UD 6 - Apache Spark - Spark Cluster¶
En esta sección configuraremos un clúster Spark completo sobre nuestras Máquinas Virtuales (VMs) existentes, integrándolo con Hadoop HDFS.
1. Instalación¶
Requisito de Java (Actualización Spark 4.x)
Apache Spark 4.1.1 requiere Java 17 o superior. Java 8 y 11 ya no son soportados. Dado que en nuestro clúster Hadoop ya actualizamos a Java 21 para soportar Hive 4.2.0, estamos cubiertos. Si no lo has hecho:
- En primer lugar nos vamos a la página de descarga de Apache Spark y la descargamos. Ten en cuenta que hay varias opciones.
- Apache spark con hadoop incluido
- Apache spark con hadoop incluido con Scala
- Apache spark sin hadoop (lo proporcionamos nosotros)
- Source code
Instalamos la opción 3, ya que tenemos nuestra Hadoop ya instalado y configurado.
- Descomprimimos
- Movemos el directorio a nuestro directorio
$HADOOP_HOMEpara una correcta organización
- Accedemos a los "templates" de configuración que nos proporciona Apache Spark. Accedemos a directorio
confde Spark y ejecutamos los siguientes comandos
cp fairscheduler.xml.template fairscheduler.xml
cp log4j2.properties.template log4j2.properties
cp metrics.properties.template metrics.properties
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
cp workers.template workers
- Para añadir Apache Spark a Apache Hadoop necesitamos incluir los paquetes jar de Hadoop. Para ello entramos en
conf/spark-env.shy añadimos las siguientes líneas (Observa todas las variables de configuración que tiene Spark):
Warning
En la versión actual, aunque tengamos correctamente configurada la variable de entorno para ejecutar el comando hadoop debemos poner la ruta completa en la siguiente configuración para que funcione correctamente
# If 'hadoop' binary is on your PATH
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.4.2/bin/hadoop classpath)
- Creamos las variables de entorno necesarias. Para ello abrimos el archivo
~/.bashrcy añadimos al final el siguiente código y ejecuta el comandosource ~/.bashrc
export SPARK_HOME=/opt/hadoop-3.4.2/spark-4.1.1
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export PATH=$PATH:$SPARK_HOME/bin
Spark Path - comandos y shell scripts
Apache Spark tiene 2 directorios de archivos de ejecución:
$SPARK_HOME/bin: Comandos propios de Spark$SPARK_HOME/sbin: Shell Scripts propios de Spark
Puedes añadir, como hacemos normalmente, en el PATH los 2 directorios. Pero en este caso, hay comandos que tienen el mismo nombre que los de Apache Hadoop en $SPARK_HOME/sbin, como por ejemplo start-all.sh. Nosotros no la añadiremos para evitar problemas. Si añadimos $SPARK_HOME/binque no entran en ningún conflicto. Por tanto, para ejecutar los Shell script de Spark, debemos tener en cuenta la ruta completa de los comandos: $SPARK_HOME/sbin. Si aún así prefieres añadirlo al PATH añadimos la siguiente línea en el archivo ~/.bashrc después de las del punto anterior source ~/.bashrc
Success
No olvides tener iniciado Apache Hadoop start-dfs.sh
- Iniciamos Spark en el master con el script
./sbin/start-master.shque se encuentra en$SPARK_HOME
#Desde $SPARK_HOME
./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/hadoop-3.4.2/spark-4.1.1/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-master.out
Ya tenemos Spark iniciado en el master. También se levanta un WebUI en el puerto 8080

Para para Spark, ejecutamos el script ./sbin/stop-master.sh
2. Quick Start¶
2.1 Análisis interactivo con la Shell de Spark¶
-
Para comprobar el correcto funcionamiento de Spark, vamos a abrir una shell interactiva para trabajar en consola con Spark, que proporciona una forma sencilla de aprender la API, así como una poderosa herramienta para analizar datos de forma interactiva.
-
Creamos un nuevo conjunto de datos a partir del texto del archivo README en el directorio fuente de Spark
$SPARK_HOME:
Iniciamos
....
26/01/16 13:24:13 INFO Utils: Successfully started service 'SparkUI' on port 4040.
26/01/16 13:24:13 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
26/01/16 13:24:13 INFO ResourceProfile: Limiting resource is cpu
26/01/16 13:24:13 INFO ResourceProfileManager: Added ResourceProfile id: 0
26/01/16 13:24:13 INFO SecurityManager: Changing view acls to: hadoop
26/01/16 13:24:13 INFO SecurityManager: Changing modify acls to: hadoop
26/01/16 13:24:13 INFO SecurityManager: Changing view acls groups to: hadoop
26/01/16 13:24:13 INFO SecurityManager: Changing modify acls groups to: hadoop
26/01/16 13:24:13 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: hadoop groups with view permissions: EMPTY; users with modify permissions: hadoop; groups with modify permissions: EMPTY; RPC SSL disabled
26/01/16 13:24:14 INFO Executor: Starting executor ID driver on host cluster-bda
26/01/16 13:24:14 INFO Executor: OS info Linux, 6.8.0-88-generic, amd64
26/01/16 13:24:14 INFO Executor: Java version 21.0.9+10-Ubuntu-124.04
26/01/16 13:24:14 INFO Executor: Starting executor with user classpath (userClassPathFirst = false): ''
26/01/16 13:24:14 INFO Executor: Using REPL class URI: spark://cluster-bda:45477/classes
26/01/16 13:24:14 INFO Executor: Created or updated repl class loader org.apache.spark.executor.ExecutorClassLoader@6441db2c for default.
