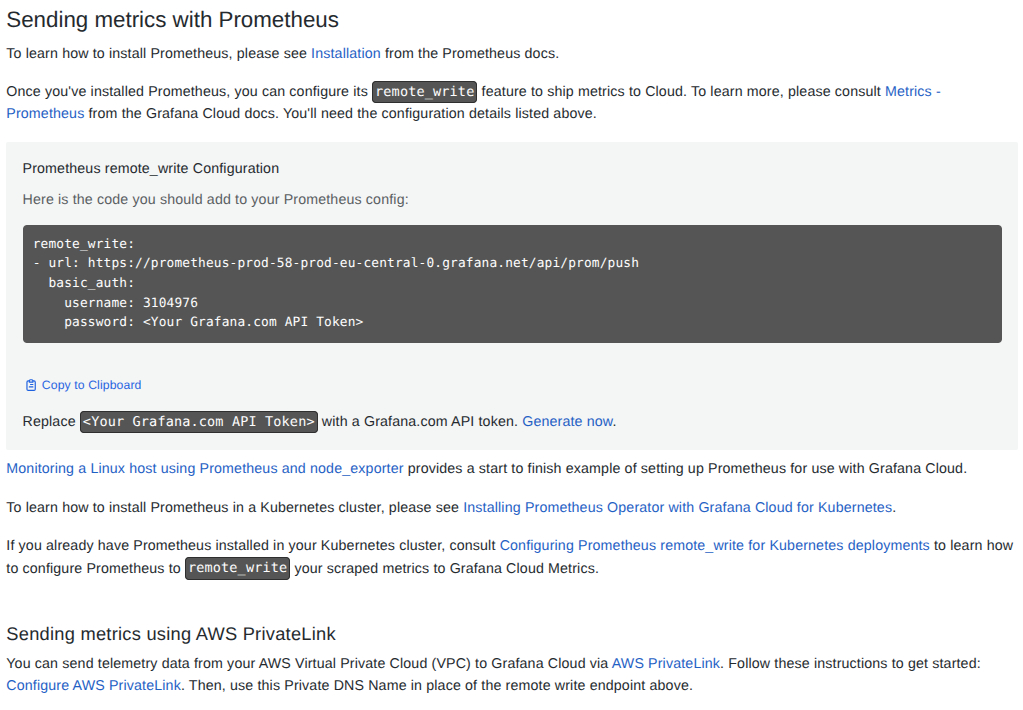
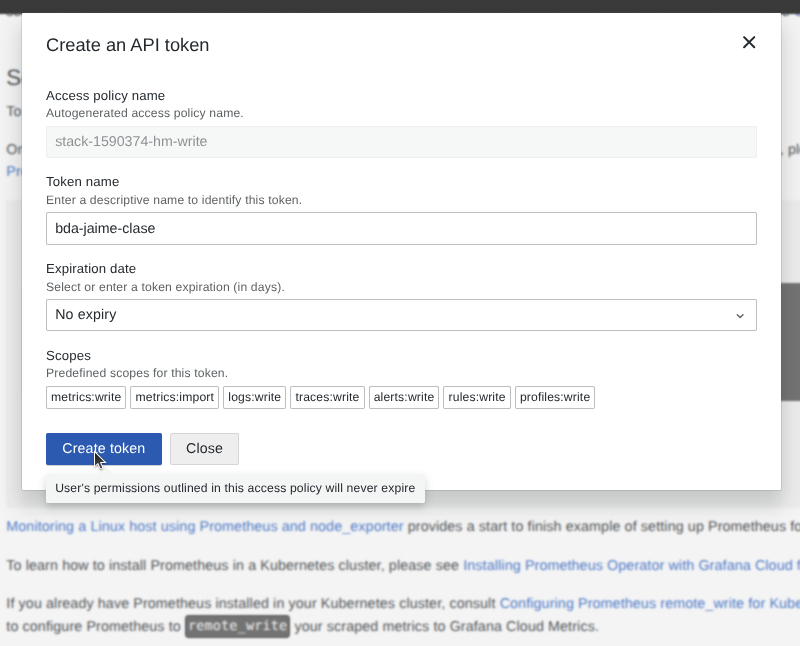
- Obtén tus credenciales de escritura:
- Remote Write Endpoint URL
- Username
- Password / API Token (Necesitarás generar un Token con permisos de
metrics:write). Generalas usando el enlace de la documentación de Grafana CloudGenerate now.