26/01/16 13:24:14 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 38089.
26/01/16 13:24:14 INFO NettyBlockTransferService: Server created on cluster-bda:38089
26/01/16 13:24:14 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
26/01/16 13:24:14 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, cluster-bda, 38089, None)
26/01/16 13:24:14 INFO BlockManagerMasterEndpoint: Registering block manager cluster-bda:38089 with 434.4 MiB RAM, BlockManagerId(driver, cluster-bda, 38089, None)
26/01/16 13:24:14 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, cluster-bda, 38089, None)
26/01/16 13:24:14 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, cluster-bda, 38089, None)
Spark context Web UI available at http://cluster-bda:4040
Spark context available as 'sc' (master = local[*], app id = local-1768569853873).
Spark session available as 'spark'.
scala>
scala> val textFile = spark.read.textFile("file:///opt/hadoop-3.4.2/spark-4.1.1/README.md")
....
val textFile: org.apache.spark.sql.Dataset[String] = [value: string]
Puedes obtener valores del Dataset directamente, llamando a algunas acciones o transformar el Dataset para obtener uno nuevo. Para obtener más detalles, consulta documentación de la API.
scala> textFile.count() // Número de items en este Dataset
...
val res0: Long = 166
scala> textFile.first() // Primer item en este Dataset
...
val res1: String = # Apache Spark
Ahora transformamos este Dataset en uno nuevo. Llamamos al filtro para devolver un nuevo Dataset con un subconjunto de los elementos del archivo.
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
val linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
Podemos encadenar transformaciones y acciones:
Salimos
Iniciamos. Sería igual si PySpark está instalado con pip en su entorno actual:
....
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 4.1.1
/_/
Using Python version 3.12.3 (main, Nov 6 2025 13:44:16)
Spark context Web UI available at http://cluster-bda:4040
Spark context available as 'sc' (master = local[*], app id = local-1768570186175).
SparkSession available as 'spark'.
>>>
Debido a la naturaleza dinámica de Python, no necesitamos que el conjunto de datos esté fuertemente tipado en Python. Como resultado, todos los Datasets en Python son Datasets[Fila], y lo llamamos DataFrame para ser coherente con el concepto de data frame en Pandas y R. Vamos a crear un nuevo DataFrame a partir del texto del archivo README en el directorio fuente de Spark:
Puedes obtener valores del DataFrame directamente, llamando a algunas acciones o transformar el DataFrame para obtener uno nuevo. Para obtener más detalles, consulta documentación de la API.
>>> textFile.count() # Número de filas en este DataFrame
...
166
>>> textFile.first() # Primer fila en este DataFrame
...
Row(value='# Apache Spark')
Ahora vamos a transformar este DataFrame en uno nuevo. Llamamos al filtro para devolver un nuevo DataFrame con un subconjunto de líneas en el archivo.
>>> linesWithSpark = textFile.filter(textFile.value.contains("Spark"))
>>> linesWithSpark.count() # Otra forma
...
20
Podemos encadenar transformaciones y acciones:
>>> textFile.filter(textFile.value.contains("Spark")).count() # Cuántas líneas contienen "Spark"?
...
20
Salimos
2.2 Monitorización¶
Cada driver program (lo veremos en el siguiente punto) tiene una Web UI, generalmente en el puerto 4040, que muestra información sobre tareas en ejecución, executers y uso de almacenamiento. Simplemente accediendo a http://<driver-node>:4040 en un navegador web para acceder a esta interfaz de usuario. La guía de seguimiento también describe otras opciones de seguimiento.
Por ejemplo, los ejemplos anteriores de shell interactiva nos da la siguiente info:
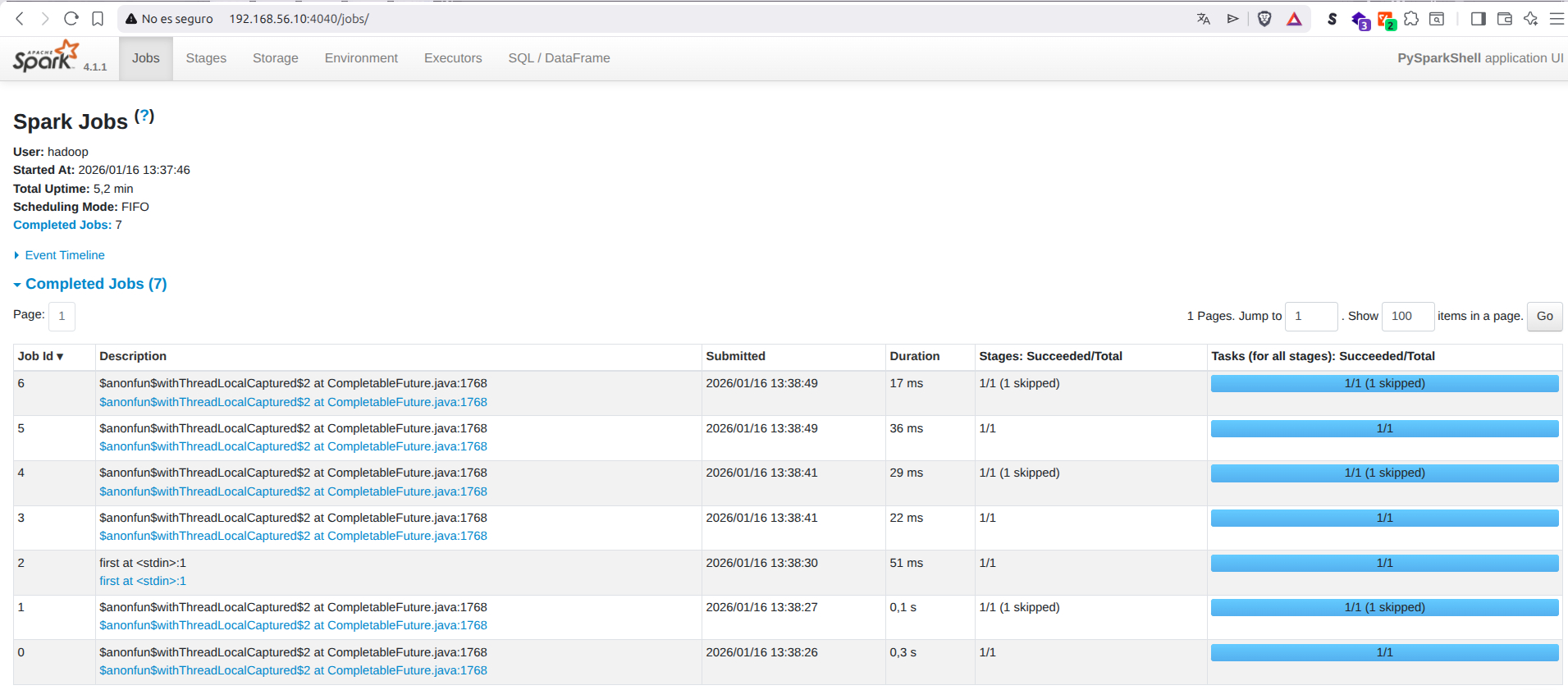

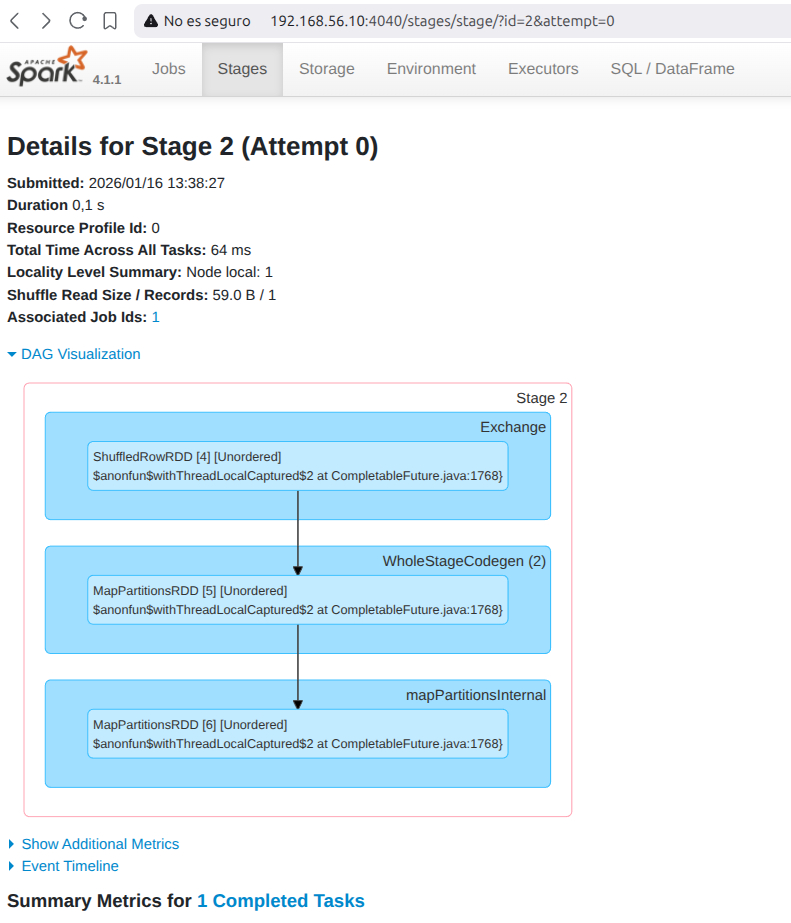
2.3 Aplicaciones autónomas¶
-
El script
spark-submitde Spark en el directorio$SPARK_HOME/binde Spark se utiliza para iniciar aplicaciones en un clúster. Puede utilizar todos los cluster managers con Spark a través de una interfaz uniforme para que no tengas que configurar tu aplicación para cada una de las configuraciones y situaciones de tu cluster. -
Este script se encarga de configurar el classpath con Spark y sus dependencias, y puede admitir diferentes configuraciones y modos de implementación de clústeres que admite Spark
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
donde:
--class: el punto de entrada de la aplicación (por ejemplo,org.apache.spark.examples.SparkPi)--master: la URL del master del clúster (por ejemplo, spark://23.195.26.187:7077)--deploy-mode: si queremos implementar un controlador en los nodos Workers (clúster) o localmente como un cliente externo (cliente) (predeterminado: cliente)--conf: argumento de configuración arbitraria de Spark en formato clave=valor. Para valores que contienen espacios, escriba “clave=valor” entre comillas (como se muestra). Se deben pasar varias configuraciones como argumentos separados. (por ejemplo,--conf <clave>=<valor> --conf <clave2>=<valor2>)application-jar: ruta a un jar incluido que incluye su aplicación y todas las dependencias. La URL debe ser visible globalmente dentro de su clúster, por ejemplo, una ruta hdfs:// o una ruta file:// que esté presente en todos los nodos.application-arguments: Argumentos pasados al método principal de su clase principal, si los hay