3. Configuración de Prometheus para Grafana Cloud¶
Abre tu archivo local monitoring/prometheus.yml y añade este bloque remote_write en la parte superior. Reemplaza las credenciales por las tuyas.
global:
scrape_interval: 15s
evaluation_interval: 15s
# --- CONEXIÓN A GRAFANA CLOUD ---
remote_write:
- url: "<TU_REMOTE_WRITE_ENDPOINT_URL>"
basic_auth:
username: "<TU_USERNAME_O_INSTANCE_ID>"
password: "<TU_API_TOKEN>"
# 1. Traffic Shaping: Troceamos el envío para no saturar el límite
queue_config:
max_samples_per_send: 500
max_shards: 5
batch_send_deadline: 5s
# 2. Allow-List: Filtramos estrictamente qué viaja a la nube
write_relabel_configs:
- source_labels:[__name__]
# Regex estricto con las métricas exactas de nuestros Dashboards
regex: '^(up|kafka_controller_kafkacontroller_.*|kafka_server_replicamanager_.*|kafka_server_brokertopicmetrics_.*|kafka_log_log_size|kafka_network_requestchannel_requestqueuesize|kafka_network_requestmetrics_.*|kafka_network_socketserver_networkprocessoravgidlepercent|kafka_coordinator_group_groupmetadatamanager_.*|hadoop_namenode_numlivedatanodes|hadoop_namenode_missingblocks|hadoop_namenode_capacityused|hadoop_namenode_capacitytotal|hadoop_namenode_totalfiles|hadoop_namenode_blocks_total|hadoop_datanode_bytesread|hadoop_datanode_byteswritten|jvm_memory_bytes_used|metrics_master_aliveWorkers_Value|metrics_worker_coresUsed_Value|metrics_worker_memUsed_MB_Value)$'
action: keep
# --- SCRAPE CONFIGS (Se mantienen igual) ---
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets:["localhost:9090"]
# ... (resto de tus jobs) ...
Por tanto, nuestro prometheus.yml completo debería verse así. (Recuerda incluir las credenciales y token que has obtenido de tu cuenta de Grafana Cloud):
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# --- Conexión a Grafana Cloud ---
remote_write:
- url: <TU_REMOTE_WRITE_ENDPOINT_URL>
basic_auth:
username: <TU_USERNAME_O_INSTANCE_ID>
password: <TU_API_TOKEN>
queue_config:
# Enviar en bloques de 500 para no superar el límite de 1500 de Grafana Cloud
max_samples_per_send: 500
# Limitar la concurrencia para no superar las 75 peticiones/s
max_shards: 5
# Enviar los datos más frecuentemente para vaciar la cola
batch_send_deadline: 5s
# Allow-List: Filtramos estrictamente qué viaja a la nube
write_relabel_configs:
- source_labels: [__name__]