-
Para aplicaciones Python, simplemente pasamos un archivo .py en lugar de
application-jary agregamos los archivos Python .zip, .egg o .py a la ruta de búsqueda con --py-files. -
A continuación se muestran algunos ejemplos de opciones comunes:
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master "local[8]" \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster in cluster deploy mode
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
http://path/to/examples.jar \
1000
- Puedes ejecutar
spark-submit --helppara ver todas las opciones
2.4. Workers en aplicaciones autónomas¶
Para poder ejecutar cualquier aplicación autónoma, necesitamos, además del master, algún nodo worker funcionando
Para ello realizamos los siguientes pasos
- Iniciamos Spark en el master con el script
./sbin/start-master.shque se encuentra en$SPARK_HOME. En este caso indicamos que escuche arranque en0.0.0.0para que escuche sin necesidad de hacer resolución de nombres (Lo veremos cuando configuremos Spark en nuestro cluster)
#Desde $Spark_HOME
./sbin/start-master.sh -h 0.0.0.0
starting org.apache.spark.deploy.master.Master, logging to /opt/hadoop-3.4.2/spark-4.1.1/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-master.out
Recordamos que también se levanta un WebUI en el puerto 8080
- Iniciamos un Spark Worker. Este puede ser iniciado tanto en el mismo nodo del master, como en otro nodo. Hacemos uso del script
./sbin/start-worker.shque se encuentra en$SPARK_HOME. Ahora si, le pasamos la IP del master. En nuestro caso192.168.11.10
Voy a levantar 2, uno en el mismo nodo donde inicio Spark master y otro en el nodo 1 (Recuerda las IPs que tiene, que van a aparecer en la WebUI)
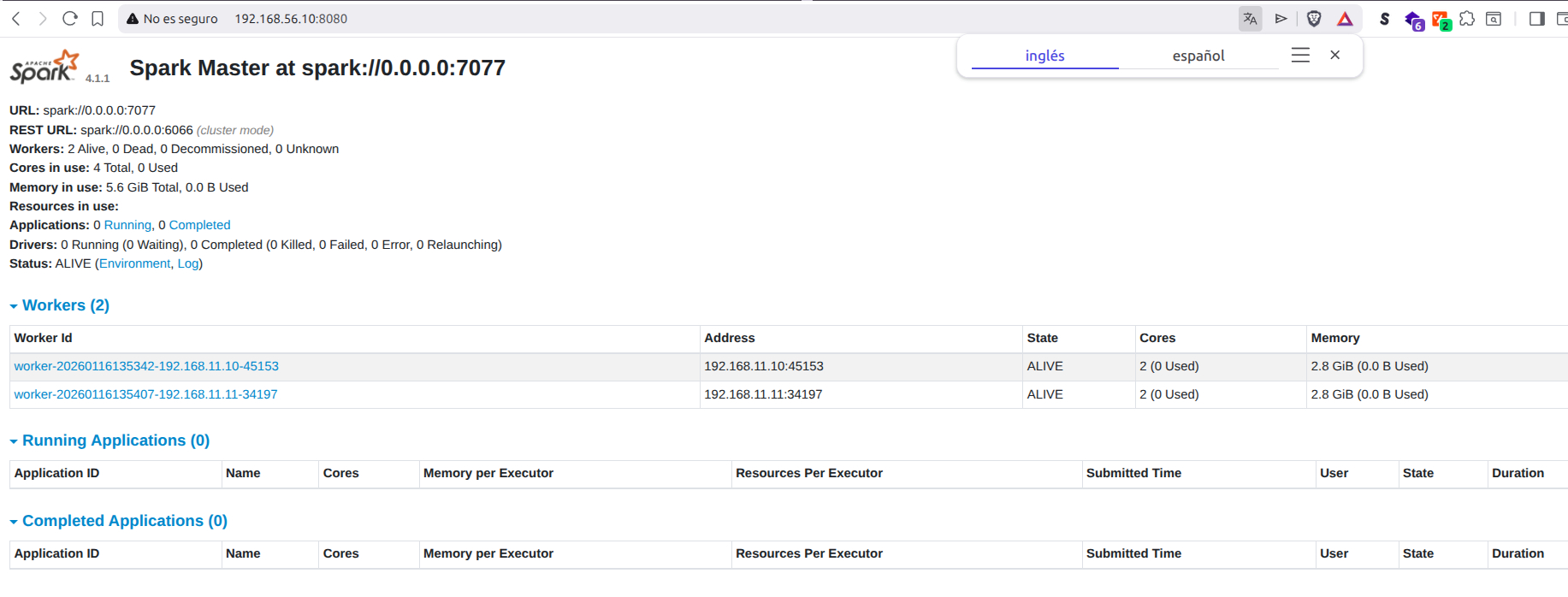
Ya podemos ejecutar aplicaciones autónomas con spark-submit
2.5 Ejemplo Aplicación autónoma¶
- Creamos un archivo
Ejemplo1_spark.pycon el siguiente código
import sys
from pyspark.sql import SparkSession #SparkSession es el punto de entrada para crear RDD, DataFrames y DataSets
spark = SparkSession.builder.appName("Ejemplo1_spark").getOrCreate() # Dar nombre a la app
logFile = "file:///opt/hadoop-3.4.2/spark-4.1.1/README.md" #"YOUR_SPARK_HOME/README.md" Should be some file on your system
logData = spark.read.text(logFile).cache() # Carga de datos en caché
numAs = logData.filter(logData.value.contains('a')).count() # Contamos el número de veces que aparece el carácter a
numBs = logData.filter(logData.value.contains('b')).count() # Contamos el número de veces que aparece el carácter b
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
logData.show()
spark.stop()
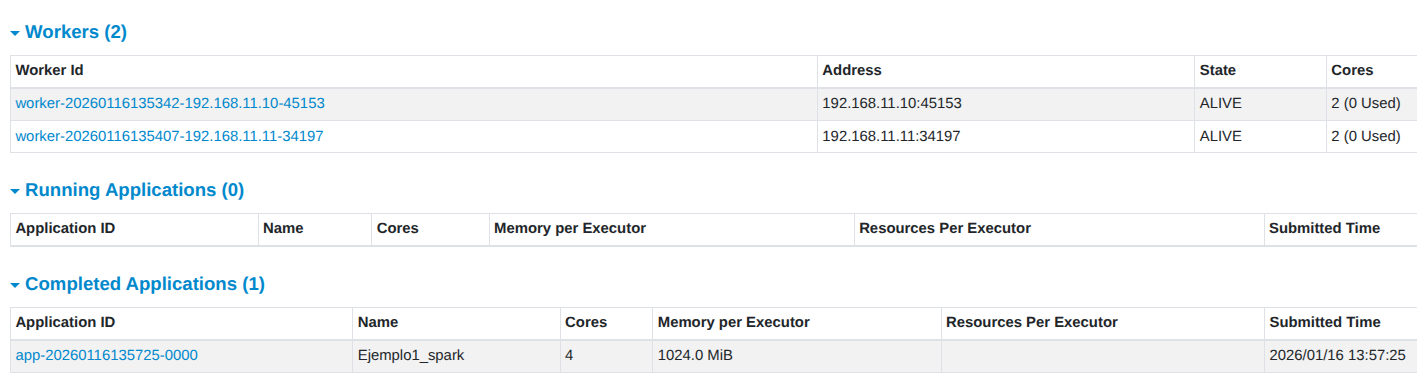
- Ejecutamos nuestra aplicación con
spark-submit. Recuerda que tienes que tener al menos arrancado spark master y al menos un worker
26/01/16 13:57:33 INFO TaskSchedulerImpl: Killing all running tasks in stage 7: Stage finished
26/01/16 13:57:33 INFO DAGScheduler: Job 5 finished: showString at NativeMethodAccessorImpl.java:0, took 67.672718 ms
26/01/16 13:57:33 INFO CodeGenerator: Code generated in 7.638948 ms
+--------------------+
| value|
+--------------------+
| # Apache Spark|
| |
|Spark is a unifie...|
|high-level APIs i...|
|supports general ...|
|rich set of highe...|
|pandas API on Spa...|
|and Structured St...|
| |
|- Official versio...|
|- Development ver...|
| |
|[
- Apagamos Spark master y los workers
# Desde $SPARK_HOME
# En el nodo master
./sbin/stop-master.sh
# En el nodo worker que hayamos iniciado anteriormente
./sbin/stop-worker.sh
3. Cluster Spark y Spark Connect¶
3.1 Componentes¶
Las aplicaciones Spark se ejecutan como conjuntos independientes de procesos en un clúster, coordinados por el objeto SparkContext en su programa principal (llamado driver program).
Específicamente, para ejecutarse en un clúster, SparkContext puede conectarse a varios tipos de administradores de clústeres (ya sea el administrador de clústeres independiente de Spark, Mesos, YARN o Kubernetes), que asignan recursos entre aplicaciones. Una vez conectado, Spark adquiere executors en los nodos del clúster, que son procesos que ejecutan cálculos y almacenan datos para su aplicación. A continuación, envía el código de su aplicación (definido por archivos JAR o Python pasados a SparkContext) a los executors. Finalmente, SparkContext envía tareas a los executors para que las ejecuten.
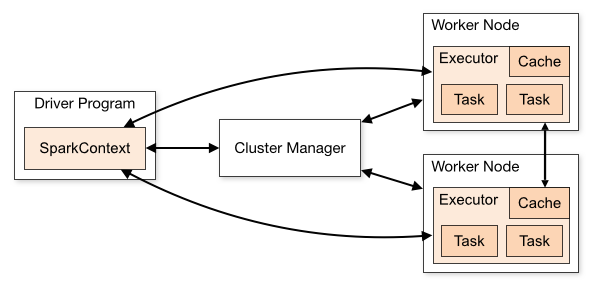
Hay varias cosas útiles a tener en cuenta sobre esta arquitectura:
- Cada aplicación tiene sus propios procesos executors, que permanecen activos durante toda la aplicación y ejecutan tareas en múltiples subprocesos. Esto tiene la ventaja de aislar las aplicaciones entre sí, tanto en el lado de la programación (cada controlador programa sus propias tareas) como en el lado del executor (las tareas de diferentes aplicaciones se ejecutan en diferentes JVM). Sin embargo, también significa que los datos no se pueden compartir entre diferentes aplicaciones Spark (instancias de SparkContext) sin escribirlos en un sistema de almacenamiento externo.