# Regex estricto con las métricas exactas de nuestros Dashboards
regex: '^(up|kafka_controller_kafkacontroller_.*|kafka_server_replicamanager_.*|kafka_server_brokertopicmetrics_.*|kafka_log_log_size|kafka_network_requestchannel_requestqueuesize|kafka_network_requestmetrics_.*|kafka_network_socketserver_networkprocessoravgidlepercent|kafka_coordinator_group_groupmetadatamanager_.*|hadoop_namenode_numlivedatanodes|hadoop_namenode_missingblocks|hadoop_namenode_capacityused|hadoop_namenode_capacitytotal|hadoop_namenode_totalfiles|hadoop_namenode_blocks_total|hadoop_datanode_bytesread|hadoop_datanode_byteswritten|jvm_memory_bytes_used|metrics_master_aliveWorkers_Value|metrics_worker_coresUsed_Value|metrics_worker_memUsed_MB_Value)$'
action: keep
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"
# Monitorización de nuestros 3 Brokers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-brokers"
static_configs:
- targets:
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Monitorización de nuestros 3 Controllers de Kafka
# Prometheus usará el DNS interno de Docker para encontrar estos contenedores
- job_name: "kafka-controllers"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- job_name: "kafka"
static_configs:
- targets:
- "kafka-controller-1:9091"
- "kafka-controller-2:9091"
- "kafka-controller-3:9091"
- "kafka-broker-1:9091"
- "kafka-broker-2:9091"
- "kafka-broker-3:9091"
# Scrape del calculador de Lag
- job_name: "kafka-exporter"
static_configs:
- targets: ["kafka-exporter:9308"]
# Monitorización de nuestro Clúster de Spark
# Scrape del Spark Master
- job_name: "spark-master"
metrics_path: '/metrics/master/prometheus'
static_configs:
- targets:
- "spark-master:8080"
# Scrape de los Spark Workers
- job_name: "spark-workers"
metrics_path: '/metrics/prometheus'
static_configs:
- targets:
- "spark-worker-1:8081"
- "spark-worker-2:8081"
- "spark-worker-3:8081"
# Scrape del Cerebro de HDFS (NameNode)
- job_name: "hadoop-namenode"
static_configs:
- targets: ["namenode:9091"]
# Scrape del Cerebro de HDFS (NameNode)
- job_name: "hadoop-secondarynamenode"
static_configs:
- targets: ["secondary_namenode:9091"]
# Scrape de los Discos de HDFS (DataNodes)
- job_name: "hadoop-datanodes"
static_configs:
- targets:
- "datanode1:9091"
- "datanode2:9091"
- "datanode3:9091"
4. Purgado del Backlog de Prometheus¶
Backlog de Prometheus