- Spark es independiente del cluster manager subyacente. Siempre que pueda adquirir procesos executors y estos se comuniquen entre sí, es relativamente fácil ejecutarlo incluso en un cluster manager que también admita otras aplicaciones (por ejemplo, Mesos/YARN/Kubernetes).
- El driver program debe escuchar y aceptar conexiones entrantes de sus ejecutores durante toda su vida útil (por ejemplo, consulte spark.driver.port en la sección de configuración de red). Como tal, el driver program debe ser direccionable en red desde los nodos workers.
- Debido a que el driver controla las tareas en el clúster, debe ejecutarse cerca de los nodos worker, preferiblemente en la misma red de área local. Si desea enviar solicitudes al clúster de forma remota, es mejor abrir un RPC para el controlador y hacer que envíe operaciones desde cerca que ejecutar un controlador lejos de los nodos worker.
3.2 Tipos de cluster manager¶
Actualmente, el sistema admite varios administradores de clústeres:
- Standalone: Un simple cluster manager incluido con Spark que facilita la configuración de un clúster.
- Hadoop YARN: el resource manager en Hadoop 3.
- Kubernetes: un sistema de código abierto para automatizar la implementación, el escalado y la gestión de aplicaciones en contenedores.
3.3 Job Scheduling¶
Spark brinda control sobre la asignación de recursos tanto entre aplicaciones (en el nivel del cluster manager) como dentro de las aplicaciones (si se realizan múltiples cálculos en el mismo SparkContext). El job scheduling overview describe esto con más detalle.
3.4 Configuración del cluster "Standalone"¶
-
Sigue los pasos del punto anterior de Instalación para cada uno de los nodos del cluster
-
Sólo en el nodo donde vas a lanzar Spark master realiza las siguiente configuraciones
-
Entramos en
conf/spark-env.shy añadimos la IP del master a la variable de entornoSPARK_MASTER_HOST. En nuestro caso192.168.11.10:
- Entramos en
conf/workersy añadimos los nodos que queremos que se inicien como workers:
#localhost # Comentamos localhost si no queremos que se inicie un worker en el master
nodo1
nodo2
nodo3
Podrías iniciar tantos workers como quieras en los nodos. Sólo tienes que repetir los nodos. Comentamos localhost si no queremos que se inicie un worker en el master (nuestro caso)
- Desde el nodo Spark master, iniciamos:
- Arrancamos Spark Connect
Para habilitar la arquitectura moderna desacoplada (permitir conexiones desde IDEs remotos), debemos levantar el servicio Connect.
Ahora tu clúster escucha peticiones en el puerto 15002.- Desde el nodo Spark master, iniciamos los workers (OJO, workers en plural)

Hadoop y Spark
No olvides tener iniciado Apache Hadoop start-dfs.sh
- Apagamos Spark master y los workers
# Desde $SPARK_HOME en master
cd $SPARK_HOME
./sbin/stop-connect-server.sh
./sbin/stop-master.sh
./sbin/stop-workers.sh
4. Ejemplo 1: WordCount en HDFS¶
Vamos a validar la integración completa (Spark + HDFS) ejecutando el clásico conteo de palabras sobre el texto de "El Quijote".
- Preparar datos en HDFS
Asegúrate de que Hadoop está arrancado (start-dfs.sh).
# Dentro de Hadoop (master)
sudo mkdir -p /opt/spark/ejemplos
sudo chown -R hadoop:hadoop /opt/spark
cd /opt/spark/ejemplos
# Descargar libro
wget https://gist.githubusercontent.com/jaimerabasco/cb528c32b4c4092e6a0763d8b6bc25c0/raw/54b30a89f3b608d0837bd1fc10bc31e64ba4c7c8/El_Quijote.txt
# Subir a HDFS
hdfs dfs -mkdir -p /bda/spark/ejemplos
hdfs dfs -put El_Quijote.txt /bda/spark/ejemplos/
- Creamos el directorio donde guardaremos el script de ejemplo wordcount
- Creamos en ese directorio el script de ejemplo en Python wordcount
from pyspark.sql import SparkSession
if __name__ == "__main__":
# Inicializar sesión
spark = SparkSession.builder.appName("HDFS_WordCount").getOrCreate()
# 1. Leer de HDFS
input_file = "hdfs://cluster-bda:9000/bda/spark/ejemplos/El_Quijote.txt"
print(f"--- Leyendo de: {input_file} ---")
df = spark.read.text(input_file)
# 2. Transformación: Contar líneas que contienen "Sancho"
sancho_lines = df.filter(df.value.contains("Sancho"))
count = sancho_lines.count()
print(f"--- Líneas con 'Sancho': {count} ---")
# 3. Escribir resultado en HDFS (CSV)
output_path = "hdfs://cluster-bda:9000/bda/spark/ejemplos/salida_sancho"
print(f"--- Escribiendo en: {output_path} ---")
sancho_lines.write.mode("overwrite").csv(output_path)
spark.stop()
- Asegurate de que Spark master y los workers están arrancados
cd $SPARK_HOME
./sbin/start-master.sh
./sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_2.13:4.1.1
./sbin/start-workers.sh
- Ejecutar el script (
spark-submit)
Lanzamos el script de ejemplo en Python incluido en Spark, apuntando al Master del clúster.
spark-submit \
--master spark://192.168.11.10:7077 \
--name "Quijote-WordCount" \
/opt/spark/ejemplos/wordcount.py \
hdfs://cluster-bda:9000/bda/spark/ejemplos/El_Quijote.txt
- Monitorización. Mientras se ejecuta:
- Vamos a la Web UI (
http://192.168.56.10:8080). - Verás la aplicación
Quijote-WordCounten estado RUNNING. - Al finalizar, verás el output en tu consola con el conteo de palabras.