Prometheus guarda un historial local de todo lo que recolecta. Si reiniciamos Prometheus ahora, intentará enviar todo su historial acumulado a Grafana Cloud de golpe, provocando un bloqueo inmediato por exceso de cuota por el Free tier.
Para poder probar nuestra integración, debemos destruir el volumen de Prometheus para que nazca vacio y empiece a enviar solo las métricas filtradas desde el minuto cero.
Aún así, veremos que rápidamente en los logs de Prometheus aparecen errores 429 Too Many Requests, ya que al tener tantas métricas como tenemos y un free tier tan pequeño, se verán rápidamente bloqueadas. Pero como prueba de concepto y para que veamos como sería, creo que es suficiente.
Ejecutamos estos comandos en tu terminal para purgar la base de datos de métricas:
# 1. Apagamos Prometheus
docker-compose stop prometheus
# 2. Eliminamos su contenedor y, muy importante, su volumen (-v)
docker-compose rm -f -v prometheus
# Si el volumen persiste como externo, bórralo manualmente:
# docker volume rm <nombre_de_tu_proyecto>_prometheus_data
# 3. Levantamos Prometheus limpio
docker-compose up -d prometheus
Podemos verificar que no hay errores 429 de límite de cuota leyendo los logs:
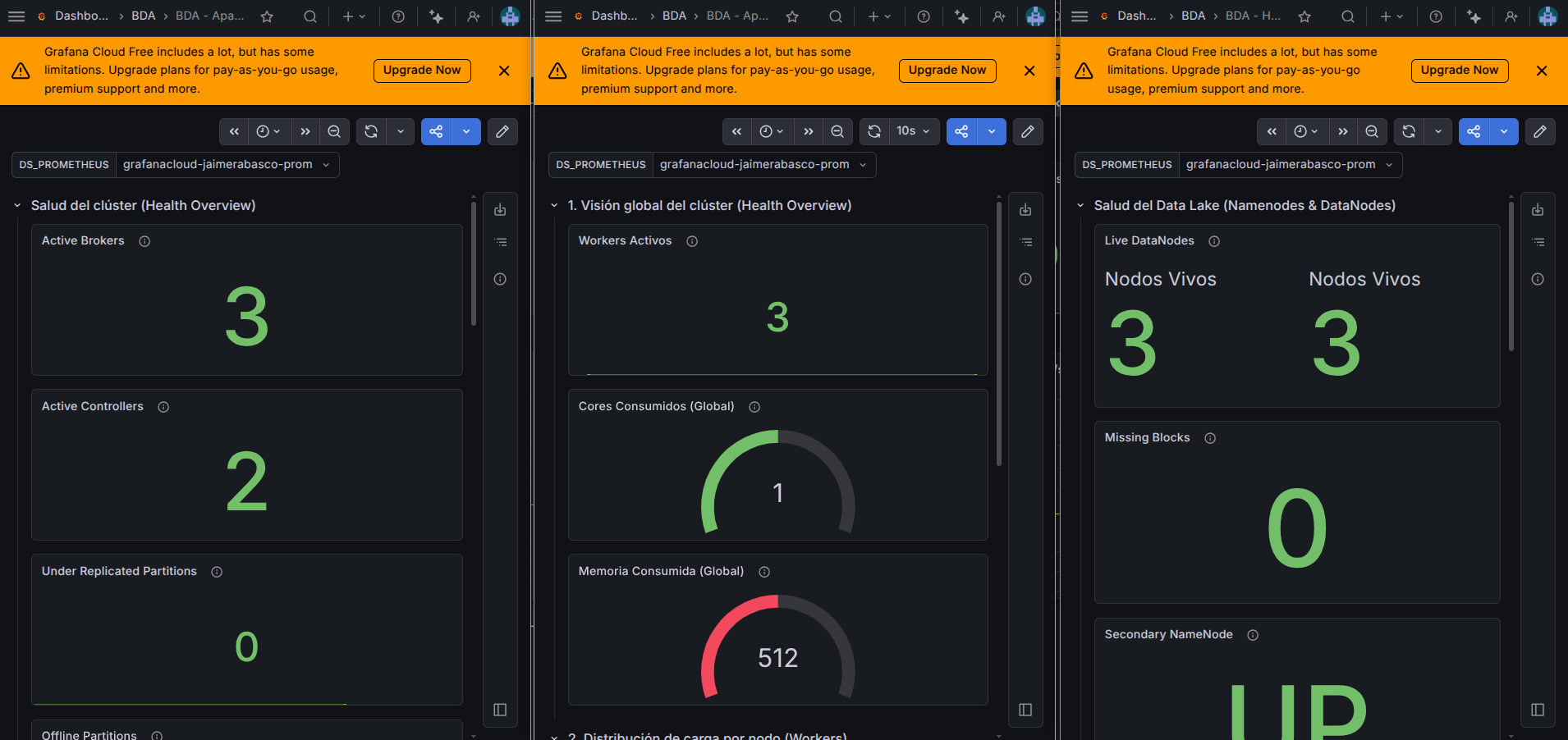
5. Visualización en Grafana Cloud¶
Los datos locales ya deberían estar subidos a la nube, pero ahora debemos importar nuestros Dashboards para visualizarlos.
-
Entra en tu instancia de Grafana Cloud.
-
Ve a Dashboards -> New -> Import.
-
Sube los archivos JSON de los Dashboards que creamos en los apartados anteriores (
Kafka_Custom.json,HDFS_Custom.json, etc.). -
Pulsa Import.
-
Cuando te solicite mapear la variable
${DS_PROMETHEUS}, selecciona el Data Source que viene configurado por defecto en Grafana Cloud (suele llamarsegrafanacloud-tu_usuario-prom).
Verás tus paneles iluminarse con los datos de tu clúster Docker local.
Aviso sobre la Prueba de Concepto
Dado que estamos enviando datos de una arquitectura distribuida muy densa (14 JVMs), más pronto que tarde, será normal que el Free Tier de Grafana Cloud alcance su límite en poco tiempo, provocando que las gráficas dejen de actualizarse y aparezcan errores 429 en el log local.
Esta práctica es una prueba de concepto educativa diseñada para demostrar cómo se configura una arquitectura Edge-to-Cloud, no para mantenerla operativa 24/7 sin un plan de pago comercial.