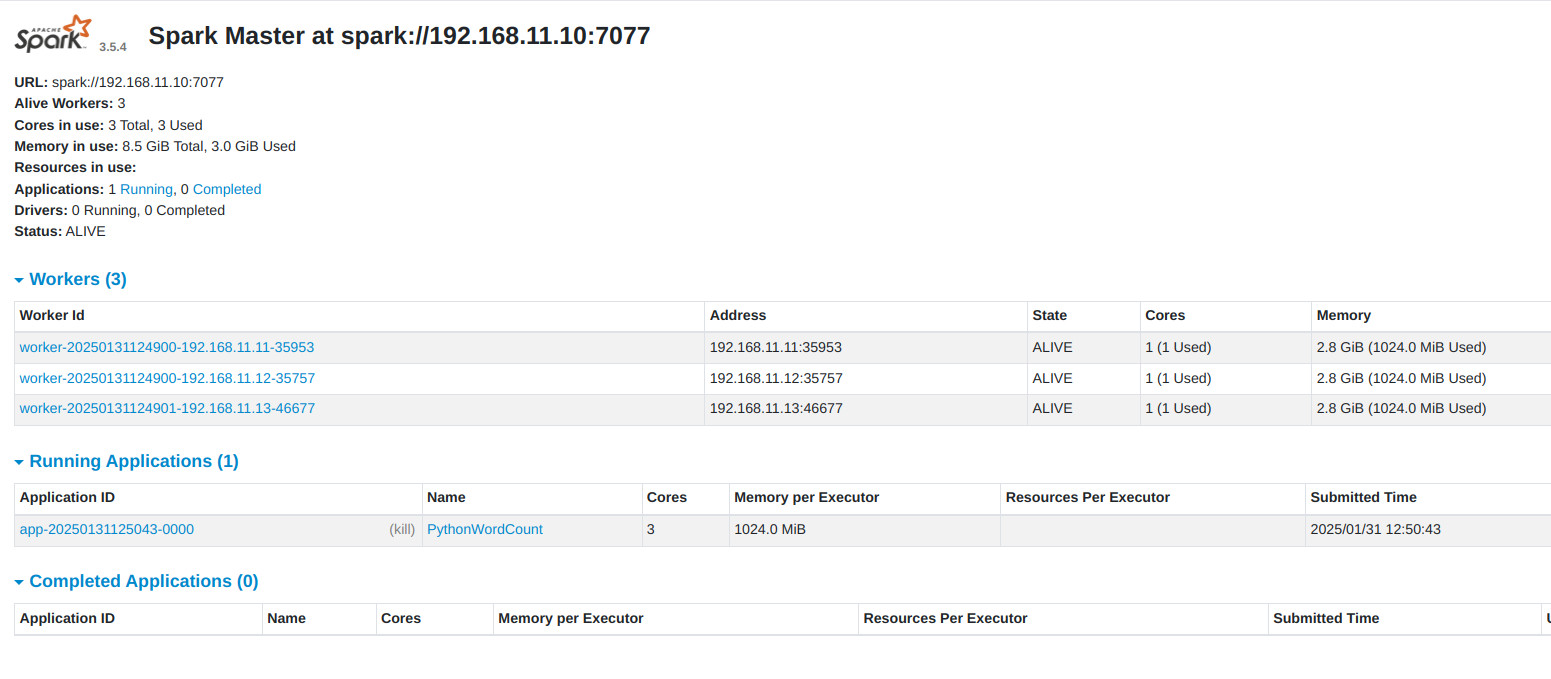
5. Ejemplo2: Desarrollo Remoto con VS Code y Spark Connect¶
Una de las grandes ventajas de Spark 4.0 es poder desarrollar desde tu IDE favorito en tu ordenador (Host) y ejecutar el código en el clúster remoto (VMs), sin instalar Java ni Hadoop en tu local.
5.1 Requisitos Previos (En Host)¶
Solo necesitas Python.
- Crea una carpeta para el proyecto y accede a ella desde VS Code:
- Crea un entorno virtual y activa las librerías de cliente:
python -m venv venv
source venv/bin/activate # O venv\Scripts\activate en Windows
pip install pyspark-connect grpcio-status
```
### 5.2 Requisitos Previos (En Clúster)
1. Preparar datos en HDFS (**sólo si no lo has hecho ya en el ejemplo anterior**)
Asegúrate de que Hadoop está arrancado (`start-dfs.sh`).
```bash
# Dentro de Hadoop (master)
sudo mkdir -p /opt/spark/ejemplos
sudo chown -R hadoop:hadoop /opt/spark
cd /opt/spark/ejemplos
# Descargar libro
wget https://gist.githubusercontent.com/jaimerabasco/cb528c32b4c4092e6a0763d8b6bc25c0/raw/54b30a89f3b608d0837bd1fc10bc31e64ba4c7c8/El_Quijote.txt
# Subir a HDFS
hdfs dfs -mkdir -p /bda/spark/ejemplos
hdfs dfs -put El_Quijote.txt /bda/spark/ejemplos/
5.3 El script en VS Code¶
Crea un archivo remote_wordcount.py en tu VS Code.
Nota: Fíjate que usamos .remote() en lugar de .master().
from pyspark.sql import SparkSession
# Conectamos al servicio Spark Connect que levantamos en el puerto 15002
# Sustituye 192.168.56.10 por la IP de conexión a tu nodo Master desde el host
spark = SparkSession.builder.remote("sc://192.168.56.10:15002").getOrCreate()
print("--- Conectado a Spark Cluster versión: ", spark.version)
# Leemos de HDFS (El clúster sabe dónde está HDFS, nosotros solo damos la ruta)
# Nota: Usamos la dirección de HDFS tal como la ve el clúster
input_path = "hdfs://cluster-bda:9000/bda/spark/ejemplos/El_Quijote.txt"
print(f"--- Procesando archivo: {input_path}")
df = spark.read.text(input_path)
# Transformación: Contar líneas que contienen "Sancho"
sancho_lines = df.filter(df.value.contains("Sancho"))
count = sancho_lines.count()
#Escribir resultado en HDFS (CSV)
output_path = "hdfs://cluster-bda:9000/bda/spark/ejemplos/salida_sancho_remote"
print(f"--- Resultado: Sancho aparece en {count} líneas ---")
sancho_lines.write.mode("overwrite").csv(output_path)
spark.stop()
5.4 Levantamos Hadoop y Spark¶
Nos aseguramos de que Hadoop y el cluster de Spark están arrancados
# Arrancamos Hadoop
start-dfs.sh
# Arrancamos Spark Master y Workers
cd $SPARK_HOME
./sbin/start-master.sh
./sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_2.13:4.1.1
./sbin/start-workers.sh
5.5 Ejecutamos el script desde VS Code¶
Tienes dos formas de lanzar este código desde tu ordenador anfitrión.
Opción A: Desde la Terminal (Recomendada)¶
Es la forma más directa y te asegura ver todos los logs sin depender de configuraciones del editor. Asegúrate de tener tu entorno virtual activado.
# 1. Activa el entorno (si no lo está ya)
source venv/bin/activate # En Windows: venv\Scripts\activate
# 2. Ejecuta el script
python remote_wordcount.py
Opción B: Desde VS Code (Botón Play)¶
Si prefieres ejecutarlo directamente desde el editor:
- Instala la extensión Python (de Microsoft) en VS Code.
- Abre el archivo
remote_wordcount.py. - Abajo a la derecha, asegúrate de seleccionar el Intérprete de Python que está dentro de tu carpeta
venv(VS Code te preguntará o puedes hacer click para cambiarlo). - Pulsa el botón ▷ (Play) arriba a la derecha.
5.6 Resultado Esperado¶
Independientemente del método, verás en la consola de tu ordenador local algo similar a:
--- Conectado a Spark Cluster versión: 4.1.1
--- Procesando archivo: hdfs://cluster-bda:9000/bda/spark/ejemplos/El_Quijote.txt
--- Resultado: Sancho aparece en 2123 líneas ---
Comprobamos en HDFS que se ha creado la salida:
5.7 Monitorización¶
Una vez ejecutado, nos daremos cuenta al ir a la Web UI de Spark (http://192.168.56.10:8080) que no aparece la app ejecutada.
Es un comportamiento normal debido a la arquitectura de Spark Connect. La razón por la que no ves una "nueva aplicación" en la Web UI del Master (puerto 8080) cada vez que ejecutas tu script es la siguiente:
-
El Servidor es la Aplicación, no tu Script. Cuando utilizamos Spark Connect, el flujo es distinto al de un
spark-submittradicional. Spark Connect Server es un proceso persistente que hemos "levantado" previamente gracias astart-connect-server.sh). -
Tu cliente (Python): Al usar
.remote("sc://..."), nuestro script no envía la aplicación entera al cluster. Solo envía "instrucciones" (planes lógicos) al servidor de Spark Connect. El servidor recibe esas instrucciones y las ejecuta dentro de su propia sesión de Spark ya existente.
Dónde ver la ejecución de los trabajos (Jobs)¶
Aunque no aparezca como una aplicación nueva en el puerto 8080, sí puedes ver los Jobs, Stages y tareas de tu script, pero no en el Master, sino en la UI del Driver del Servidor:
-
Puerto 4040: Por defecto, el servidor de Spark Connect levanta su propia interfaz de monitorización en el puerto 4040 (o 4041, 4042 si el 4040 estaba ocupado) de la máquina donde iniciaste el servicio
-
Entra en http://192.168.56.10:4040/connect/ mientras tu script se está ejecutando o justo después, y ahí veremos el detalle de los Jobs generados por
df.filter(...) ycount().
Diferencias clave para tu flujo de trabajo¶
-
Si usas Spark Connect: El cluster se comporta como una base de datos a la que te conectas. La "app" es el servidor y siempre está encendida. Es ideal para notebooks e IDEs.
-
Si quieres ver una App independiente: Deberías ejecutar tu código usando
spark-submitdesde la consola del cluster o configurar tu script para usar un Master directo (.master("spark://192.168.56.10:7077"), como hemos hecho anteriormente en el ejemplo 1) en lugar de.remote().

5.8 Apagamos Spark y Hadoop¶
Nos aseguramos de apagar todo correctamente